
5 偏倚检测
在整个研究过程中都可能会出现偏差。察觉并预防偏差的出现将会有很大的帮助。一些研究者建议对科学文献中的任何结论都持怀疑态度。例如,科学哲学家Deborah Mayo(2018)写道:“面对最新的统计学新闻时,你的第一个问题应该是:这些结果是由于选择性报告、选择性挑选或者其他类似伎俩导致的吗?”。如果你在下一次参加的科学会议上问这个问题,可能会让自己不那么受欢迎,但忽视研究者或多或少有意地在他们的结论中引入偏差这一事实是非常幼稚的。
在引入偏差到科学研究的行为中,最极端的形式就是研究不当行为,包括伪造数据或结果、更改或剔除数据或结果,使得研究记录不能准确反映研究发现。例如,Andrew Wakefield在1998年撰写了一篇造假文章,声称麻疹、流行性腮腺炎和风疹(MMR)疫苗与自闭症有关。这篇文章在破坏了一些公众对疫苗的信任后,才终于在2010年被撤销。另一个例子来自心理学领域,James Vicary进行的一项关于潜意识启示的研究。他声称,在电影院屏幕上闪现低于意识阈限的词语”吃爆米花”和”喝可乐”,爆米花和可乐的销售额分别增长了57.5%、18.1%. 然而,人们后来发现Vicary很可能进行了学术欺诈,因为没有任何证据表明确实进行过这样一项研究(Rogers, 1992)。Retraction-Watch网站维护着一个数据库,跟踪记录了科学论文被撤销的原因,包括数据造假。虽然实际中数据造假的发生频率未知,但正如研究诚信章节中所讨论的那样,我们应该可以预计至少有一小部分科学家对数据和结果进行过一次以上的捏造和篡改。
另一类错误是统计报告错误,包括报告错误的自由度、将p=0.056报告为p<0.05等(Nuijten et al., 2015)。虽然我们应该尽力避免错误,但每个人都会犯错,而随着数据和代码共享变得越来越普遍,能够更容易地检测出其他研究人员工作中的错误。正如Dorothy Bishop(2018)所写的:“随着开放科学越来越成为常态,我们将发现每个人会犯错误。科学家的声誉将不取决于他们的研究中是否存在缺陷,而是取决于在发现这些缺陷时他们如何回应。
Statcheck是一款自动从文章中提取统计数据并重新计算其p值的软件,统计数据需要按照美国心理学协会(APA)的指导方针报告。它会检查报告的统计数据内部是否一致:在给定的检验统计数据和自由度下,报告的p值是否准确?如果准确,那么犯错的可能性就较小(但这并不适用于逻辑错误!),如果不准确,你应该检查统计检验中的所有信息是否准确。Statcheck不是完美的,它会导致第一类错误,即当实际上没有错误时,它将某些内容标记为错误,但它是一个易于使用的工具,可以在投稿之前用来检查文章。
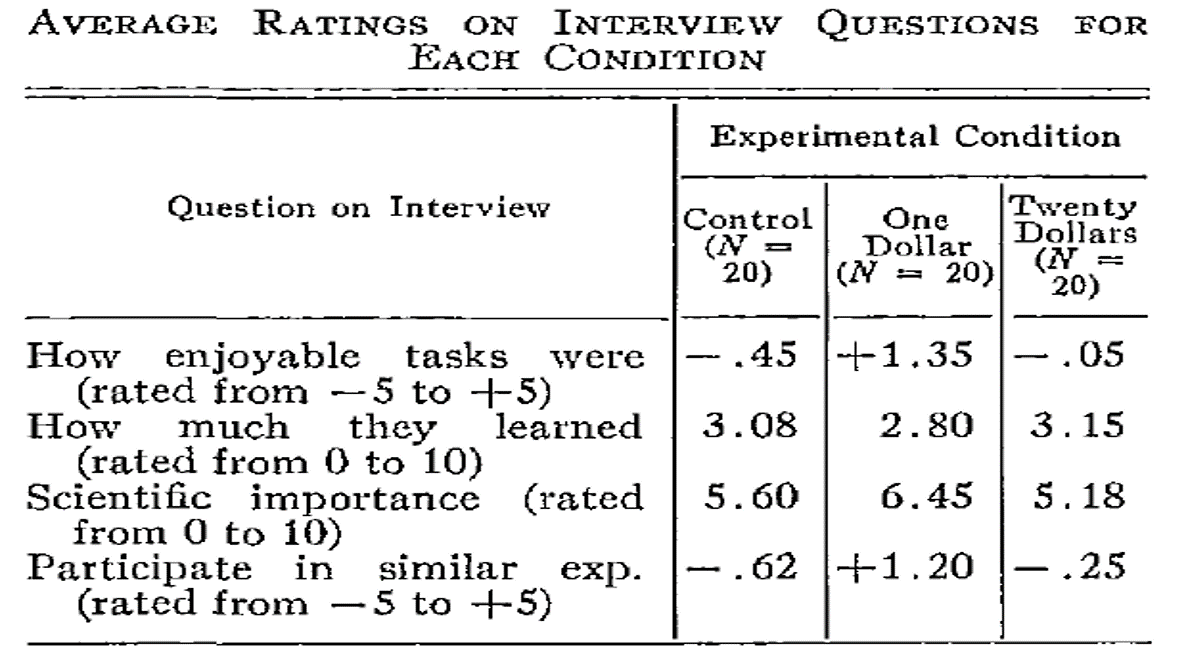
有些数据的不一致性不太容易自动检测,但可以手动识别。例如,Brown & Heathers (2017) 表明,许多论文报告的平均值在样本量给定的情况下不可能出现(称为GRIM test)。例如,Matti Heino在一篇博客文章blog post中注意到,Festinger和Carlsmith的经典研究表格中报告的三个平均值在数学上是不可能的。对于每个条件20个观测值和-5到5的标度,所有平均值应该以1/20的倍数或0.05结尾。以X.X8或X.X2结尾的三个平均值与报告的样本量和标度不一致。当然,这种不一致性可能是由于未报告某些问题的数据缺失引起的,但GRIM测试也已被用于揭示科学不端行为scientific misconduct。
5.1 出版偏见
出版偏见是科学面临的最大挑战之一。出版偏见指有选择地提交和出版科学研究,通常基于结果是否有”统计显著”。科学文献被这些统计显著的结果所主导。同时,我们知道,研究人员进行的许多研究并没有产生显著的结果。当科学家们只能获得显著的结果,而不能获得所有的结果时,他们就缺乏对某一假设的证据的完整概述。在极端情况下,选择性报告会导致这样一种情况:在已发表的文献中,有数百个统计显著的结果,但因为有更多非显著的研究没有被分享,学术研究没有真正的效果。这就是所谓的文件抽屉问题,即非显著结果被藏在文件抽屉里(或者现在是电脑上的文件夹),不为科学界所了解。每个科学家都应该努力解决出版偏见,因为只要科学家不分享他们的所有结果,就很难了解什么是可能的事实,而且正如Greenwald(1975)所指出的,这是一种违反道德的行为。

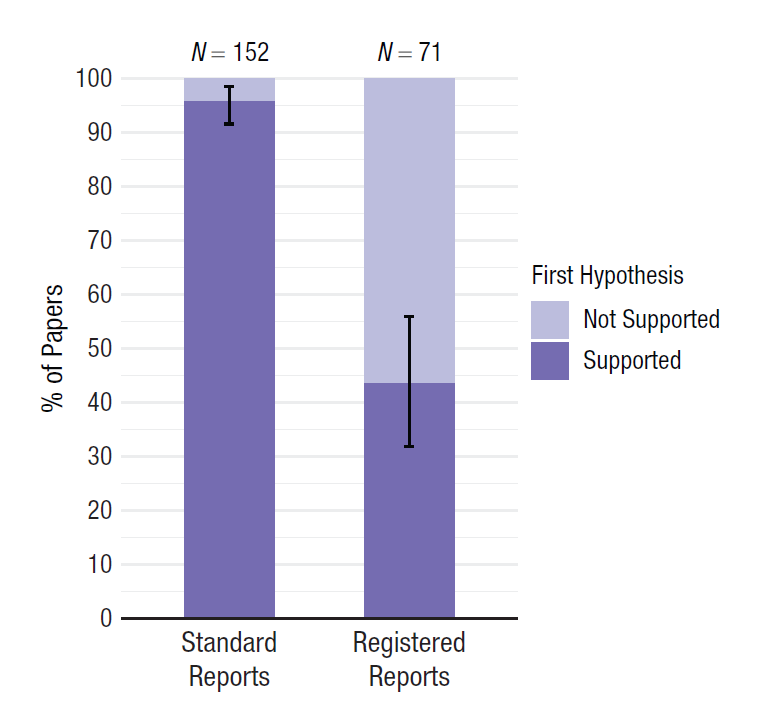
只有将你的所有研究成果提供给科学家同行,无论主要假设检验的p值是多少,才能解决出版偏差的问题。注册报告是消除出版偏见的一种方式,因为这种类型的科学文章在收集数据之前,会根据介绍、方法和统计分析计划进行审查(Chambers & Tzavella, 2022; Nosek & Lakens, 2014)。经过该领域专家的同行评审,他们可能会对实验设计和数据分析方法提出改进意见。文章可以获准 “原则上接收”,这意味着只要遵循研究计划,无论结果如何,文章就会被发表。这应该有利于非显著性结果的发表,如图所示 Figure 5.4 ,对首次发表的心理学注册报告的分析显示,71篇文章中的31篇(44%)观察到了显著结果,相比之下,同期发表的152篇标准科学文章中的则有146篇(96%)观察到了显著结果(Scheel et al., 2021) 。
在过去,注册报告并不存在,科学家也不会分享所有的结果(Franco et al., 2014; Greenwald, 1975; Sterling, 1959),因此,我们必须努力检测出版偏差对我们准确评估文献能力的影响程度。元分析应该始终仔细检查出版偏差对元分析效应量估计的影响–尽管在1990年至2017年间发表在Psychological Bulletin上的元分析中,估计只有57%文章说他们评估了出版偏差(Polanin et al., 2020)。最近发表在教育研究上的元分析中,82%使用了偏差检测测试,但所使用的方法通常与最先进的方法相差甚远(Ropovik et al., 2021)。目前已经开发了几种检验出版偏差的技术,但这仍然是一个非常活跃的研究领域。所有的技术都是基于特定的假设,你在应用检验测试之前应该考虑这些假设(Carter et al., 2019)。目前并没有”妙方”:这些技术都不能纠正出版偏差。它们都不能肯定地告诉你修正了出版偏差后真正的元分析效应量是多少。这些方法能做到最好的事情就是在特定条件下检测由特定机制引起的出版偏差。出版偏差可以被检测出来,但它不能被修正。
在似然一章中,我们看到混合结果是可以预期的,而且可以成为替代性假设的有力证据。不仅混合结果是可以预期的,而且可以专门观察到统计显著的结果,尤其是在统计检验力较低的情况下,这非常令人惊讶。以通常使用的80%的统计检验力下限,我们可以预期在有真实效果的情况下,五项研究中会有一项是不显著的结果。一些研究人员指出,在一组研究中,不发现混合结果非常不可能(换言之,“好得不真实”)(Francis, 2014; Schimmack, 2012) 。我们对真实的研究模式没有很好的感受,因为我们持续接触到的科学文献并不反映现实情况。科学文献中几乎所有的多项研究论文都只呈现统计显著的结果,尽管这不可能。
我们开发了计算二项式概率的在线Shiny应用程序。如果你滚动到页面底部,在”二项式概率”中找到”多项显著性发现”,给定一个关于检验力的特定假设,应用程序便可显示概率。Francis (2014) 使用这些二项式概率来计算2009年至2012年期间发表在Psychological Science杂志上44篇包含四个或更多研究的文章的过度显著结果(Ioannidis & Trikalinos, 2007)。他发现,对于这些文章中的36篇,考虑到根据观察到的效应量计算的平均检验力,观察到四个显著性结果的可能性小于10%。鉴于他选择的α水平为0.10,这个二项式概率是一个假设检验,并允许声称(在10%的α水平下):只要统计显著的结果数量的二项式概率低于10%,数据是出乎意料的,由此我们可以拒绝”这是一组没有引入偏见的研究”这一假设。换句话说,不太可能观察到这么多显著的结果,这表明出版偏差或其他选择效应在这些文章中发挥了作用。
这44篇文章中,有一篇由我自己共同撰写(Jostmann et al., 2009)。那时,我对统计检验力和出版偏见知之甚少,被指责为进行不正当学术行为令我倍感压力。然而,这些指责是正确的–我们有选择地报告了结果,有选择地报告了有效的分析。由于几乎没有接受过这方面的培训,我们对自己进行了教育,并将一项未发表的研究上传到网站psychfiledrawer.org(该网站已不存在),以分享我们的”文件抽屉”。若干年后,当Many Labs 3将我们发表的一项研究纳入他们复制的研究集时,我们提供了帮助(Ebersole et al., 2016)。当观察到一个无效的结果时,我们写道:“我们不得不得出结论,实际上没有可靠的证据证明这种效应”(Jostmann et al., 2016)。我希望这些教育材料能够避免其他人像我们一样出丑。
5.2 元分析中的偏差检测
检测发表偏差的新方法不断被开发出来,而旧的方法则变得过时(尽管你仍然可以看到它们出现在元分析中)。一种过时的方法被称为故障安全N(fail-safe N)。其想法是计算在观察到的元分析效应量估计值不再与0有统计学差异之前,在文件抽屉中需要有多少个不显着的结果。这种方法已不再被推荐,Becker(2005)写道:“鉴于现在有其他处理发表偏倚的方法,应该放弃故障安全N方法,而采用其他更富有信息量的分析方法。目前,故障安全N的唯一用途是作为一种工具来识别那些不是最先进的元分析。
在我们解释第二种方法(修剪和填充,Trim-and-Fill)之前,有必要解释一下可视化元分析的一种常见方法,即漏斗图。在漏斗图中,X轴用于绘制每个研究的效应量,Y轴用于绘制每个效应量的”精确度”(通常是每个效应量估计的标准误差)。一项研究中的观察数越多,效应量的估计就越精确,标准误差就越小,因此该研究在漏斗图中的位置就越高。一个无限精确的研究(标准误差为0)将位于y轴的顶端。
下面的代码模拟了nsims研究的荟萃分析,并存储了检查偏差检测所需的所有结果。在代码的第一部分中,模拟了所需方向上具有统计显着性的结果,在第二部分中生成了空结果。 如pub.bias所示,该代码会生成一定比例的重要结果——当设置为 11时,所有结果都是重要的。 在下面的代码中,pub.bias设置为 0.05。 因为模拟中没有真正的效果(m1和m2相等,所以组间没有差异),唯一应该预期的显着结果是 5% 的误报。最后,执行元分析,输出结果,并创建漏斗图。
library(metafor)
library(truncnorm)
nsims <- 100 # number of simulated experiments
pub.bias <- 0.05 # set percentage of significant results in the literature
m1 <- 0 # too large effects will make non-significant results extremely rare
sd1 <- 1
m2 <- 0
sd2 <- 1
metadata.sig <- data.frame(m1 = NA, m2 = NA, sd1 = NA, sd2 = NA,
n1 = NA, n2 = NA, pvalues = NA, pcurve = NA)
metadata.nonsig <- data.frame(m1 = NA, m2 = NA, sd1 = NA, sd2 = NA,
n1 = NA, n2 = NA, pvalues = NA, pcurve = NA)
# simulate significant effects in the expected direction
if(pub.bias > 0){
for (i in 1:nsims*pub.bias) { # for each simulated experiment
p <- 1 # reset p to 1
n <- round(truncnorm::rtruncnorm(1, 20, 1000, 100, 100)) # n based on truncated normal
while (p > 0.025) { # continue simulating as along as p is not significant
x <- rnorm(n = n, mean = m1, sd = sd1)
y <- rnorm(n = n, mean = m2, sd = sd2)
p <- t.test(x, y, alternative = "greater", var.equal = TRUE)$p.value
}
metadata.sig[i, 1] <- mean(x)
metadata.sig[i, 2] <- mean(y)
metadata.sig[i, 3] <- sd(x)
metadata.sig[i, 4] <- sd(y)
metadata.sig[i, 5] <- n
metadata.sig[i, 6] <- n
out <- t.test(x, y, var.equal = TRUE)
metadata.sig[i, 7] <- out$p.value
metadata.sig[i, 8] <- paste0("t(", out$parameter, ")=", out$statistic)
}}
# simulate non-significant effects (two-sided)
if(pub.bias < 1){
for (i in 1:nsims*(1-pub.bias)) { # for each simulated experiment
p <- 0 # reset p to 1
n <- round(truncnorm::rtruncnorm(1, 20, 1000, 100, 100))
while (p < 0.05) { # continue simulating as along as p is significant
x <- rnorm(n = n, mean = m1, sd = sd1) # produce simulated participants
y <- rnorm(n = n, mean = m2, sd = sd2) # produce simulated participants
p <- t.test(x, y, var.equal = TRUE)$p.value
}
metadata.nonsig[i, 1] <- mean(x)
metadata.nonsig[i, 2] <- mean(y)
metadata.nonsig[i, 3] <- sd(x)
metadata.nonsig[i, 4] <- sd(y)
metadata.nonsig[i, 5] <- n
metadata.nonsig[i, 6] <- n
out <- t.test(x, y, var.equal = TRUE)
metadata.nonsig[i, 7] <- out$p.value
metadata.nonsig[i, 8] <- paste0("t(", out$parameter, ")=", out$statistic)
}}
# Combine significant and non-significant effects
metadata <- rbind(metadata.nonsig, metadata.sig)
# Use escalc to compute effect sizes
metadata <- escalc(n1i = n1, n2i = n2, m1i = m1, m2i = m2, sd1i = sd1,
sd2i = sd2, measure = "SMD", data = metadata[complete.cases(metadata),])
# add se for PET-PEESE analysis
metadata$sei <- sqrt(metadata$vi)
#Perform meta-analysis
result <- metafor::rma(yi, vi, data = metadata)
result
# Print a Funnel Plot
metafor::funnel(result, level = 0.95, refline = 0)
abline(v = result$b[1], lty = "dashed") # vertical line at meta-analytic ES
points(x = result$b[1], y = 0, cex = 1.5, pch = 17) # add point让我们先看看无偏见的研究是什么样子的,运行代码,保持pub.bias在0.05,这样只有5%的第一类错误进入科学文献。
Loading required package: MatrixLoading required package: metadatLoading required package: numDeriv
Loading the 'metafor' package (version 4.4-0). For an
introduction to the package please type: help(metafor)
Random-Effects Model (k = 100; tau^2 estimator: REML)
tau^2 (estimated amount of total heterogeneity): 0.0000 (SE = 0.0018)
tau (square root of estimated tau^2 value): 0.0006
I^2 (total heterogeneity / total variability): 0.00%
H^2 (total variability / sampling variability): 1.00
Test for Heterogeneity:
Q(df = 99) = 91.7310, p-val = 0.6851
Model Results:
estimate se zval pval ci.lb ci.ub
-0.0021 0.0121 -0.1775 0.8591 -0.0258 0.0215
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1当我们检查元分析的结果时,我们看到元分析中有100个研究(k = 100),并且没有统计意义上的异质性(p = 0.69,这并不令人惊讶,因为我们在编程时将模拟的真实效应量设定为0,并且没有效应量的异质性)。我们也得到了元的结果。元分析的估计值是d=-0.002,非常接近于0(应该如此,因为真实的效应量确实是0)。这个估计值的标准误差是0.012。有了100项研究,我们就有了对真实效应量的非常准确的估计。对d=0的检验的Z值是-0.177,而这个检验的p值是0.86。我们不能拒绝真实效应量为0的假设。效应量估计值的置信区间(-0.026, 0.021)包括0。
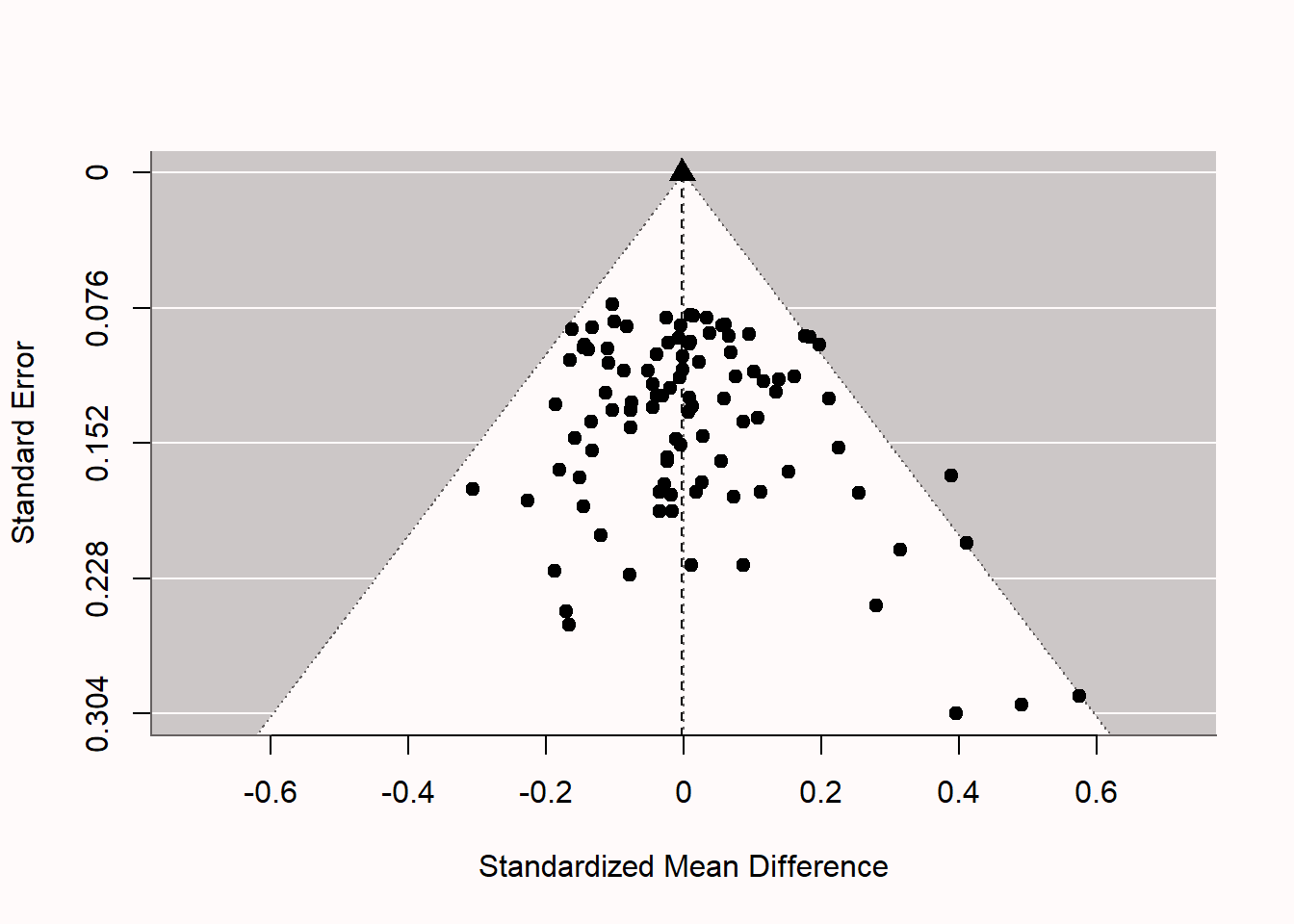
如果我们检查图中的漏斗图 Figure 5.5,我们看到每项研究都用一个点来表示。样本量越大,在图中越高,样本量越小,在图中越低。白色的金字塔代表一项研究不具有统计学显著性的区域,因为观察到的效应量(X轴)与0相差不大,以至于观察到的效应量周围的置信区间会排除0。标准误差越小,置信区间就越窄,效应量就越小,以达到统计学上的意义。同时,标准误差越小,效应量就越接近真实的效应量,所以我们就越不可能看到远离0的效应。我们看到只有少数研究(确切地说,是五项)落在图的右侧的白色金字塔之外。这些是我们在模拟中编排的5%的重要结果。请注意,这5项研究都是假阳性,因为没有真正的效果。如果有真正的影响(你可以重新运行模拟,通过将模拟中的m1 <- 0改为m1 <- 0.5,将d设置为0.5),金字塔云的点会向右移动,并以0.5而不是0为中心。
我们现在可以将上面的无偏元分析与有偏差的元分析进行比较。 我们可以模拟具有极端出版偏差的情况。 Scheel et al. (2021) 的估计,我们假设 96% 的研究显示出阳性结果。 我们在代码中设置pub.bias <- 0.96。 我们将两个均值都保持为 0,因此仍然没有真正的效果,但在最后一组研究中,我们最终会在预测方向上主要出现第一类错误。在模拟出有偏差的结果后,我们可以进行元分析,看看基于元分析的统计推断是否具有误导性。
Random-Effects Model (k = 100; tau^2 estimator: REML)
tau^2 (estimated amount of total heterogeneity): 0 (SE = 0.0019)
tau (square root of estimated tau^2 value): 0
I^2 (total heterogeneity / total variability): 0.00%
H^2 (total variability / sampling variability): 1.00
Test for Heterogeneity:
Q(df = 99) = 77.6540, p-val = 0.9445
Model Results:
estimate se zval pval ci.lb ci.ub
0.2701 0.0125 21.6075 <.0001 0.2456 0.2946 ***
---
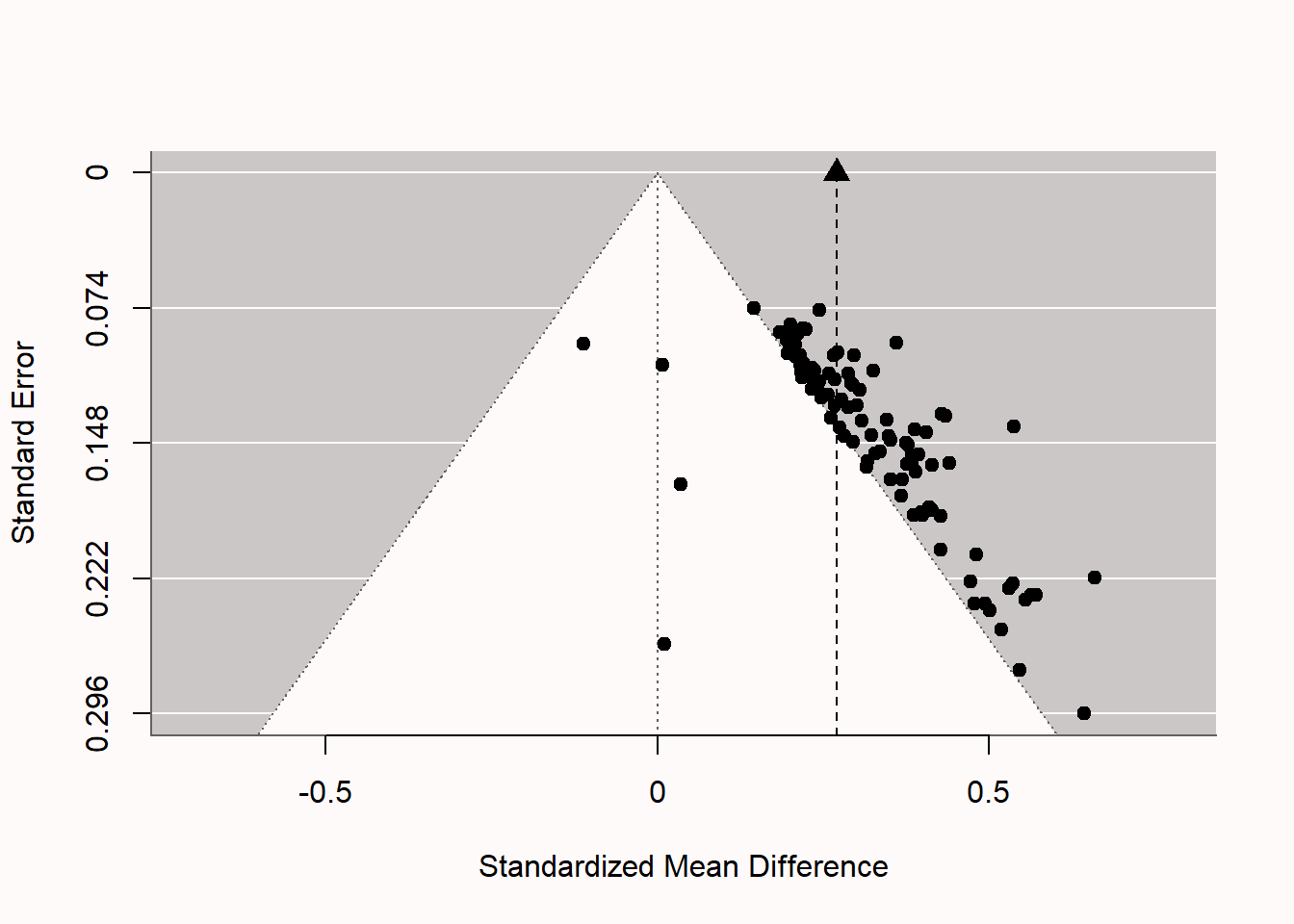
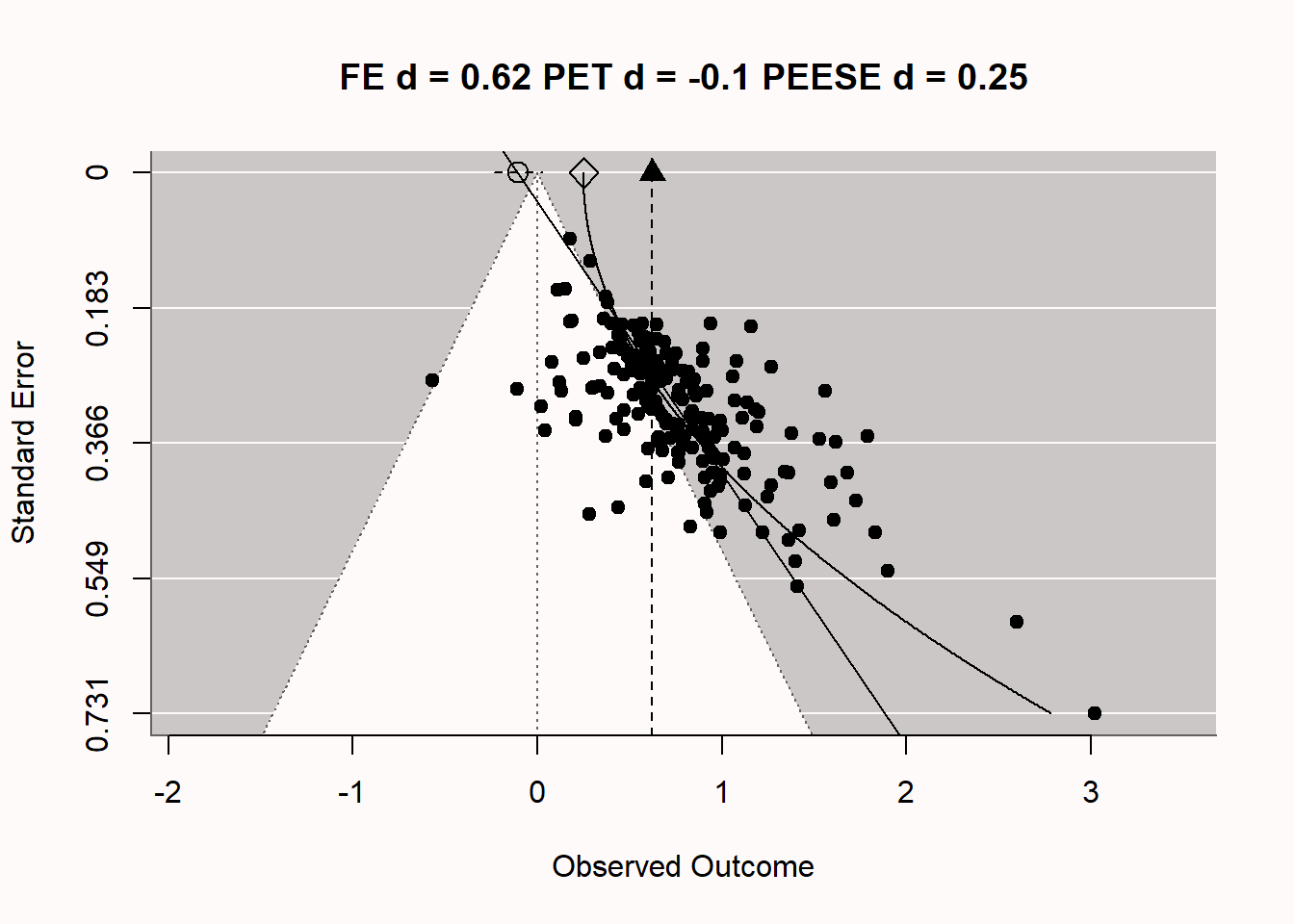
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1如果我们研究一下图中的漏斗图 Figure 5.6 ,就会发现我们所分析的这组研究的偏颇性。这个模式非常奇特。我们看到有四项无偏差的无效结果,正如我们在模拟中所设定的那样,但96项研究中的其余部分都在统计学上显著,尽管实际上并没有效应。我们看到大多数研究正好落在白色金字塔的边缘。由于p值在空值下是均匀分布的,我们观察到的第一类错误的p值往往在0.02到0.05之间,这与我们在存在真实效应的情况下的预期不同。这些仅仅是有意义的p值刚好落在白色金字塔的外面。研究规模越大,有意义的效应量就越小。事实上,效应量并不围绕单一的真实效应量而变化(例如,d=0或d=0.5),而是效应量随着样本量的增大(或标准误差的减小)而变小,这是一个强有力的偏差指标。图中顶部的垂直虚线和黑色三角形说明了观察到的(向上偏差的)元分析效应量估计。
人们可能会想,在科学研究中是否真的出现过这种极端的偏见。确实如此。在图 Figure 5.7 中,Carter & McCullough (2014) 的漏斗图,他研究了198项测试”自我消耗 “效应的已发表研究中的偏见,即自我控制依赖于有限资源的观点。你是否注意到与我们上面模拟的极度有偏见的元分析有任何相似之处?你可能不会感到惊讶,即使在2015年之前,研究人员认为有大量可靠的文献证明了自我消耗效应,但一份预注册的复制报告得出的效果大小估计并不显著(Hagger et al., 2016),甚至当原始研究人员试图复制自己的工作时,他们也未能观察到自我消耗的显著效果(Vohs et al., 2021)。想象一下,在一篇完全基于科学研究偏见的文献上,浪费了大量的时间、精力和金钱。显然,这种研究浪费具有伦理意义,研究人员需要负起责任,防止未来出现这种浪费。
我们也可以在元分析的森林图中看到偏见的迹象。在图 Figure 5.8 中,两个森林图是并排绘制的。左边的森林图是基于无偏见的数据,右边的森林图是基于有偏见的数据。100个研究的森林图有点大,但我们看到,在左边的森林图中,效果随机地在0附近变化,它们本该如此。在右边,在前四项研究之外,所有的置信区间神奇地排除了0的效应。

当研究人员只发表有统计学意义的结果(p < \(\alpha\) )而存在发表偏差时,你在元分析中计算效应量,与没有发表偏差时相比,存在发表偏差时(研究人员只发表p< \(alpha\)的效应)的元分析效应量估计值会偏高。这是因为出版偏差过滤掉了较小的(不显著的)效应量,然后不包括在元分析效应量的计算中。这导致元分析效应量的估计值大于真实效应量。在强烈的发表偏差下,我们知道元分析效应量被夸大了,但我们不知道有多大。真正的效应量可能只是小一点,但真正的效应量也可能是0,例如在自我耗损相关文献的情况下。
5.3 削减和填充
削减和填充是一种技术,旨在通过添加假设的“缺失”研究(可能在“文件抽屉”中)来增加数据集。该程序首先通过删除(“削减”)会对荟萃分析效应量造成偏差的小型研究,然后估计真实的效应量,并最终使用假设的缺失研究(由于出版偏差而缺失)填充漏斗图。在图 Figure 5.9 中,您可以看到与上述相同的漏斗图,但现在添加了假设的研究(未填充的圆点表示“插补”研究)。如果您仔细观察,您会发现每个点都在荟萃分析效应量估计的相反侧具有镜像图像(这在漏斗图的下半部分最清晰)。如果我们检查包括这些插补研究的荟萃分析结果,我们会发现削减和填充成功地提醒我们该荟萃分析存在偏差(如果没有,它不会添加插补研究),但它在校正效应量估计方面失败了。在漏斗图中,我们看到由三角形表示的原始(有偏)效应量估计和使用削减和填充方法调整的荟萃分析效应量估计(由黑色圆圈表示)。我们看到荟萃分析效应量估计略微降低,但考虑到模拟中真实的效应量为0,此调整显然不足。
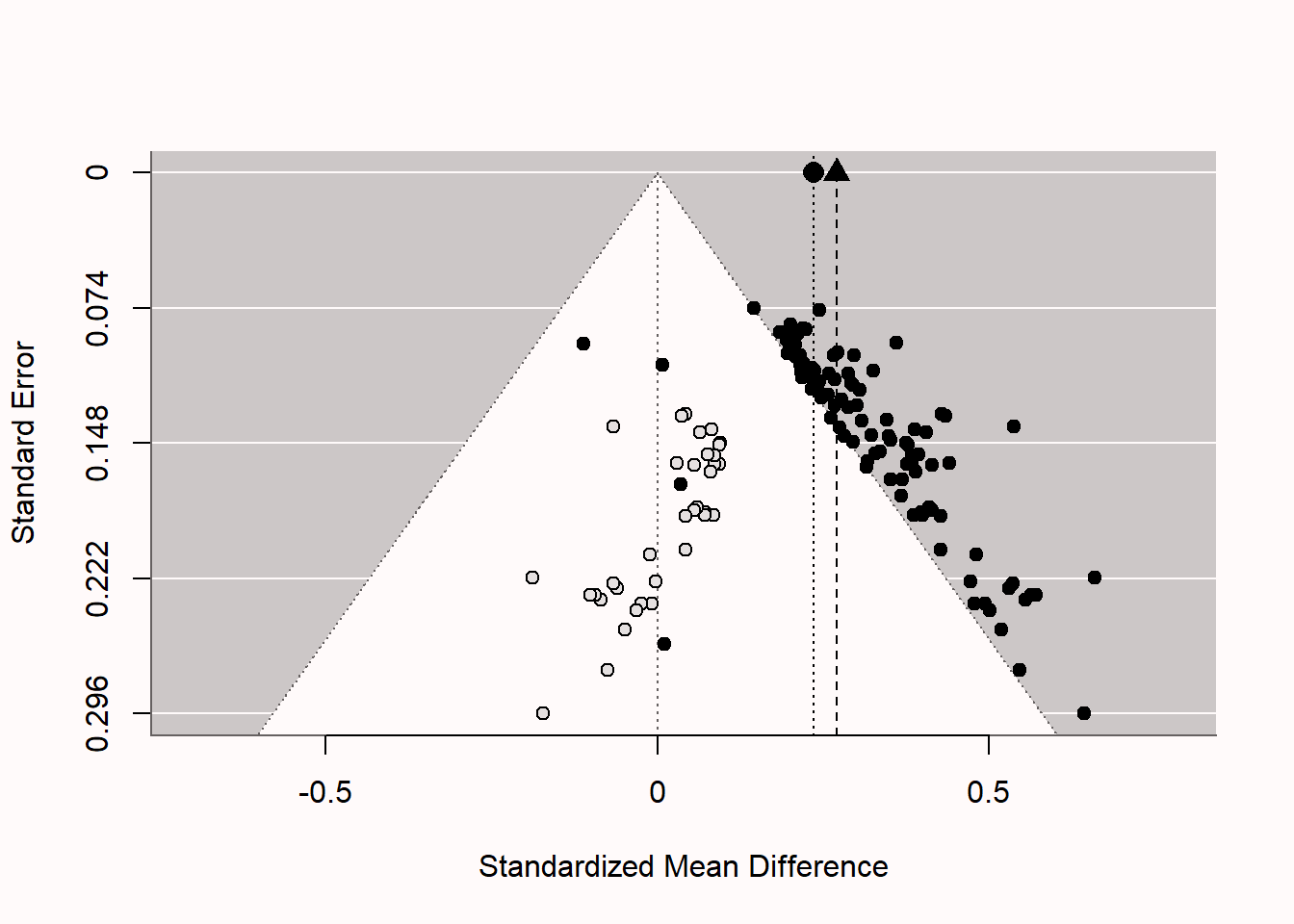
削减和填充在许多实际出版偏差场景下表现不佳。该方法因依赖漏斗图对称性的强假设而备受批评。当出版偏差基于研究的p值时(在许多领域中可能是最重要的出版偏差来源),削减和填充方法的效果不足以产生接近真实效应大小的纠正荟萃分析效应量估计(Peters et al., 2007; Terrin et al., 2003)。在假设成立的情况下,它可以作为敏感性分析的一种方法。研究人员不应将削减和填充校正的效应量估计报告为无偏效应量的实际估计。如果其他偏差检测测试(如下文所述的p曲线或z曲线)已经指示存在偏差,则削减和填充程序可能无法提供额外的洞见。
5.4 精度效应测试-带标准误差的精度效应估计
一种新的解决出版偏差的方法是荟萃回归。荟萃回归不是通过描绘数据点的线条来展示数据,而是通过描绘每个代表一项研究的数据点的线条来呈现数据。与普通的回归分析类似,荟萃回归基于的数据越多,估计结果越精确,因此,在进行荟萃分析时,研究数量越多,荟萃回归在实践中的效果就会越好。如果研究数量很少,所有偏差检测测试都会失去功效,使用荟萃回归时需要记住这一点。此外,回归分析需要数据的足够变异性,而在荟萃回归中,这意味着需要广泛的样本量范围(建议指出,如果每组研究对象的范围在15至200人之间,荟萃回归方法的效果会更好——这在心理学的大多数研究领域并不典型)。荟萃回归技术试图估计在精度完美时(标准误差 = 0)的总体效应大小。
一种荟萃回归技术被称为PET-PEESE(Stanley et al., 2017; Stanley & Doucouliagos, 2014)。它由一个“精度效应测试”(PET)组成,可以在Neyman-Pearson假设检验框架中使用,以检验荟萃回归估计能否基于PET估计的95%置信区间拒绝效应量为0的假设,即在截距SE=0处。需要注意的是,当由于观测值很少而置信区间非常宽时,这个测试可能具有低功效,并且先验地低概率拒绝零效应。通过以下公式计算PET的估计效应量:\(d = β_0 + β_1SE_i + _ui\),其中d为估计效应量,SE为标准误差,该方程式使用加权最小二乘(WLS)估计,并以1/SE^2i作为权重。PET估计低估了真实效应大小。因此,PET-PEESE程序建议首先使用PET检验能否拒绝零假设,如果可以,则使用“带标准误差的精度效应估计”(PEESE)来估计荟萃分析效应量。在PEESE中,标准误差(在PET中使用)被方差(即标准误差的平方)所代替,Stanley & Doucouliagos (2014) 发现这可以减少荟萃回归截距的估计偏差。
PET-PEESE也存在局限性,就像所有的偏差检测技术一样。最大的限制是,当研究数量很少,荟萃分析中的所有研究样本量都很小,或者当荟萃分析中存在大的异质性(Stanley et al., 2017)时,它的效果不佳。在这些情况下(实际上这些情况很常见),PET-PEESE可能不是一个好的选择。此外,有些情况下样本量和精度可能存在相关性,这在实践中通常与荟萃分析中包含的效应大小的异质性有关。例如,如果不同的研究具有不同的真实效应,而人们使用有关预期真实效应大小的准确信息进行功效分析,则荟萃分析中的大效应量将具有较小的样本量,而小效应量则具有较大的样本量。荟萃回归和普通的回归分析一样,是一种测试关联性的方法,但你需要思考关联性背后的因果机制。
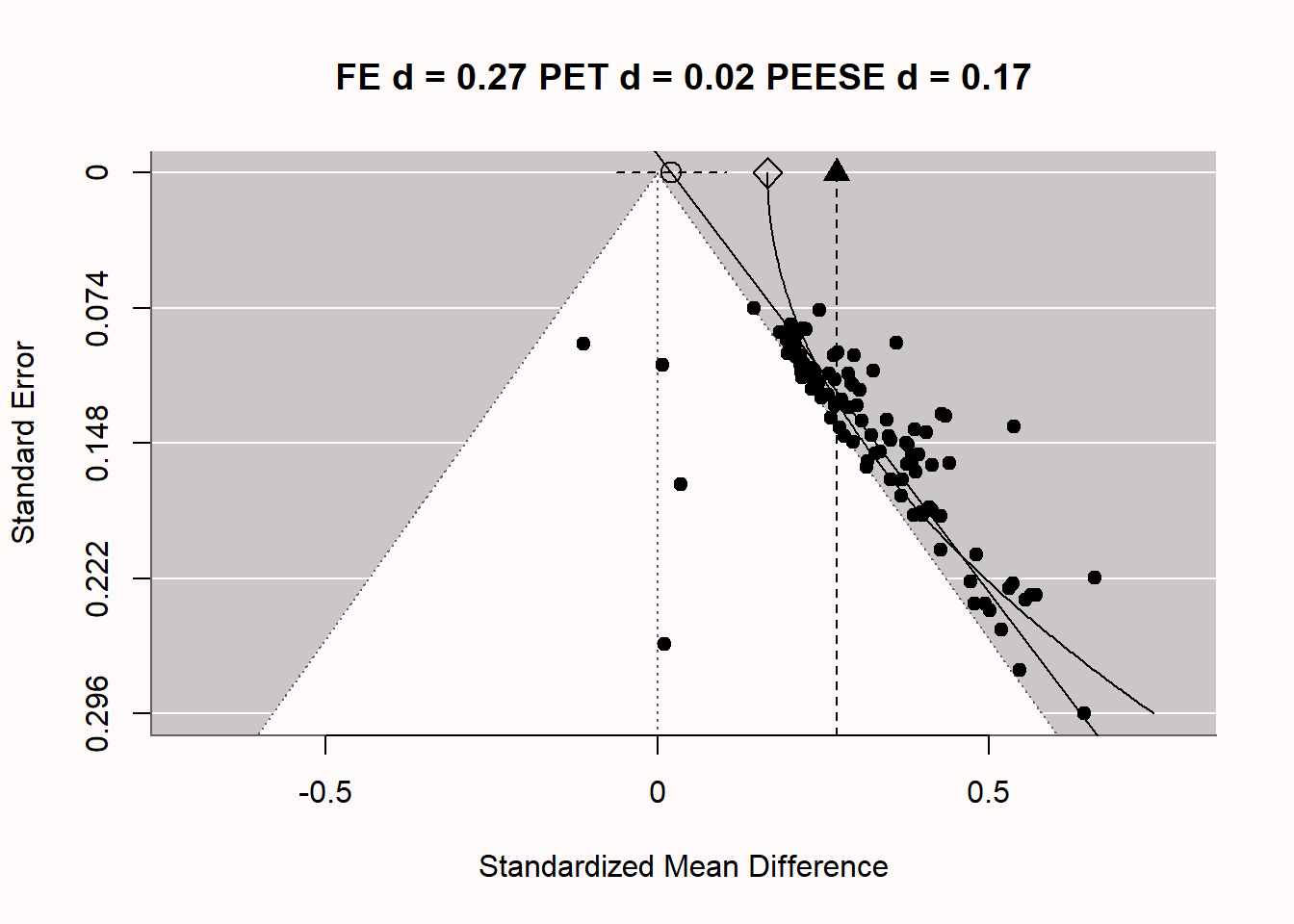
让我们探讨一下PET-PEESE荟萃回归是如何在特定假设出版偏差的情况下尝试给出无偏效应量估计的。在图@fig-petpeese中,我们再次看到漏斗图,现在还有两条额外的线穿过图表。竖直线在d = 0.27处是荟萃分析效应量估计,因为我们只对显著性研究进行平均,所以这个估计值会向上偏差。有两条附加的线,它们是基于先前详细介绍的公式,PET-PEESE荟萃回归的元回归线。直线对角线给出了在SE为0(即在图的顶部,具有无限样本)的PET估计,由圆圈表示。围绕这个PET估计的虚线是估计的95%置信区间。在这种情况下,95%置信区间包含0,这意味着基于d = 0.02的PET估计,我们不能拒绝荟萃分析效应量为0的假设。请注意,即使有100项研究,95%置信区间也很宽。荟萃回归和普通的回归分析一样,只有我们拥有的数据准确性才能得到保证。这是PET-PEESE荟萃回归的一个局限性:在荟萃分析中的研究数量较少时,它的准确性较低。如果我们能够基于PET估计拒绝零假设,那么我们将使用PEESE估计(由菱形形状表示)的d = 0.17进行纠正偏差的荟萃分析效应量估计(同时永远不知道PEESE估计模型是否与荟萃分析中真实的偏差产生机制相对应,因此无法确定荟萃分析估计值是否准确)。
5.5 p值的荟萃分析
除了效应量的荟萃分析外,还可以进行p值的荟萃分析。这种方法中的第一个是Fisher综合概率检验,而更近期的偏差检测测试,如p曲线分析(Simonsohn et al., 2014)和pp均匀分布(Aert & Assen, 2018)则是基于此思想。这两种技术是选择模型方法的例子,用于测试和调整荟萃分析(Iyengar & Greenhouse, 1988),其中将关于效应量数据生成过程的模型与关于发表偏差如何影响哪些效应量成为科学文献一部分的选择模型相结合。数据生成过程的一个示例是,研究结果是由满足所有检验假设的统计检验生成的,并且这些研究具有一定的平均功效。选择模型可能是只要研究在0.05的显著性水平下具有统计显著性,就会发表所有的研究。
P曲线分析正是利用了这个选择模型。它假设所有显著结果都被发表,并检查数据生成过程是否符合研究具有一定功效时所期望的模式,或者数据生成过程是否符合零假设成立时所期望的模式。正如在你可以期望哪些p值的部分中所讨论的那样,当零假设成立时,我们应该观察到p值均匀分布,而当备择假设成立时,我们应该观察到比大的显著p值(例如0.04)更多的小的显著p值(例如0.01)。p值曲线分析进行两个测试。在第一个测试中,p值曲线分析检查p值分布是否比你分析的研究具有33%的功效时所期望的分布更为平坦。这个值有点武断(但可以调整),但其想法是在最小的统计功效水平上拒绝,这将导致有关存在效应的有用见解。如果研究集中的平均功效小于33%,可能存在效应,但这些研究的设计不足以通过统计检验来学习效应。如果我们可以拒绝至少具有33%功效的p值模式的存在,这表明分布更像是零假设成立时所期望的。也就是说,即使所有单独的研究都是显著的,我们也会怀疑荟萃分析所包含的研究集中是否存在效应。
第二个测试检查p值分布是否足够右偏倚(更多的小显著p值而非大显著p值),以便这种模式表明我们可以拒绝均匀的p-值分布。如果我们可以拒绝具有至少33%功率的p-值模式的存在,这表明分布看起来更像是空假设为真时预期的分布。也就是说,我们会怀疑该元分析中包含的研究是否存在效应,即使所有独立的研究都是统计显著的。第二个测试检验是否存在足够的右偏,以拒绝均匀分布的p值分布。如果第二个测试是显著的,我们将视为这些研究检验了某些真正的效应,即使存在出版偏差。例如,让我们考虑Simonsohn和同事(2014)的图3。作者比较了20篇在《人格与社会心理学杂志》(Journal of Personality and Social Psychology)中使用协变量的论文和20个未使用协变量的研究。作者怀疑研究人员可能在分析中添加协变量,以尝试找到小于0.05的p值,当他们第一次尝试的分析没有产生显著的效应时。
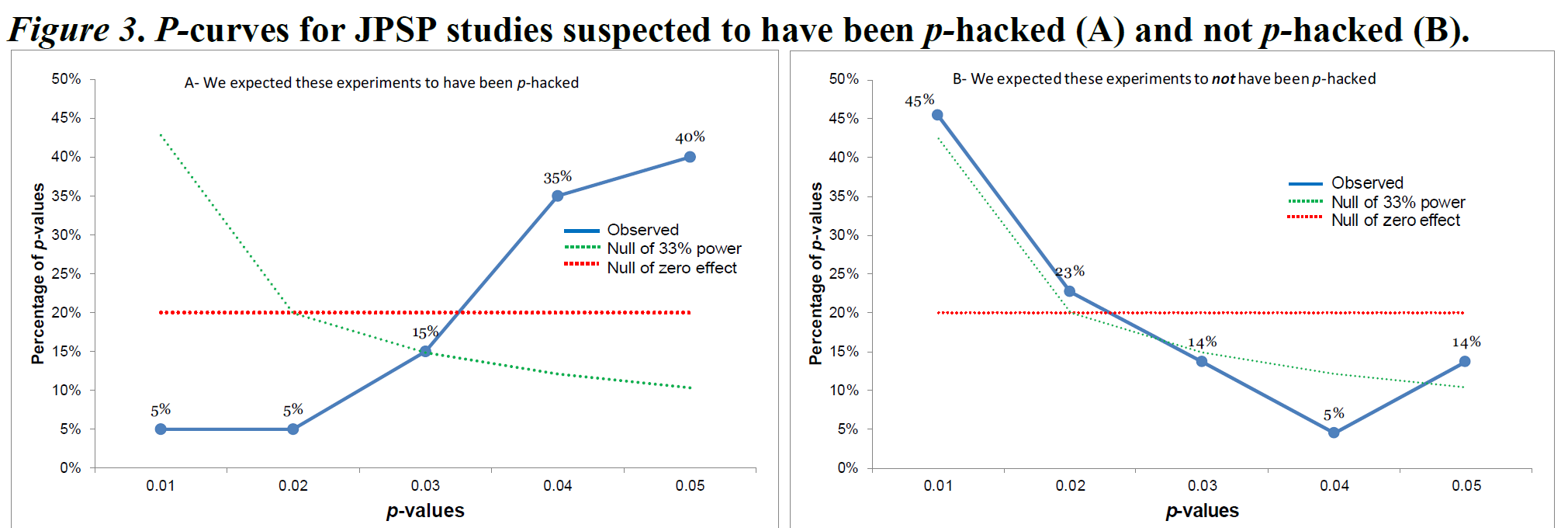
观察到的p值的p值曲线分布由蓝线上的五个点表示。p值曲线分析仅对统计显著的结果进行,基于这样的假设,即这些结果总是被发表,因此这部分p值值分布包含了所有已进行的研究。这五个点表示了p值值在0到0.01、0.01到0.02、0.02到0.03、0.03到0.04和0.04到0.05之间的百分比。在右图中,可以看到一个相对正常的右偏的p值分布,其中低p值比高p值多。P值曲线分析显示,右图中的蓝线比均匀的红线更右偏(其中红线是预期如果没有效应的情况下的均匀p值分布)。Simonsohn和同事将这种模式概括为一组研究具有“证据价值”,但这种术语有些误导。正确的解释是我们可以拒绝均匀的p值分布,这是在p值曲线分析中包括的所有研究中当零假设为真时预期的情况。拒绝均匀的p值值分布并不意味着自动存在对理论效应的证据(例如,该模式可能由一组空效应和少数显示效应的研究组成,这是由于方法上的混杂因素引起的)。
在左图中,我们看到相反的模式,主要是高p值(约0.05),几乎没有p值在0.01左右。由于蓝线显著平坦,比绿线更平坦,p值曲线分析表明这些研究集合是受到选择性偏差的影响,并且不是由一组具有足够功效的研究产生的。P值曲线分析是一个有用的工具,但正确解释它能告诉你什么是很重要的。右偏的p值曲线不能证明不存在偏差或理论假设成立。平坦的p值曲线不能证明理论不正确,但它表明被元分析的研究看起来更像是在零假设成立且存在选择性偏差的情况下期望的模式。
该脚本存储元分析中包含的100个模拟t测试的所有测试统计信息。前几行如下所示:
t(136)=0.208132209831132
t(456)=-1.20115958535433
t(58)=0.0422284763301259
t(358)=0.0775200850900646
t(188)=2.43353676652346Print all test results with cat(metadata$pcurve, sep = "\n"), and go to the online p-curve app at http://www.p-curve.com/app4/. Paste all the test results, and click the ‘Make the p-curve’ button. Note that the p-curve app will only yield a result when there are p-values smaller than 0.05 - if all test statistics yield a p > 0.05, the p-curve cannot be computed, as these tests are ignored. 请使用cat(metadata$pcurve, sep = "\n")打印出所有测试结果,并转到在线p值曲线应用程序http://www.p-curve.com/app4/。粘贴所有测试结果,然后单击“生成p值曲线”按钮。请注意,p值曲线应用程序仅在存在小于0.05的p值时才会产生结果,如果所有测试统计量的p > 0.05,则无法计算p值曲线,因为这些测试将被忽略。
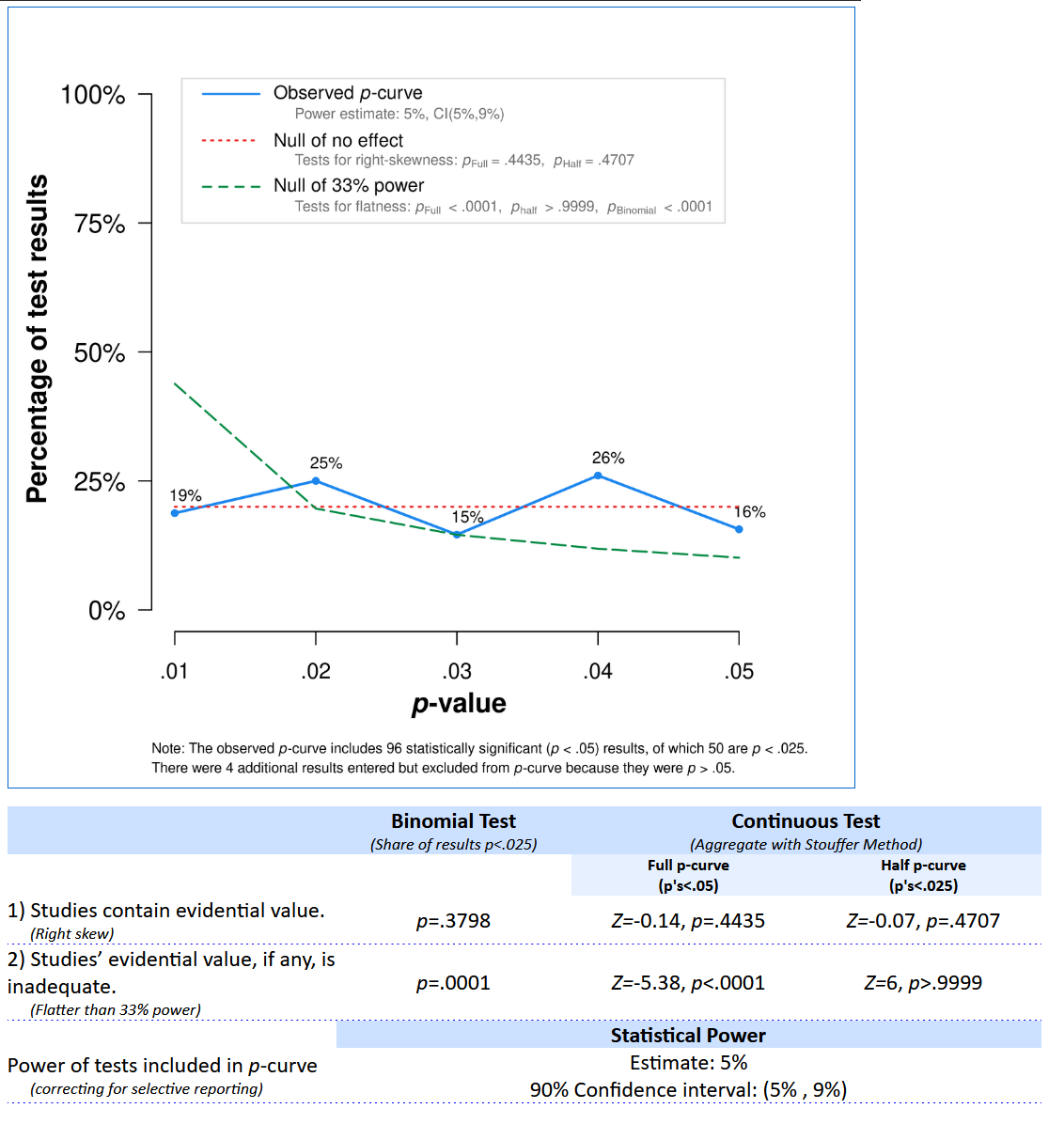
P值的分布明显呈均匀分布(事实上就是如此),而统计检验表明我们可以拒绝一个p值分布与33%功效水平的研究生成的p值分布一样陡峭或更陡峭的假设,p < 0.0001。该应用程序还提供了生成观察到的p值分布的测试的平均功效估计,为5%,这是正确的。因此,我们可以得出结论,即这些研究,即使许多效应在统计上是显著的,更符合选择性报告第一类错误的类型,而不是符合应该期望存在足够的统计功效研究的真实效应的p值分布。该理论仍然可能是正确的,但我们在这里分析的研究并不支持该理论。
类似的元分析技术是p-uniform。这种技术类似于p值曲线分析和选择性偏差模型,但它使用了显著和非显著研究的结果,并可用于估计校正偏差的元分析效应量估计。该技术使用随机效应模型估计每个研究的效应量,并根据一个选择模型对它们进行加权,该模型假设显著结果比非显著结果更有可能被发表。下面是p-uniform的输出,它估计偏差校正效应大小为d = 0.0126。这个效应大小与0没有显著差异,p = 0.3857,因此,这个偏差检测技术正确地表明,即使所有效应都是显著的,这些研究的集合也没有提供拒绝0的元分析效应量估计的充分理由。
puniform::puniform(m1i = metadata$m1, m2i = metadata$m2, n1i = metadata$n1,
n2i = metadata$n2, sd1i = metadata$sd1, sd2i = metadata$sd2, side = "right")
Method: P
Effect size estimation p-uniform
est ci.lb ci.ub L.0 pval ksig
0.0126 -0.0811 0.0887 -0.2904 0.3857 96
===
Publication bias test p-uniform
L.pb pval
7.9976 <.001
===
Fixed-effect meta-analysis
est.fe se.fe zval.fe pval.fe ci.lb.fe ci.ub.fe Qstat Qpval
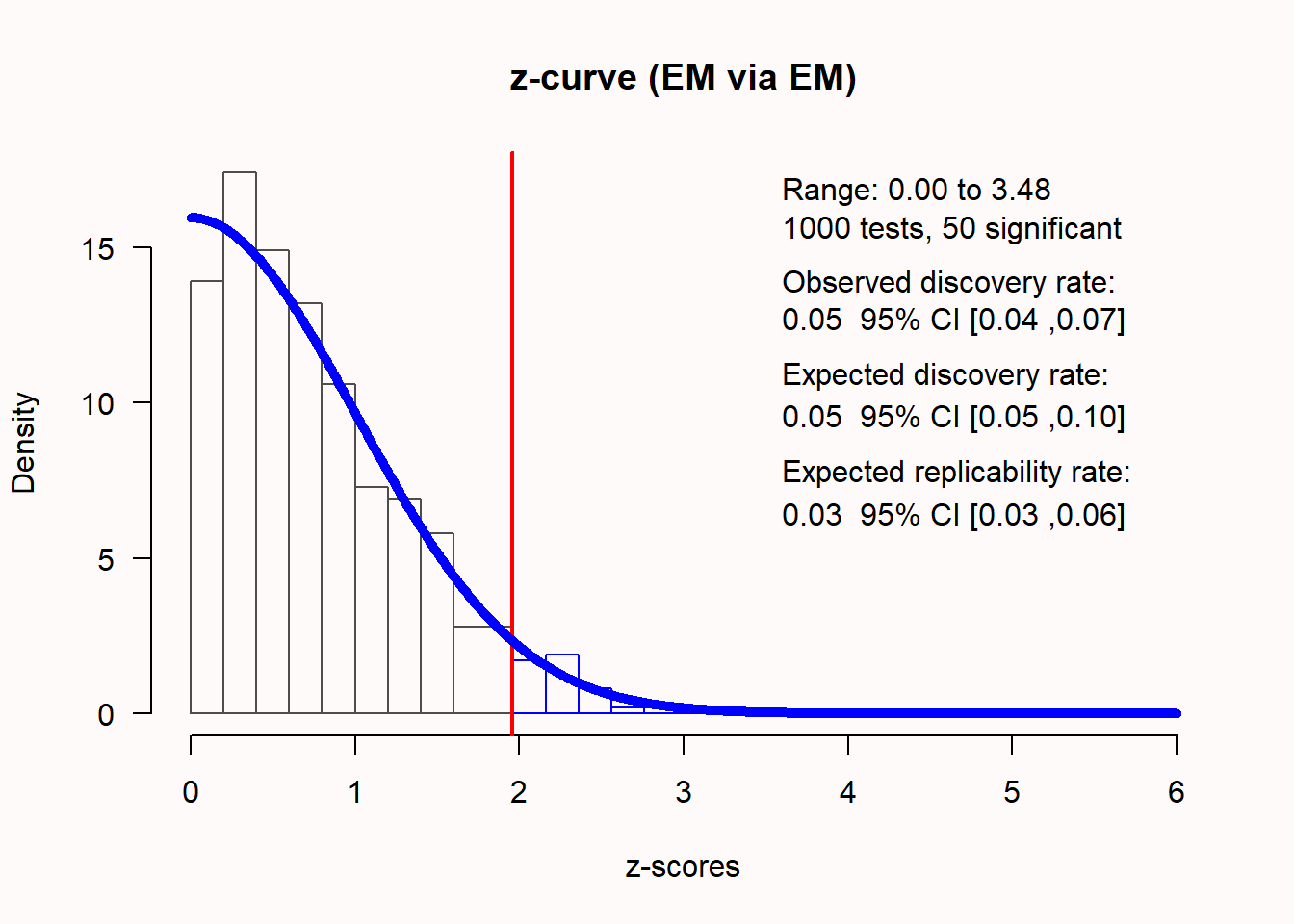
0.2701 0.0125 21.6025 <.001 0.2456 0.2946 77.6031 0.945一个也对个体的研究中的p值进行元分析的替代技术是z值曲线分析,它是观察功效的元分析 (Bartoš & Schimmack, 2020; Brunner & Schimmack, 2020)(一个例子请参见(Sotola, 2022))。与传统的元分析类似,z值曲线分析将观察到的检验结果(p值)转化为z分数。在一个无偏的文献中,如果零假设成立,我们应该观察到大约 \(\alpha\) %的显著结果。如果零假设成立,则z分数的分布以0为中心。Z值曲线分析计算绝对值的z值,因此应有 \(\alpha\) %的z分数大于临界值(5%的显著性水平下为1.96)。在图 Figure 5.13 中,绘制了1000个研究的z分数,真实效应大小为0,观察到的结果中恰好有5%是统计显著的。
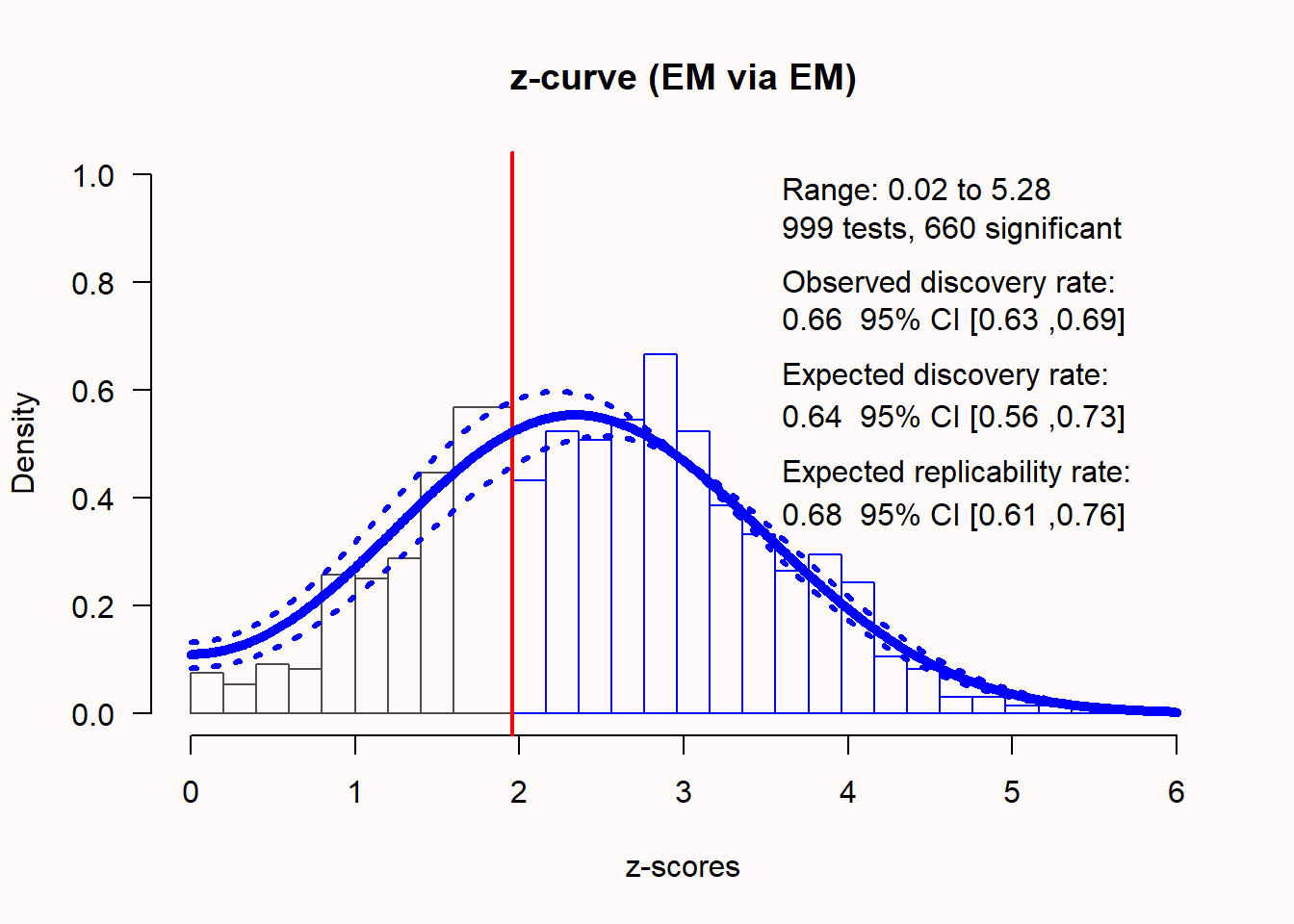
如果存在真实效应,z值的分布会随着统计功效的变化而发生变化,z值的分布会偏离0。统计功效越高,z值的分布就越偏向右边。例如,当检查具有66%统计功效的效应时,从观察到的p值计算得出的不偏z值分布如图 Figure 5.14 所示。
在任何元分析中,包括的研究将在其统计功效和真实效应大小方面存在差异(由于异质性)。Z值曲线分析使用以0至6为中心的正态分布混合来拟合最能代表所包括研究的观察结果的潜在效应大小的模型(有关技术细节,请参见 Bartoš & Schimmack (2020))。然后,z值曲线旨在估计研究集的平均功效,然后计算观察发现率(ODR:显著结果的百分比或观察到的功效)、预期发现率(EDR:显著性水平右侧曲线下面积的比例)和预期复制率(ERR:所有显著研究中成功复制显著研究的预期比例)。Z值曲线能够在特定假设下纠正对正面结果的选择偏倚,并可以仅使用显著的p值来估计EDR和ERR。
为了检查是否存在偏差,最好将非显著性和显著性p值一起提交到z值曲线分析中,即使仅使用显著性p值进行估计。然后可以通过比较ODR和EDR来检查发表偏倚。如果研究中显著结果的百分比(ODR)远高于预期发现率(EDR),则存在偏差的迹象。如果我们使用上面讨论偏差检测技术的偏倚样本集进行分析,z值曲线分析应该能够指示是否存在偏倚。我们可以使用以下代码执行z值曲线分析:
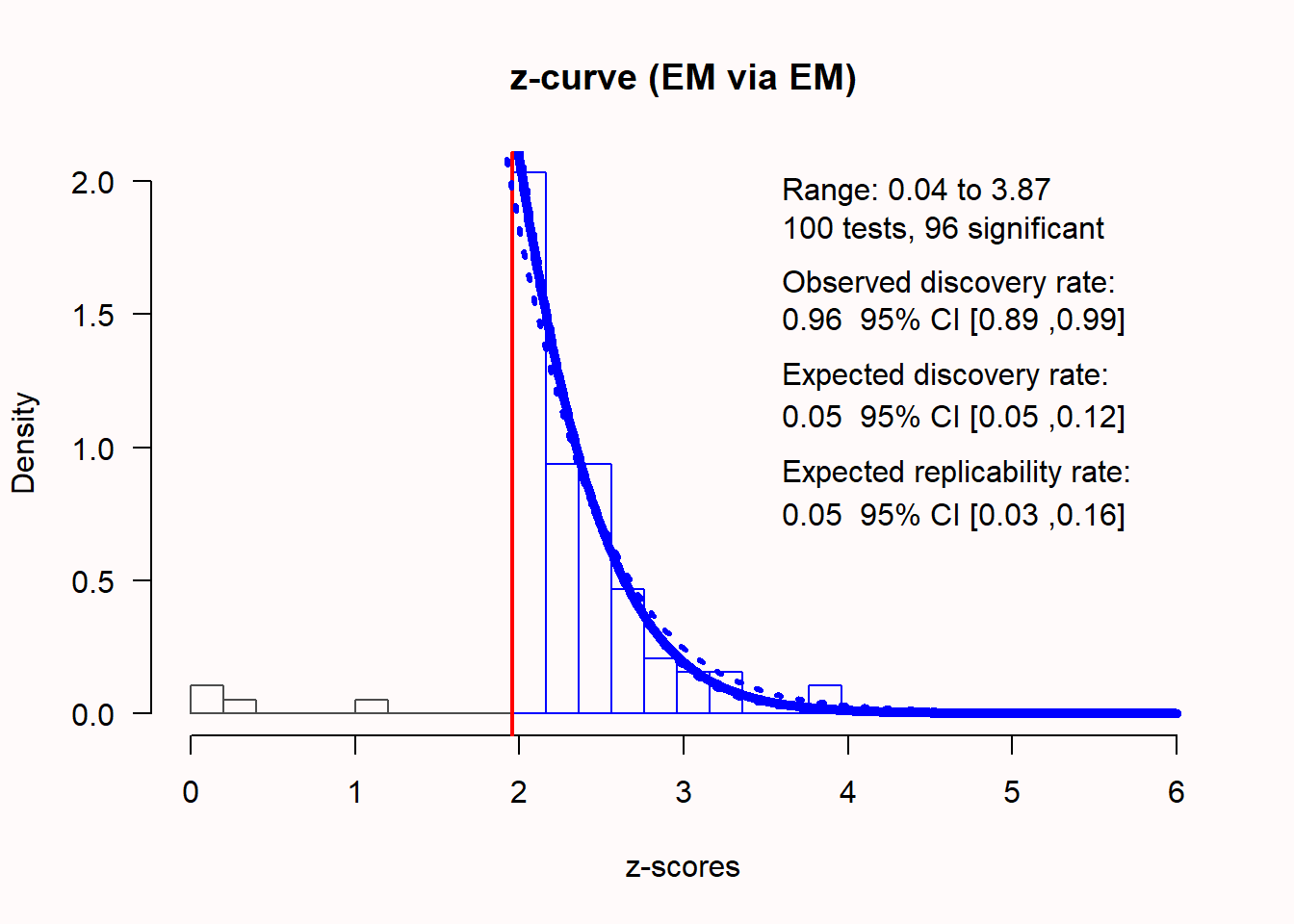
Call:
zcurve::zcurve(p = metadata$pvalues, method = "EM", bootstrap = 1000)
model: EM via EM
Estimate l.CI u.CI
ERR 0.052 0.025 0.160
EDR 0.053 0.050 0.119
Soric FDR 0.947 0.389 1.000
File Drawer R 17.987 7.399 19.000
Expected N 1823 806 1920
Missing N 1723 706 1820
Model converged in 38 + 205 iterations
Fitted using 96 p-values. 100 supplied, 96 significant (ODR = 0.96, 95% CI [0.89, 0.99]).
Q = -6.69, 95% CI[-23.63, 11.25]我们可以看到,z值得分的分布看起来很奇怪。大部分期望的z得分在0和1.96之间的值都不见了。96个研究中有95个研究是显著的,这使得观察发现率(ODR)或(在这些具有不同样本量的研究中)观察到的功效为0.96,95% CI[0.89; 0.99]。期望的发现率(EDR)只有0.053,这与观察到的发现率存在统计学差异,这表明EDR的置信区间与0.96的ODR不重叠。这意味着基于z值曲线分析存在明显的选择偏倚。这些研究的预期可复制性率只0.052,这与我们只会观察到5%的Type 1错误的期望相一致,因为在这个模拟中没有真实的效应。因此,即使我们只输入了显著的p值,z值曲线分析正确地表明我们不应该期望这些结果的复制率高于Type 1错误率。
5.6 结论
发表偏倚是科学界的一个大问题。几乎所有对科学文章中主要假设检验进行的元分析都存在此问题,因为主要假设检验具有统计显著性的文章更可能成功发表。未经偏倚校正的元分析效应量估计会高估真实的效应量,而偏倚校正过的效应量估计可能仍然不够准确。鉴于科学文献已经受到发表偏倚的影响,我们无法确知我们对文献中元分析效应量估计的计算是否准确。发表偏倚会放大效应量估计,而其影响程度是未知的,已经证实了有几个案例的真实效应量为零。虽然本章提到的发表偏倚检验可能无法提供无偏效应量的确定性,但它们可以作为标志来检测偏倚是否存在,并提供校正后的效应量估计。如果发表偏倚的基本模型是正确的,那么校正后的估计值会更接近真实值。
目前学术界对于出版偏倚检验的研究非常活跃。存在许多不同的检验方法,使用之前你需要仔细检查每种检验的假设条件。当存在较大的异质性时,大多检验都不太可靠,而异质性的出现是非常有可能的。元分析应始终检查是否存在发表偏倚,最好使用多种发表偏倚检验方法。因此不仅要编码效应量,还应编码检验的统计量或p值,这对研究非常有用。本章讨论的偏倚检验技术没有一个是完美的,但相比于单纯地解释元分析中未校正的效应量估计,它们更为可靠。
关于发表偏倚检验的另一个开放学习资源,请参阅Doing Meta-Analysis in R.
5.7 自我测验
Q1:当出现由于研究人员只发表具有统计显著性(p <  \(\alpha\) )的结果而导致的发表偏倚时,计算元分析中的效应量会出现什么情况?
- 无论是否存在发表偏倚(即研究人员只发表p < \(alpha\)的显著结果),元分析的效应量估计值都是相同的。
- 当存在发表偏倚(研究人员只发表p < \(alpha\)的显著结果)时,元分析效应量估计值会比不存在发表偏倚时更接近真实效应量。
- 当存在发表偏倚(研究人员只发表p < \(alpha\)的显著结果)时,元分析的效应量估计值会比不存在发表偏差时更高。
- 当存在发表偏倚(研究人员只发表p < \(alpha\)的显著结果)时,元分析效应量估计会比没有发表偏倚时更低。
Q2: 下图中的森林图看起来相当奇怪,你注意到了什么?
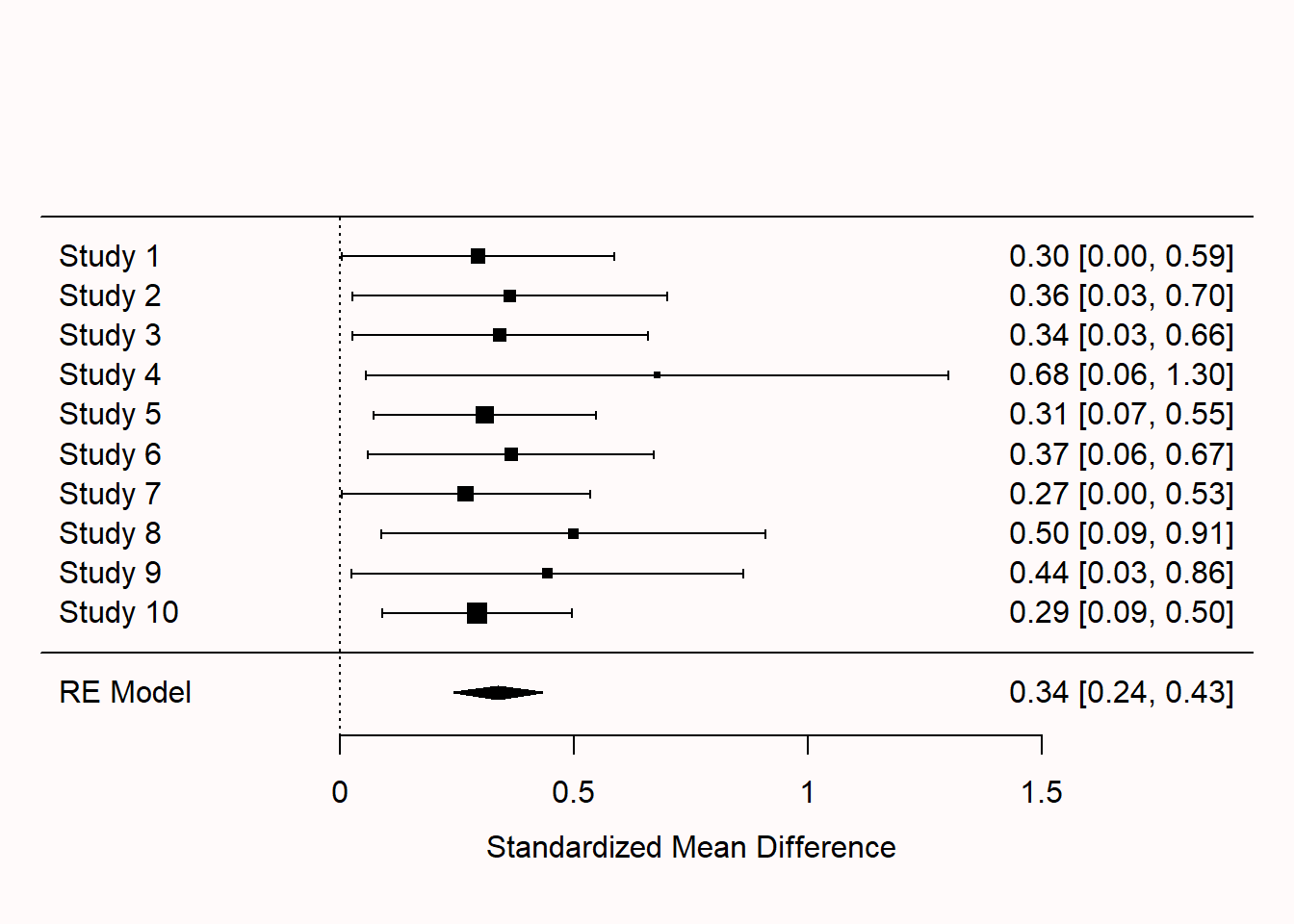
- 所有效应量都非常相似,表明样本量很大且对效应量的测量非常准确。
- 这些研究看起来好像是基于完美的先验功效分析/先验样本量估算设计的,所有结果都显著。
- 这些研究的置信区间仅仅没有包含0,这意味着大多数研究仅仅具有较小的统计显著性,即存在发表偏倚。
- 所有效应方向相同,这表明可能进行了单侧检验,尽管这些检验可能没有进行预注册。
Q3:以下哪个表述是正确的?
- 在极端的发表偏倚下,文献中所有单独的研究都显著,但标准误差非常大,导致元分析的效应量估计值与0之间的差异不显著。
- 在极端的发表偏倚下,文献中所有单独的研究都显著,但元分析效应量估计值被严重夸大,给人留下支持\(H_1\)的压倒性印象,而实际上真实效应可能很小,甚至可能为0。
- 在极端的发表偏倚下,所有单独的研究都显著,但大多数统计软件包进行元分析效应量估计时会自动校正发表偏倚,因此元分析效应量估计值是可靠的。
- 无论是否存在发表偏倚,元分析的效应量估计都存在严重偏差,因此不能将其是为总体的可靠估计。
Q4: 根据下面基于 PET-PEESE 的元回归分析图表,以下哪个陈述是正确的?
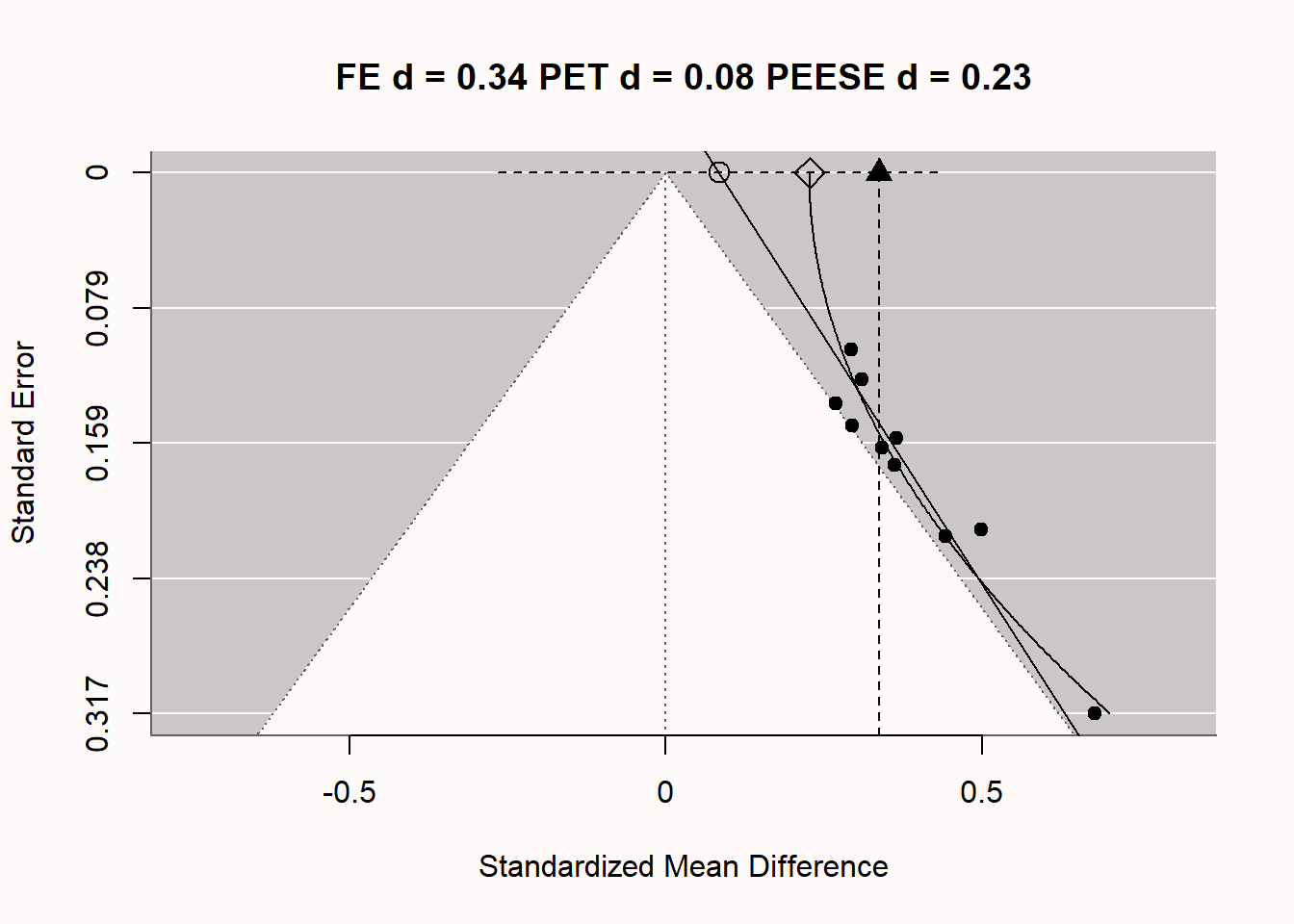
- 通过PET-PEESE元回归,我们可以得知真实效应大小为d = 0(基于PET估计)。
- 通过PET-PEESE元回归,我们可以得知真实效应大小为 d = 0.23 (基于PEESE估计)。
- 通过PET-PEESE元回归,我们可以得知真实效应大小为d=
rround(result.biased$b,2)(基于一般的元分析效应量估计)。 - 由于样本量很小(10个研究),PET的统计检验力很低,无法可靠地拒绝零假设,因此它不是偏倚的可靠指标,但仍有偏倚存在的风险。
Q5: 如下是p-curve应用程序输出的图表,其中给出了Q2中的研究结果。以下哪种解释是正确的?
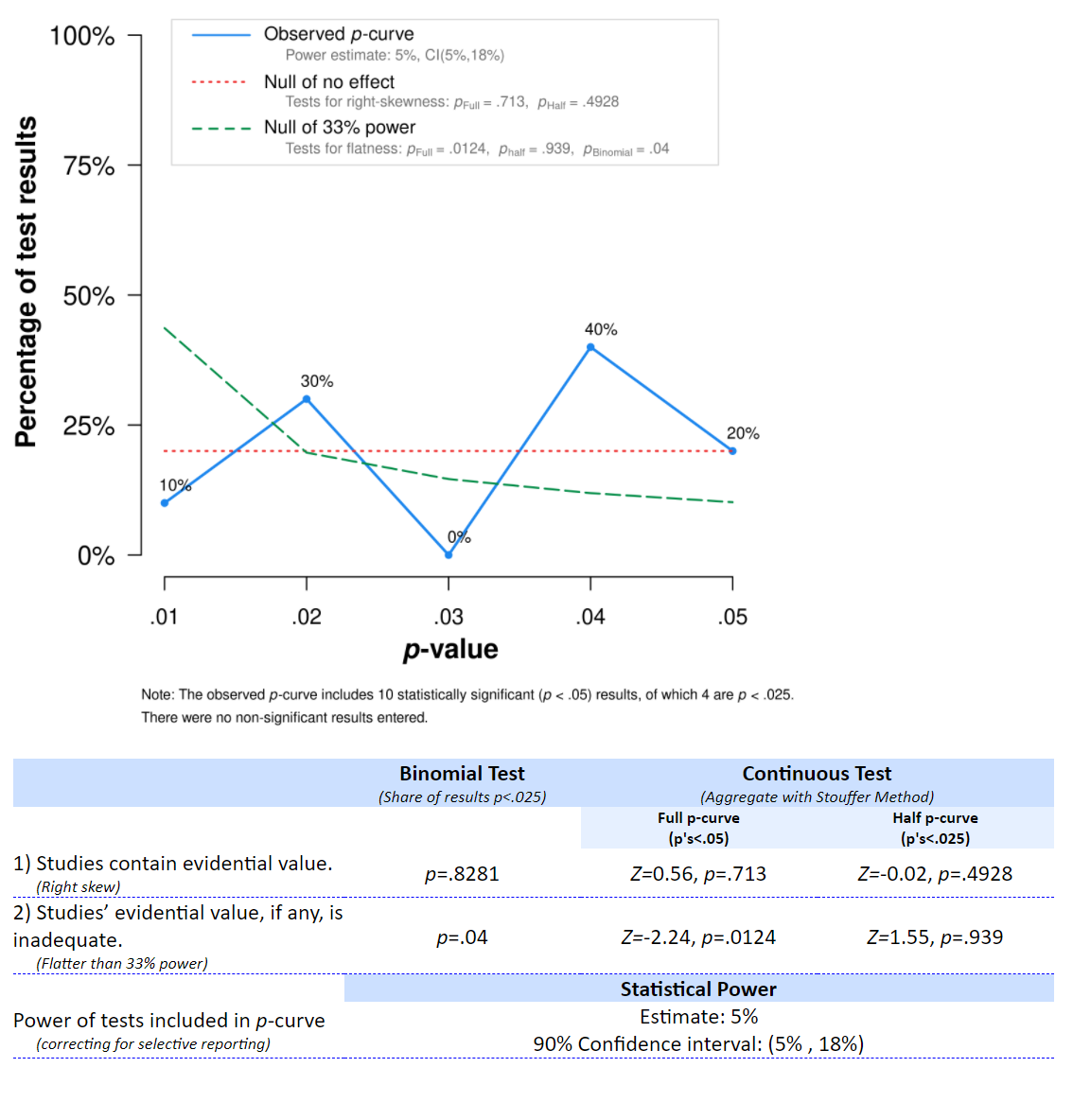
- 基于对p-curve进行的连续Stouffer’s检验,我们无法拒绝在H0假设下预期的p值分布,但在33%的统计检验力下,可以拒绝在 H1假设为真时预期的 p值分布。
- 基于对p-curve进行的连续Stouffer’s检验,我们可以得出结论:观察到的p值分布的倾斜程度不足以解释真实效应量的大小,因此用于推断这些研究的理论是错误的。
- 基于对p-curve进行的连续Stouffer’s检验,我们可以得出结论:观察到的p值分布倾斜程度足以解释为H1为真且研究统计检验力为33%时预期的p值分布。
- 基于对p-curve进行的连续Stouffer’s检验,我们可以得出结论:观察到的p值分布比研究统计检验力为33%时预期的p值分布更平坦,因此可以推测这些研究伪造了数据。
Q6: 在 Q2 模拟的研究中,真实效应量为0,即不存在真实效应。下面关于z-curve的分析,哪个陈述是正确的?
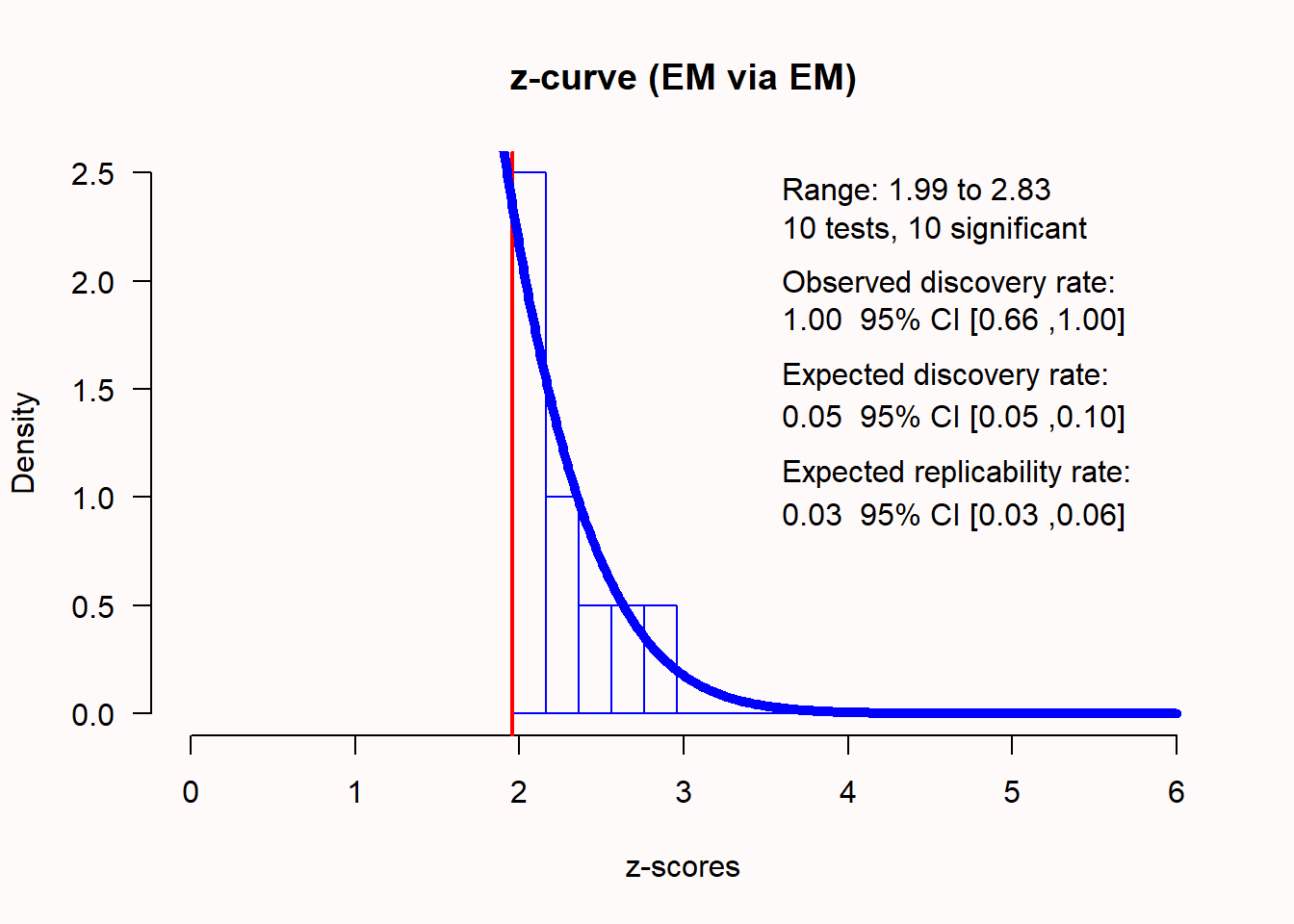
- 预期的发现率和可重复率都具有统计显著性,因此可以预计这些观测到的效应能够在未来的研究中成功复制。
- 尽管观测到的平均功效(观测到的发现率)为100%,但z-curve正确预测了预期的可重复率(仅为5%,只有当研究发生第一类错误时,结果才会在统计学上显著)。
- 由于预期的发现率和可重复率在统计上没有显著差异,因此Z-curve无法识别偏差。
- 虽然观测的发现率为1(表示观测到的功效为100%),但置信区间范围为0.66-1,这表明这些研究实际上的功效更低,100%的结果显著可能只是偶然。
Q7: 我们尚未进行修剪和填补分析,鉴于上述分析(例如z-curve分析),以下哪个陈述是正确的?
- 修剪和填补方法可能不会指出有需要”填补”的缺失研究。
- 修剪和填补方法检测偏倚的功效较弱,而且可能与上面提到的z-curve或p-curve分析相矛盾。
- 修剪和填补分析可以检测偏倚,正如p-curve和z-curve分析,而且修剪和填补分析校正后的效应量估计并不能充分纠正偏倚,因此这个分析没有任何作用。
- 修剪和填补方法可以对真实效应量进行可靠估计,而上述的其他方法都做不到,因此应该将其与其他的偏倚检验一起报告。
Q8: 发表偏倚被定义为选择性提交和发表科学研究。在本章中,我们关注的是选择性提交显著结果。你能想到某个研究领域或研究问题,其研究人员更喜欢选择性地发表不显著的结果吗?
5.7.1 开放性问题
GRIM检验背后的思想是什么?
发表偏倚的定义是什么?
什么是”文件抽屉问题”?
在漏斗图中,对于落在漏斗中心(居中处于0)的研究,代表了什么?
修剪和填补方法在检测和纠正效应量估计方面有何特点?
当使用PET-PEESE方法时,如果元分析中的研究数量很少,什么是需要重点考虑的?
从p-curve分析报告的两个检验中,我们可以得出哪些结论?