3 等价检验和区间假设检验
大多数学术研究旨在检验对某个效应或差异是否存在的假说。新的干预措施有效吗?两个变量之间有关系吗?这些研究通常采用零假设显著性检验进行分析。当观察到具有统计学意义上显著的p值时,这个零假设便可被拒绝。同时,研究者可以在承认最大错误率的前提下声称干预有效,或两个变量之间存在关联。但是,如果p值在统计意义上不显著,研究者往往会得出一个逻辑上不正确的结论:那就是他们基于p > 0.05的结果而得出效应不存在的结论。
打开你正在写的论文的结果部分,或者你最近读过的某篇论文的结果部分。搜索”p >0.05”,仔细观察你或这位学者得出的结论(在结果部分,但也请观察他们在讨论部分的说法)。如果你看到”没有效应”或”变量之间没有关联”的结论,那么你就发现了一个典型案例,即研究者忽略了缺乏证明并不意味着不存在(Altman & Bland, 1995)。一个不显著的结果本身只是告诉我们不能拒绝零假设而已。在观察到p >0.05之后,“效应真的为零吗?”成为了值得思索的问题,但零假设显著性检验的p 值却不能回答这个问题。因此,在得到p>0.05后,可以将是否存在效应这一问题的答案视为”未定论”(mu),即一种非二元回答,不是”是”,不是”否”,也不是”未提出问题”。总之,仅基于p>0.05,并无法证明是否存在有意义的效应。
在许多情况下,研究者都应该对是否存在有意义的效应感兴趣。举个例子来说,证明可能成为混淆变量的因素在两个组别内没有差异是很重要的(例如,在积极情绪和消极情绪的实验操纵下,疲劳这一混淆变量不会影响当下的实验操纵)。研究者可能想知道两种干预措施是否同样有效,尤其是当新的干预措施成本更低或更加省力(例如,线上诊疗和线下诊疗一样有效吗?)。或者,在某些情况下我们会想证明效应不存在,比如理论模型预测效应不存在,或当我们认为之前发表的研究是假阳性的,我们会希望通过重复研究证明效应不存在(Dienes, 2014)。然而,如果你问研究者是否设计过旨在证明效应不存在的研究,比如研究假设为两种条件下没有差异,许多人会说他们从未设计过这种为了验证效应量为0的研究。研究者几乎总是猜想差异是存在的,原因之一可能是许多人甚至不知道如何从统计学上为效应量为0提供支持,因为他们没有接受过等价检验相关训练。
证明一个效应大小”正好”为零是永远不可能的。即便你从世界每个人那里收集数据,所得到的任 意一项研究的效应量都会在0左右随机变化——对于任何有限的样本来说,你最终可能都将得到非常接近但不完全为0的平均数差异。Hodges & Lehmann (1954) 是第一个讨论检验两个群体是否具有相同均值这一统计问题的人。他们建议(第264页):“检验两组的均值差异不超过特定数值,用来在实际操作中表示最小差异”。Nunnally (1960) 同样提出了一个”固定增量”的假设,即研究者将观察到的效应与一个被认为太小而没有意义的数值范围进行比较。定义一个数值范围,范围内的值在实际意义上代表没有效应,此范围就被称为等价范围 (Bauer & Kieser, 1996) 或实际等价区域 (Kruschke, 2013)。等价范围应提前规定,并需要仔细考虑最小感兴趣区。
尽管研究者一再试图在社会科学领域中引入针对等价范围的检验 (Cribbie et al., 2004; Hoenig & Heisey, 2001; Levine et al., 2008; Quertemont, 2011; Rogers et al., 1993), 但这种统计方法直到最近才流行起来。在可重复性危机期间,研究者们在进行重复研究时需寻找用于解释无效结果的工具。研究者们希望在重复他们怀疑是假阳性的研究结论时,能够提出无效结果的声明,并有一定的证据给予支持。一个著名的例子是Daryl Bem对前认知的研究,该研究表面上证明了被试能够预测未来(Bem, 2011)。等价检验作为一种统计方法被提出,用于回答观察到的效应量是否足够小到无法重复得出前人的研究结论(Anderson & Maxwell, 2016; Lakens, 2017; Simonsohn, 2015)。研究者会指定最小感兴趣区(例如0.5的效应量,即对于双侧检验来说,是在-0.5到0.5范围之外的任何值),并检验是否可以拒绝比这个范围更极端的效应。如果是这样,他们可以拒绝那些被认为足够大而有意义的效应的存在。
人们可以将零效应的原假设(nil null hypothesis)与非零效应的原假设(non-nil null hypothesis)区分开来,其中零效应的原假设是效应正好为0,非零效应的原假设是除0之外的任何其他效应,例如比最小感兴趣区更极端的效应(Nickerson, 2000)。正如尼克森所写:
这是一个很重要的区分,特别是当涉及到对NHST优缺点的争议时。有些批评针对零效应的原假设很有用,但在非零效应的原假设的情境下,由于后者更为宽泛,有时那些批评并不那么具有建设性。
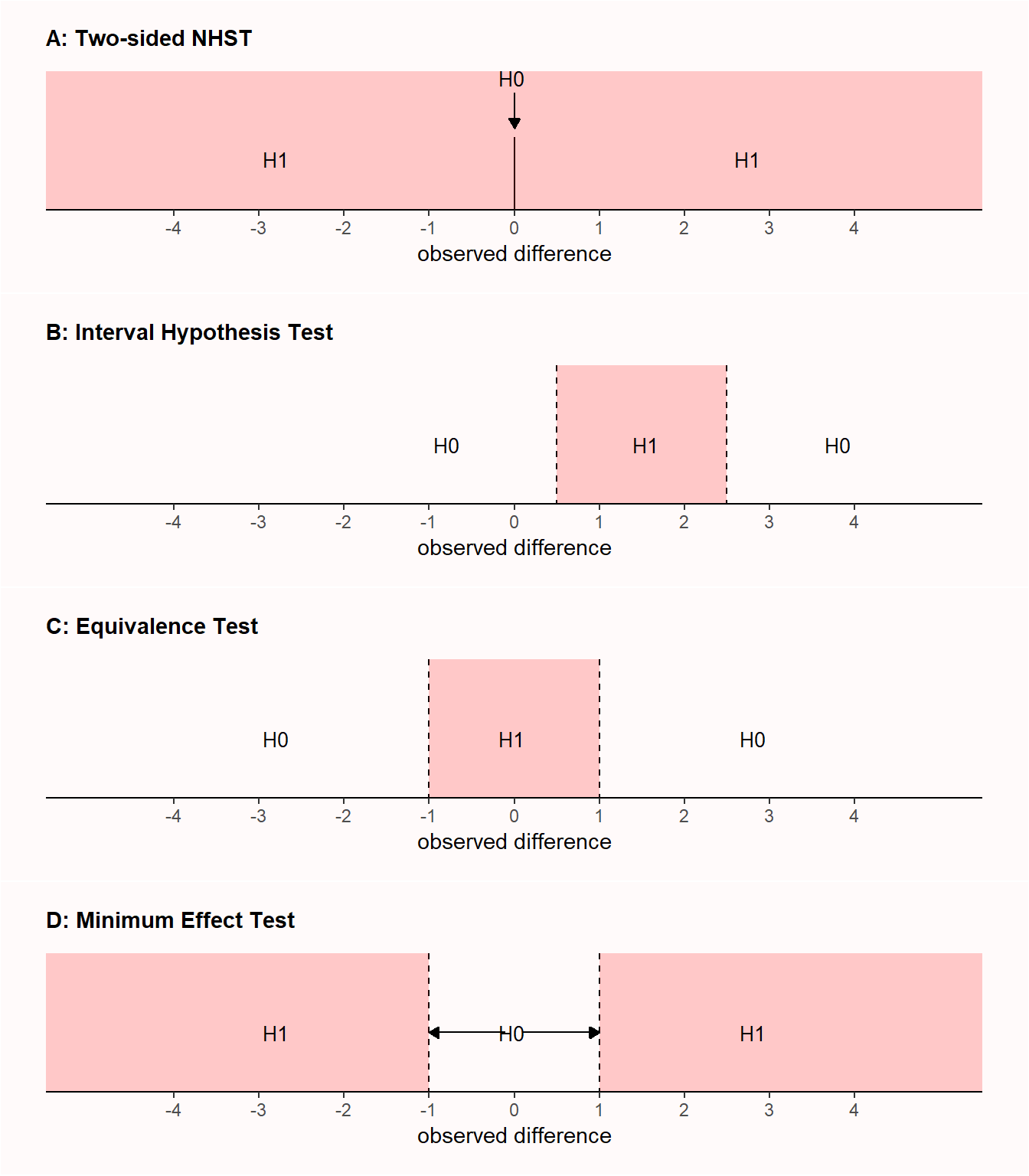
等价检验是区间假设检验的一种具体实现形式,它不是针对零效应的原假设进行检验(即,效应量为0的零效应的原假设),而是针对非零效应的原假设的某个区间进行检验(即,非零假设的原假设)。其实在针对零假设显著性检验的局限性而提出的改进建议中,最广泛出现的就是使用区间假设检验中的范围检验来代替效应为0的零假设检验(Lakens, 2021)。为了说明这种差异,Figure 3.1 中的图A显示了双侧零效应的原假设检验结果,检验效应为0的原假设是否能被拒绝。图B为区间假设检验,检验效应落在0.5-2.5之间时,检验能否拒绝小于0.5或大于2.5的值。图C为等价检验,它基本上与区间假设检验相同,但效应落在0左右的范围内,其值被认为太小而没有意义的效应。
将等价检验进行翻转,意味着研究者设计了一项研究来拒绝比最小感兴趣区还小的那些值,这被称为最小效应量检验(Murphy & Myors, 1999)。研究者可能不仅想要拒绝一个效应为0的假设(如零假设显著性检验),而且也想拒绝那些太小而没有意义的效应区间。在其他条件相同的情况下,相比于那些想拒绝0效应假设的研究,旨在拒绝最小效应区间并具有高统计检验力的研究则需要更多的观测值,因为后者的置信区间需要拒绝的值更接近观测到的效应量(例如,0.1而不是0),置信区间会变得更窄,这就需要更多的观测值。
与零假设检验相比,最小效应量检验的一个好处是在统计显著性和实际显著性之间没有区别。由于检验值被选择来表示最小感兴趣效应,无论何时被拒绝,这种影响在统计上和实际上都是显著的(Murphy et al., 2014)。最小效应量检验的另一个好处是,在社会科学领域的相关研究中,变量通常通过因果结构相互联系,导致变量之间存在真实但实际上我们并不感兴趣的非零相关性,这被称为”混杂因素”(crud factor)(Meehl, 1990; Orben & Lakens, 2020)。由于0效应在大型相关数据集中可能不会成立,因此拒绝零效应的原假设并不是一个严格的检验。即使假设不正确,0效应的假设也可能因”混杂因素”而被拒绝。因此一些研究者建议针对r = 0.1的最小效应进行检验,由于变量之间在理论上不相关,低于该阈值的相关性将非常常见(Ferguson & Heene, 2021)。
图@fig-intervaltest 表示了双侧检验,但做单侧检验通常更直观、更合乎逻辑。例如,最小效应量检验的目标是拒绝小于0.1的效应,而等价检验的目标是拒绝大于0.1的效应。与其指定范围的上限和下限,不如为单侧检验指定一个值。单侧非零效应的原假设检验的一种变式被称为非劣效性检验,它检验效应是否大于等价范围的下限。例如,当一种新的干预措施不应该明显比现有的干预措施差,但可能会差一点点时,就可以进行这样的测试。例如,如果新的干预措施和现有的干预措施之间的差异不小于-0.1,并且小于-0.1的效应可以被拒绝,则可以得出结论,效果是非劣效的(Mazzolari et al., 2022; Schumi & Wittes, 2011)。我们发现,将零效应的原假设扩展到非零效应的原假设可以让研究者提出可能更有趣的问题。
3.1 等价检验
等价检验最早是在药物学中发展起来的(Hauck & Anderson, 1984; Westlake, 1972),后来正式成为等价检验的双单侧检验(TOST)方法(Schuirmann, 1987; Seaman & Serlin, 1998; Wellek, 2010)。TOST程序需要进行两次单侧检验,以检验观察到的数据是否出乎意料地大于等价下限(\(\Delta_{L}\)), 或者出乎意料地小于等价上限(\(\Delta_{U}\)):
\[ t_{L} = \frac{{\overline{M}}_{1} - {\overline{M}}_{2} - \Delta_{L}}{\sigma\sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}}}} \]
和
\[ t_{U} = \frac{{\overline{M}}_{1} - {\overline{M}}_{2}{- \Delta}_{U}}{\sigma\sqrt{\frac{1}{n_{1}} + \frac{1}{n_{2}}}} \]
其中M表示每个样本的平均值,n是样本量,σ是合并的标准偏差:
\[ \sigma = \sqrt{\frac{\left( n_{1} - 1 \right)\text{sd}_{1}^{2} + \left( n_{2} - 1 \right)\text{sd}_{2}^{2}}{n_{1} + \ n_{2} - 2}} \]
如果这两个单侧检验都是显著的,我们就可以拒绝接受存在足够大而有意义的效应。这些公式与统计量t的一般公式十分相似。NHST t检验和TOST程序之间的区别在于,NHST t检验从组别之间的平均差中减去了等价下限和等价上限(在正常的t检验中,我们将平均差与0进行比较,因此∆从公式中剔除,因为它是0)。
要进行等价检验,你不需要学习任何新的统计检验,因为它只是针对不同于0的值进行的众所周知的t检验。但令人惊讶的是,使用t检验进行等价检验并没有像在零假设显著性检验中使用t检验那般进行同步教学,因为有迹象表明,这可以防止对p值的常见误解(Parkhurst, 2001)。让我们来看一个使用TOST程序进行等价检验的例子。
在一项研究中,研究者通过让被试搬运沉重的盒子来操纵疲劳程度,并希望确保这种操纵不会无意中改变被试的情绪。研究者评估了这两种情况下的积极情绪和消极情绪,并希望能够声称积极情绪在两种情况下没有差异。让我们假设实验性疲劳条件下的积极情绪(\(m_1\) = 4.55, \(sd_1\) = 1.05, \(n_1\) = 15)与控制组条件下的情绪(\(m_2\) = 4.87, \(sd_2\) = 1.11, \(n_2\) = 15)没有差异。为此,研究者得出结论:“不同条件下的情绪没有差异,t=-0.81,p=.42”。当然,不同条件下的情绪确实不同,因为4.55-4.87=-0.32。而这种说法是指两种情绪的差异无意义,如果要以正确的方式得出这样的结论,我们首先需要指定什么程度的情绪差异才能被视为是有意义的。目前,我们假设,研究者认为小于半个刻度点(即0.5)的效应都太小,因而没有意义。我们现在检验观察到的-0.32的平均差异是否足够小,以便我们可以去拒绝大到需要重视的效应的存在。
TOSTER软件包(最初由我创建,但最近由Aaron Caldwell重新设计)可用于绘制两个t分布及其临界区域的图表,这将指示我们何时可以拒绝小于-0.5和大于0.5的效应。我们可能需要一些时间来习惯这样一种想法,即我们拒绝的值比等价边界更极端。在任何假设检验中,始终尝试提问:检验可以拒绝哪些值?在零效应的原假设中,我们可以拒绝效应为0的假设,在下图的等价检验中,可以拒绝低于-0.5和高于0.5的值。在图 Figure 3.2 中,我们可以看到两个t分布集中在指定等价范围的上限和下限(-0.5和0.5)。
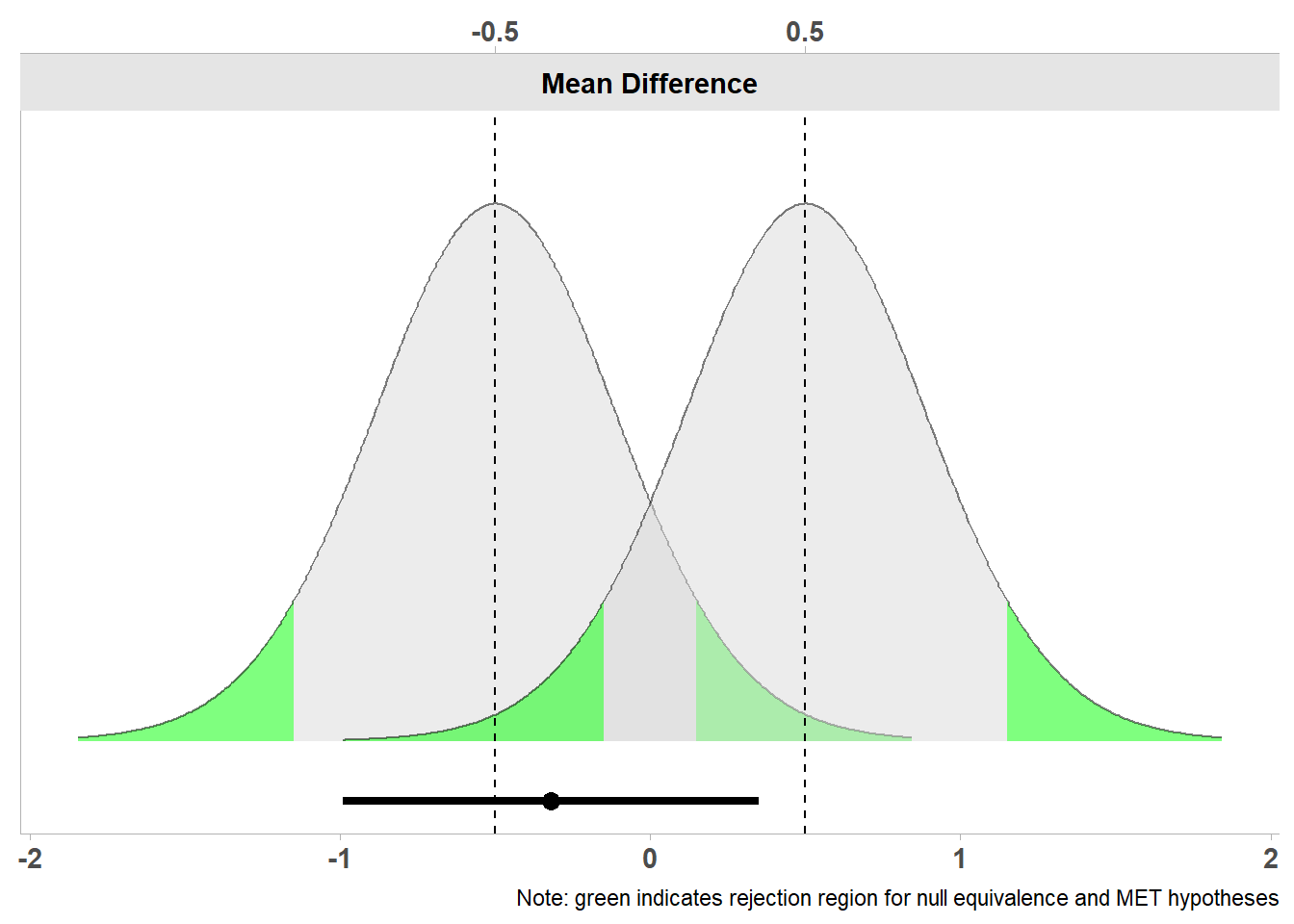
在这两条曲线之下,我们看到一条横线表示 -0.99 至0.35的置信区间,线上的一个点表示观察到的 -0.32的平均差异。让我们先看看左边的曲线。我们在尾部看到绿色高亮的区域,该区域显示了哪些平均差异将非常极端,足以在统计上拒绝-0.5的效应。我们所得到的-0.32的平均差异非常接近-0.5,如果只看左边的分布,均值差离-0.5还不够远,远到足以落在表明所得差异何时具有统计学意义的绿色区域。我们还可以使用TOSTER包进行等价检验,并查看结果。
TOSTER::tsum_TOST(m1 = 4.55,
m2 = 4.87,
sd1 = 1.05,
sd2 = 1.11,
n1 = 15,
n2 = 15,
low_eqbound = -0.5,
high_eqbound = 0.5)
Welch Modified Two-Sample t-Test
The equivalence test was non-significant, t(27.91) = 0.456, p = 3.26e-01
The null hypothesis test was non-significant, t(27.91) = -0.811, p = 4.24e-01
NHST: don't reject null significance hypothesis that the effect is equal to zero
TOST: don't reject null equivalence hypothesis
TOST Results
t df p.value
t-test -0.8111 27.91 0.424
TOST Lower 0.4563 27.91 0.326
TOST Upper -2.0785 27.91 0.023
Effect Sizes
Estimate SE C.I. Conf. Level
Raw -0.3200 0.3945 [-0.9912, 0.3512] 0.9
Hedges's g(av) -0.2881 0.3930 [-0.8733, 0.3021] 0.9
Note: SMD confidence intervals are an approximation. See vignette("SMD_calcs").在”t检验”一行中,输出结果显示了传统零效应的原假设的显著性检验(我们已经知道这在统计学上并不显著:t=0.46,p=0.42。就像R中的默认t检验一样,tsum_TOST函数在默认情况下会计算Welch’s t检验(而不是Student’s t检验),这是一个更好的默认值(Delacre et al., 2017),但你可以通过添加var.equal = TRUE作为函数的参数来请求进行Student’s t检验。
我们还看到TOST Lower所示的检验。这是第一次单侧检验,检验我们是否可以拒绝低于-0.5的效应。从检验结果来看,情况并非如此:t=0.46,p=0.33。这是一个普通的t检验,只是针对-0.5的效应。因为我们不能拒绝比-0.5更极端的差异,所以可能存在我们认为有意义的差异(例如,-0.60的差异)。当我们观察等价范围上限(0.5)的单侧检验时,我们可以从统计学上拒绝大于0.5的情绪效应的存在,正如在TOST upper行中我们看到的t=-2.08,p=0.02。因此,我们的最终结论是,即使我们可以根据观察到的-0.32的平均差异来拒绝比0.5更极端的效应,我们也不能拒绝比-0.5更极端的效应。因此,我们不能完全拒绝有意义的情绪效应的存在。由于数据不允许我们声称效应与0有所不同,也不允许我们说效应太小而无关紧要(基于-0.5到0.5的等价范围),因此数据是不确定的。我们无法区分Ⅱ类错误(存在效应,但在这项研究中,我们只是没有检测到它)或真正的阴性(确实没有足够大到要去重视的效应)。
请注意,由于我们未能拒绝针对等价下限的单侧检验,因此仍有可能存在足够大以至于被认为是有意义的真实效应量。这种说法是正确的,即使我们观察到的效应大小(-0.32)比-0.5的等价边界更接近于零。有人可能认为,所得到的效应大小需要比等价边界更极端(即<-0.5或>0.5),这样才有可能存在一个大到足以被认为有意义的效应。但这并不是必须的。90%的置信区间说明了不能拒绝低于-0.5的某些值。正如我们预期所示,从长远来看,90%的置信区间捕捉到了真实的总体参数,真实的效应大小完全有可能比-0.5更极端。而且,这种效应甚至可能比这个置信区间捕获的值更极端,因为在10%的概率下,计算的置信区间不包含真实的效应量。因此,当我们不能拒绝最小感兴趣区时,我们扔保留了存在效应的可能性。如果我们可以拒绝零效应的原假设,但不能拒绝比等价边界更极端的值,那么我们可以声称效应存在,并且它可能足够大,大到有意义。
降低效应不确定概率的一种方法是收集充分的数据。让我们想象一下,研究者并没有在每种情况下只收集15名被试,而是收集了200名被试。除此之外,他们观察到的数据完全相同。正如confidence intervals一章中所解释的,随着样本量的增加,置信区间变得越来越窄。为了使TOST等价检验能够拒绝等价范围的上限和下限,置信区间需要完全落在等价范围内。在图 Figure 3.3 中,我们看到了与图 Figure 3.2 相同的结果,但现在如果我们收集了200个数据。由于样本量较大,置信区间比我们收集15名被试时更窄。我们看到,观察到的平均差周围的90%置信区间现在排除了等价上限和等价下限。这意味着我们现在可以拒绝等价范围之外的效应(尽管很勉强,因为对等价下限的单侧检验仅具有统计学意义,p=0.048)。
Welch Modified Two-Sample t-Test
The equivalence test was significant, t(396.78) = 1.666, p = 4.82e-02
The null hypothesis test was significant, t(396.78) = -2.962, p = 3.24e-03
NHST: reject null significance hypothesis that the effect is equal to zero
TOST: reject null equivalence hypothesis
TOST Results
t df p.value
t-test -2.962 396.8 0.003
TOST Lower 1.666 396.8 0.048
TOST Upper -7.590 396.8 < 0.001
Effect Sizes
Estimate SE C.I. Conf. Level
Raw -0.3200 0.108 [-0.4981, -0.1419] 0.9
Hedges's g(av) -0.2956 0.104 [-0.4605, -0.1304] 0.9
Note: SMD confidence intervals are an approximation. See vignette("SMD_calcs").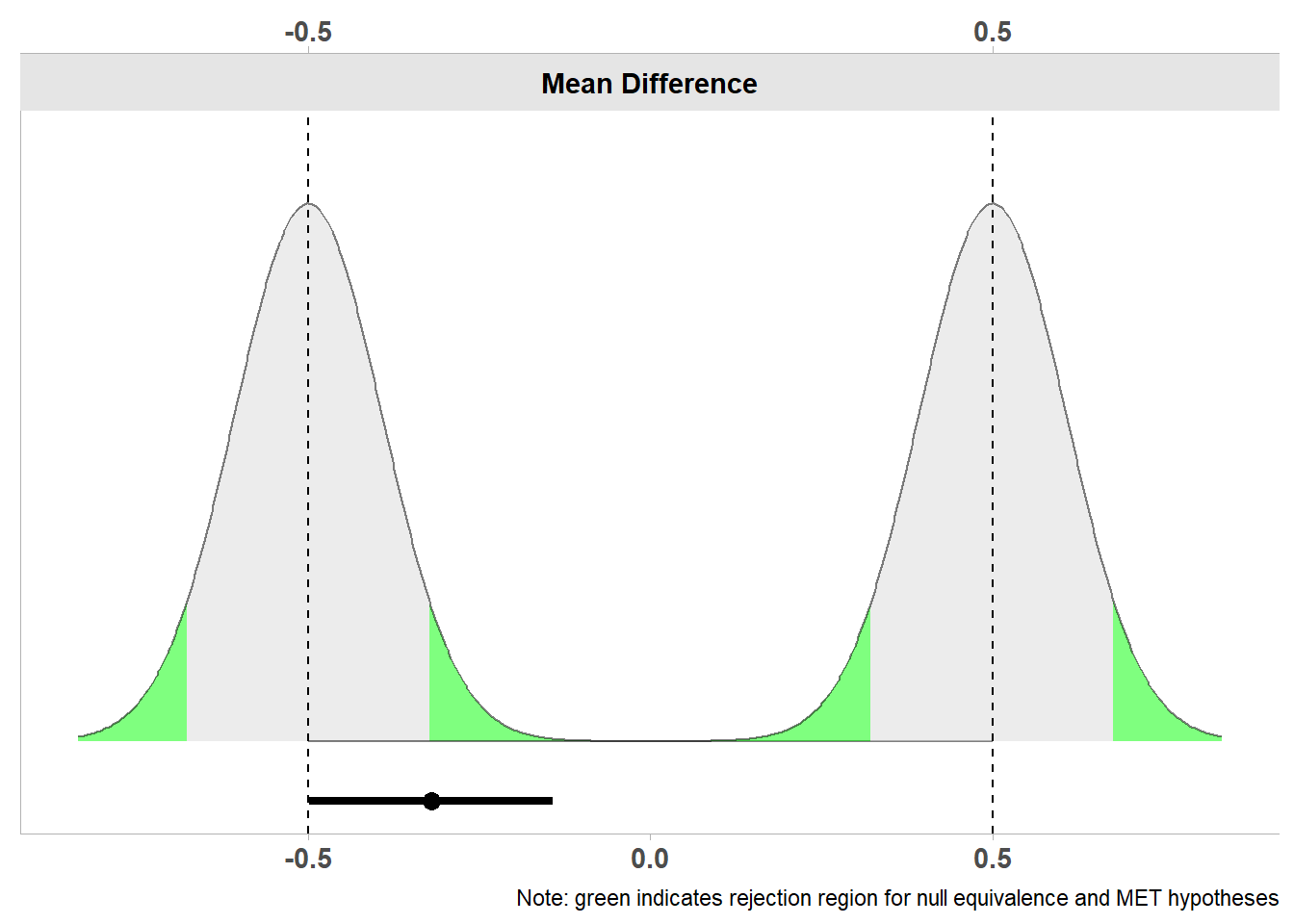
在图 Figure 3.4 中,我们看到了相同的结果,但现在可视化为置信密度图(Schweder & Hjort, 2016),这是置信度分布的图形总结。置信密度图允许你查看哪些效应可以通过不同的置信区间宽度来拒绝。我们看到绿色区域的边界(对应于90%的置信区间)落在等价边界内。因此,等价检验在统计学上是显著的,我们可以在统计学上拒绝存在等价范围之外的效应。我们还可以看到,95%的置信区间排除了0,因此,传统的零假设显著性检验也具有统计学意义。
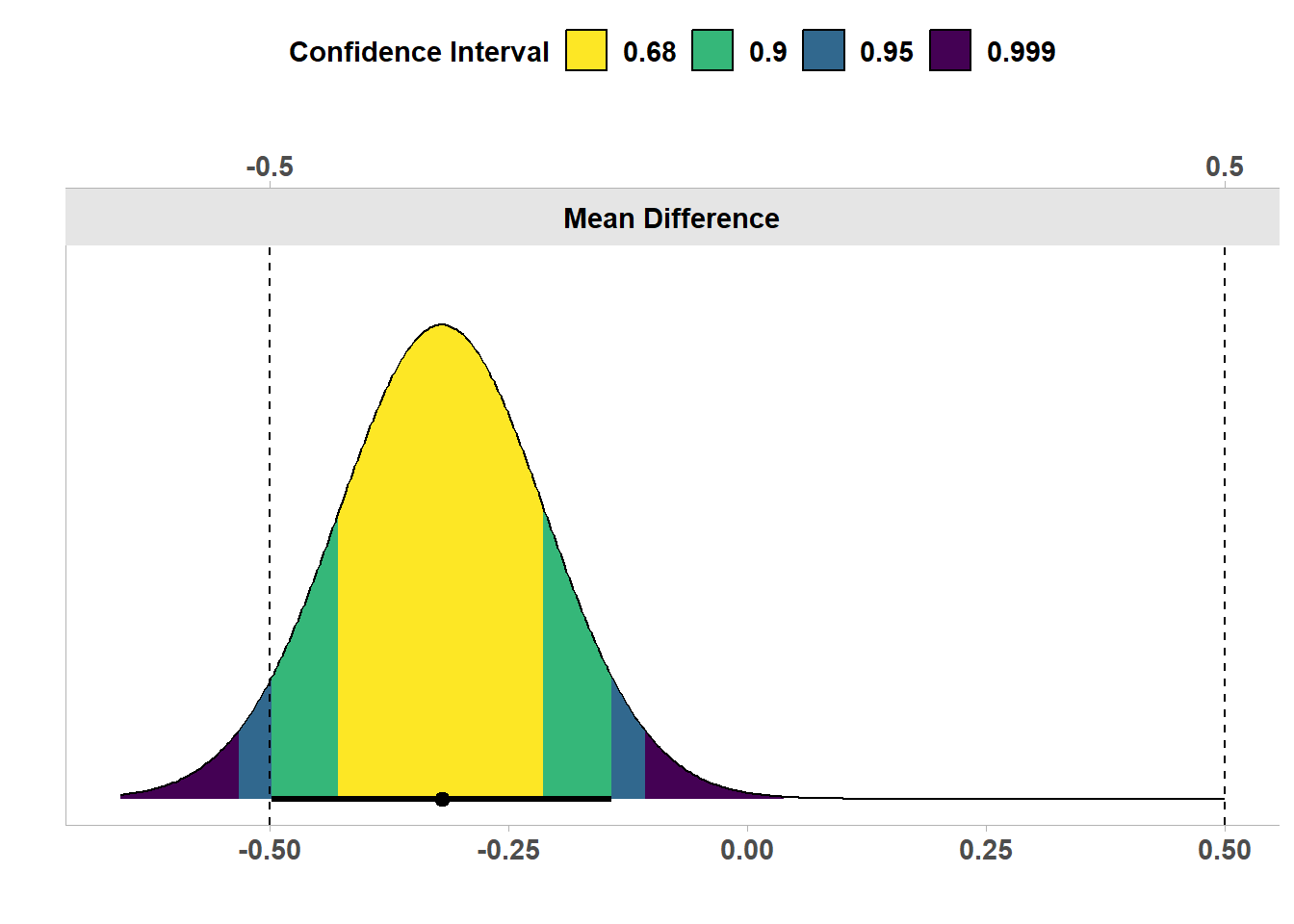
换句话说,零假设检验和等价检验都产生了显著的结果。这意味着我们可以声称,所观察到的效应在统计学上与0不同,并且在统计上,该效应小于我们在指定的-0.5到0.5的等效区间时认为的大到足够重要的效应。这说明了将等价检验和零效应的原假设相结合可以防止我们误将具有统计学意义的效应当成实际上显著的效应。在这种情况下,有200名被试,我们可以拒绝一个为0的效应,但这个效应(如果有的话)没有大到是有意义的。
3.2 报告等价检验
在报告等价检验时,通常只报告两个单侧检验中产生较高p值的检验。因为两个单侧检验都需要具有统计学意义,才能在等价检验中拒绝零假设(即存在足够大的效应),所以当两个假设检验中较大的一个拒绝等价边界时,另一个检验也会拒绝。与零假设显著性检验不同的是,报告等价检验的标准化效应量并不常见,但在某些情况下,研究者可能想讨论当前效应与等价边界初始度量的差距有多远。防止例如声称’没有效应’、效应’不存在’、真实效应量为’0’这样错误的解释,或两组数据”相似”或”可比”这样模糊的口头描述。显著的等价检验会拒绝比等价边界更极端的效应。较小的真实效应没有被拒绝,因此仍然有可能存在真实效应。因为TOST程序是一种基于p值的频率检验,所以也应该防止所有其他的对p值的误解。
在总结等价检验的主要结果时,例如在摘要中,始终要报告数据所检验的等价范围。比方说,等价边界为d -0.9至0.9,那么’基于等价检验,我们认为有意义的效应不存在’这个结论与等价边界为d = -0.2至d= 0.2时有着截然不同的意义。反之,应当写下’基于等价范围为d=-0.2至0.2的等价检验,我们认为有意义的效应不存在’。当然,同行们是否同意你正确地得出了有意义效应不存在的结论,取决于他们是否同意你对最小感兴趣效应的证明!一个更中性的陈述是这样的:“基于等价检验,我们拒绝了比-0.2到0.2更极端效应的存在,所以我们可以(在错误率为α下)认为,这种效应(如果存在)的极端程度小于我们的等价范围”。在这里,你没有使用诸如’有意义’之类的充满价值的话术。如果零假设检验和等价检验都是不显著的,那么这一发现最好被描述为’不确定的’:没有足够的数据来拒绝零假设,或者最小感兴趣区。如果零假设检验和等价检验都具有统计学意义,你可以声称效应存在,但同时声称效应太小,不值得关注(考虑到你对等价范围的证明)。
等价边界可以用原始效应量或标准化平均差来表示。最好根据原始效果量来定义等价边界。依据Cohen’s d设置等价边界会导致统计检验的偏差,因为必须使用观察到的标准差来指定的Cohen’s d转换为等价检验的原始效应量(当你在标准化平均差中设置等价边界时,TOSTER将警告:“警告:将边界类型设置为SMD会产生偏差结果!”)。在实践中,偏差在任何单一的等价检验中都不会有太大的问题,并且在不知道标准差的情况下,用标准化平均差来设定等价边界也降低了进行等价检验的门槛。但是,随着等价检验变得越来越流行,并且领域建立了最小感兴趣区,则应该使用原始效应量差异,而不是标准化效应量差异。
3.3 最小效应量检验
如果研究者指定了最小感兴趣区,并且有兴趣检验群体中的效应是否大于该最小感兴趣效应,则可以进行最小效应量检验。与任何假设检验一样,只要观察到的效应与其周围的置信区间不重叠,我们就可以拒绝最小感兴趣效应。然而,在最小效应量检验的情况下,最小感兴趣效应应该完全落在置信区间外。例如,让我们假设一名研究者对平均差异为0.5的最小效应量进行最小效应量检验,每个条件有200个观察结果。
Welch Modified Two-Sample t-Test
The minimal effect test was significant, t(396.78) = 12.588, p = 4.71e-04
The null hypothesis test was significant, t(396.78) = 7.960, p = 1.83e-14
NHST: reject null significance hypothesis that the effect is equal to zero
TOST: reject null MET hypothesis
TOST Results
t df p.value
t-test 7.960 396.8 < 0.001
TOST Lower 12.588 396.8 1
TOST Upper 3.332 396.8 < 0.001
Effect Sizes
Estimate SE C.I. Conf. Level
Raw 0.8600 0.108 [0.6819, 1.0381] 0.9
Hedges's g(av) 0.7945 0.125 [0.6234, 0.9646] 0.9
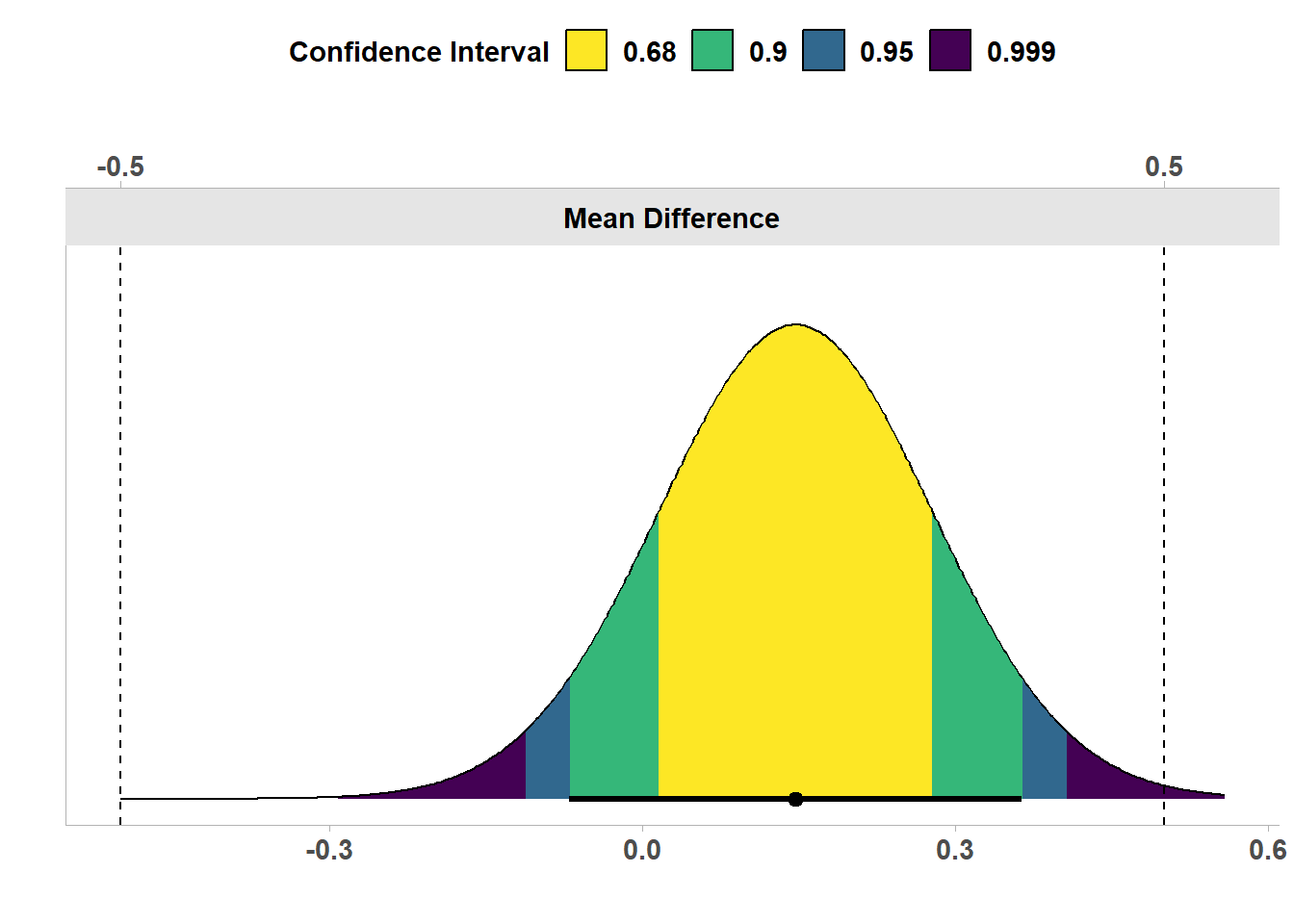
Note: SMD confidence intervals are an approximation. See vignette("SMD_calcs").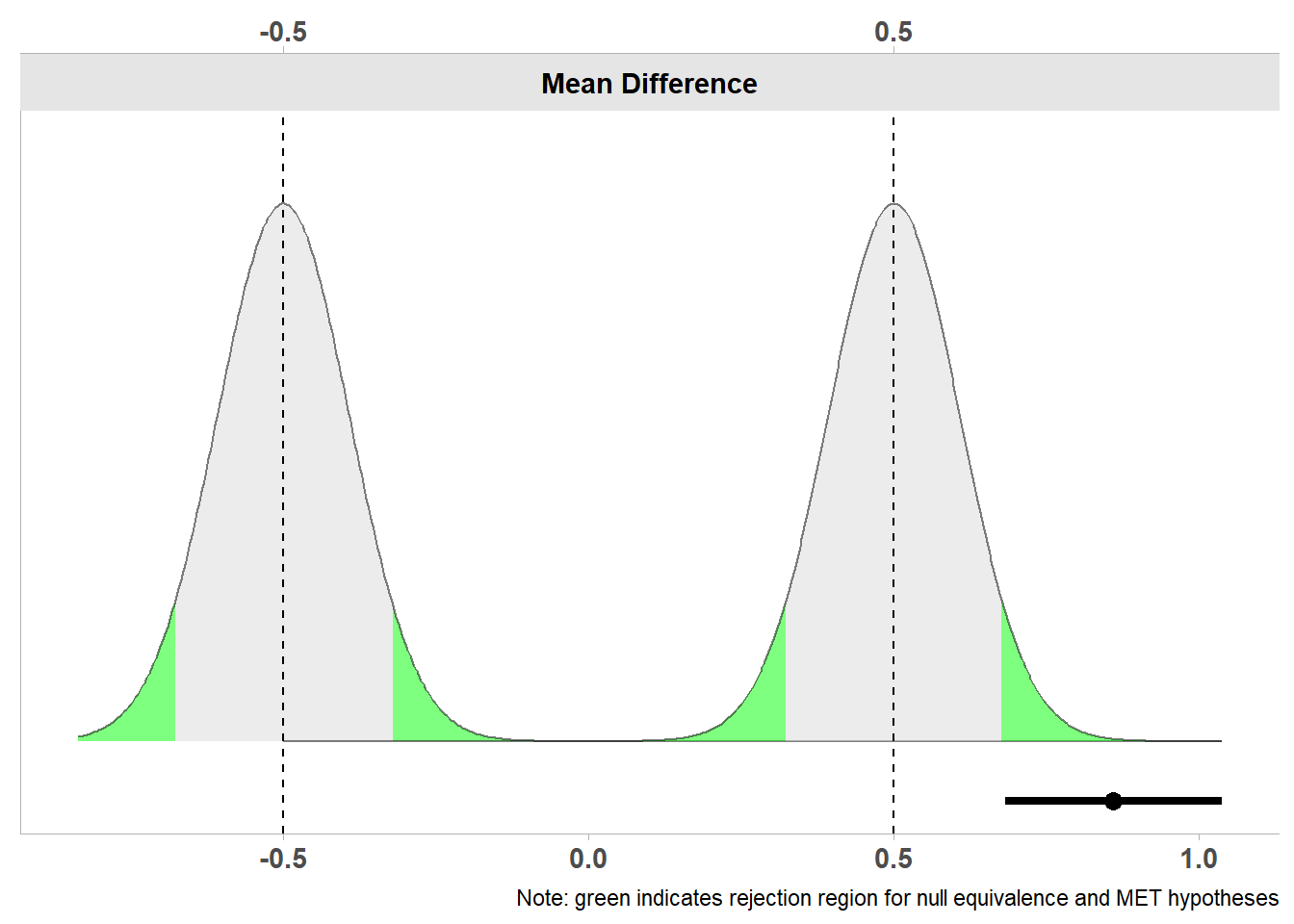
在这两条曲线下面,我们再次看到一条横线,它代表的置信区间从0.68至1.04,以及线上的点表示观察到的平均差0.86。整个置信区间远大于0.5的最小效应,因此我们不仅可以拒绝零效应的原假设,而且可以拒绝小于最小感兴趣效应的效应。因此,我们可以声称这种效应足够大,不仅在统计上具有显著性,而且在实践中也很有意义(只要我们很好地证明了我们最小感兴趣区)。因为我们进行了双侧最小效应量检验,如果置信区间完全在-0.5的另一侧,最小效应量检验也是显著的。
前面我们讨论了如何将传统的NHST和等价检验相结合,从而获得更多具有参考价值的结果。我们也可以将最小效应量检验和等价检验相结合。甚至可以说,无论何时,只要可以指定最小感兴趣效应大小,这种组合都是信息量最为丰富的检验。原则上,这是真实的。只要我们能够收集到足够的数据,当我们将最小效应量检验与等价检验相结合时,我们总是会得到一个信息丰富、直截了当的答案:要么我们可以拒绝所有太小而不关注的效应,要么我们可以拒绝所有足够大而值得关注的效应。正如我们将在下文关于区间假设的统计检验力分析一节中所看到的那样,每当真实效应量接近最小感兴趣区时,都需要收集大量的观测结果。如果真实效应量恰好与最小感兴趣区相同,则最小效应量检验和等价检验都不能被正确拒绝(任何显著的检验都将是Ⅰ型错误)。如果研究者能够收集充分的数据(从而使检验具有很高的统计检验力),并且相对确信真实效应量将大于或小于最小感兴趣效应,那么最小效应量检验和等价检验的组合可能很有吸引力,因为这样的假设检验可能会为研究问题提供信息丰富的答案。
3.4 区间假设检验的检验力分析
在设计研究时,一种明智的策略是始终同时计划效应存在与不存在两种情况。一些期刊要求对注册报告提供样本量的合理性证明,对于这些注册报告,其拒绝零假设的统计检验力很高,但研究也能够证明不存在效应。例如,同时对等价检验进行检验力分析。正如我们在误差控制和似然性的章节中看到的那样,零效应是意料之中的,如果您在收完数据后才考虑观察到零效应的可能性,通常为时已晚。
区间假设的统计检验力取决于α水平、样本量、您决定检验的最小感兴趣效应以及真实效应大小。对于等价检验,通常假定真实效应大小为0来进行统计检验力分析,但有时可能并不现实。预期效应量越接近最小感兴趣区,需要达到所需统计检验力的样本量就越大。如果您有充分的理由预期一个小但非零的真实效应量,请不要试图假定真实效应量为0。统计检验力分析可能会表明您需要收集的样本量较小,但实际上您也更有可能得到不确定的结果。早期版本的 TOSTER 仅允许研究者在假设真实效应大小为 0 的情况下对等价检验进行统计检验力分析,但 Aaron Caldwell 的新统计检验力函数允许用户指定 delta,即预期的效应量。
假设研究者希望等价检验达到 90% 的统计检验力,等价范围为 -0.5 到 0.5,α水平为 0.05,并假设总体效应量为 0。此时可以进行等价检验的检验力分析,从而确定所需的样本量。
TOSTER::power_t_TOST(power = 0.9, delta = 0,
alpha = 0.05, type = "two.sample",
low_eqbound = -0.5, high_eqbound = 0.5)
Two-sample TOST power calculation
power = 0.9
beta = 0.1
alpha = 0.05
n = 87.26261
delta = 0
sd = 1
bounds = -0.5, 0.5
NOTE: n is number in *each* group我们看到,对于独立样本t检验,所需的样本量为每个条件88名被试。现在,让我们将这个检验力分析与研究者预期真实效应为d= 0.1的情况进行比较,而不是真实效应为0。为了能够可靠地拒绝大于0.5的效应,我们将需要更大的样本量,就像我们需要更大的样本量去测出d = 0.4的零假设检验,而不是d = 0.5的零假设一样。
TOSTER::power_t_TOST(power = 0.9, delta = 0.1,
alpha = 0.05, type = "two.sample",
low_eqbound = -0.5, high_eqbound = 0.5)
Two-sample TOST power calculation
power = 0.9
beta = 0.1
alpha = 0.05
n = 108.9187
delta = 0.1
sd = 1
bounds = -0.5, 0.5
NOTE: n is number in *each* group我们可以看到,现在每个条件下的样本量都增加到了109人。如前所述,没有必要进行双侧等价检验。执行单侧等价检验是有可能的。复制研究就是适合进行这种方向性检验的一个例子。如果之前的一项研究观察到d = 0.48的效应,而你进行了一项重复研究,你可能会决定将任何小于d = 0.2的效应视为复制失败,包括任何反方向的效应,如d = -0.3的效应。虽然大多数等价检验软件都要求你指定等价范围的上下限,但你可以模拟单侧检验,将你想忽略的方向上的等价范围设置为一个较低的值,这样针对该值的单侧检验将始终具有统计学意义义。这也可以用来执行最小效应量检验的检验力分析,其中一个界限是最小感兴趣效应,另一个界限则设置为预期效应量的另一侧的极端值。
在如下等价检验的统计检验力分析示例中,下限被设定为-5(应该设置得足够低,以至于进一步降低也不会有明显影响)。我们可以看到,TOSTER软件包中的新统计检验力函数考虑了方向性预测,与在零效应的原假设检验中的方向性预测一样,等价检验中的方向性预测更有效,且只需要70个观测值即可达到90%的统计检验力。
# New TOSTER power functions allows power for expected non-zero effect.
TOSTER::power_t_TOST(power = 0.9, delta = 0,
alpha = 0.05, type = "two.sample",
low_eqbound = -5, high_eqbound = 0.5)
Two-sample TOST power calculation
power = 0.9
beta = 0.1
alpha = 0.05
n = 69.19784
delta = 0
sd = 1
bounds = -5.0, 0.5
NOTE: n is number in *each* group统计软件为某些统计检验提供了统计检验力分析选项,但并非所有检验都有。就像零假设检验的统计检验力分析一样,可能有必要使用基于模拟的方法进行统计检验力分析。
3.5 贝叶斯ROPE程序
在贝叶斯估计中,一种论证缺乏有意义效应的方法是实际等价区间(ROPE)程序(Kruschke (2013)),它”有点类似于频率学派的等价检验”(Kruschke & Liddell (2017))。在ROPE程序中,在 ROPE 程序中,与等价检验一样,也指定了等价范围,但使用的是基于后验分布的贝叶斯最高密度区间(如贝叶斯统计 章节所述)而不是置信区间。
如果Kruschke使用的先验分布完全一致,并且ROPE程序和等价检验使用相同的置信区间(例如90%),那么这两种检验将产生相同的结果。只是在如何解释数字上存在哲学差异。在R中可以使用BEST 软件包执行ROPE程序,该软件包默认使用”广义”的先验值,因此ROPE程序和等价检验的结果并不完全相同,但非常接近。甚至可以说这两种检验 “实际上是等价的”。下面的R代码生成了两个条件下的随机正态分布数据(均值为0,标准差为1),并执行了ROPE程序和TOST等价检验。
Waiting for parallel processing to complete...done.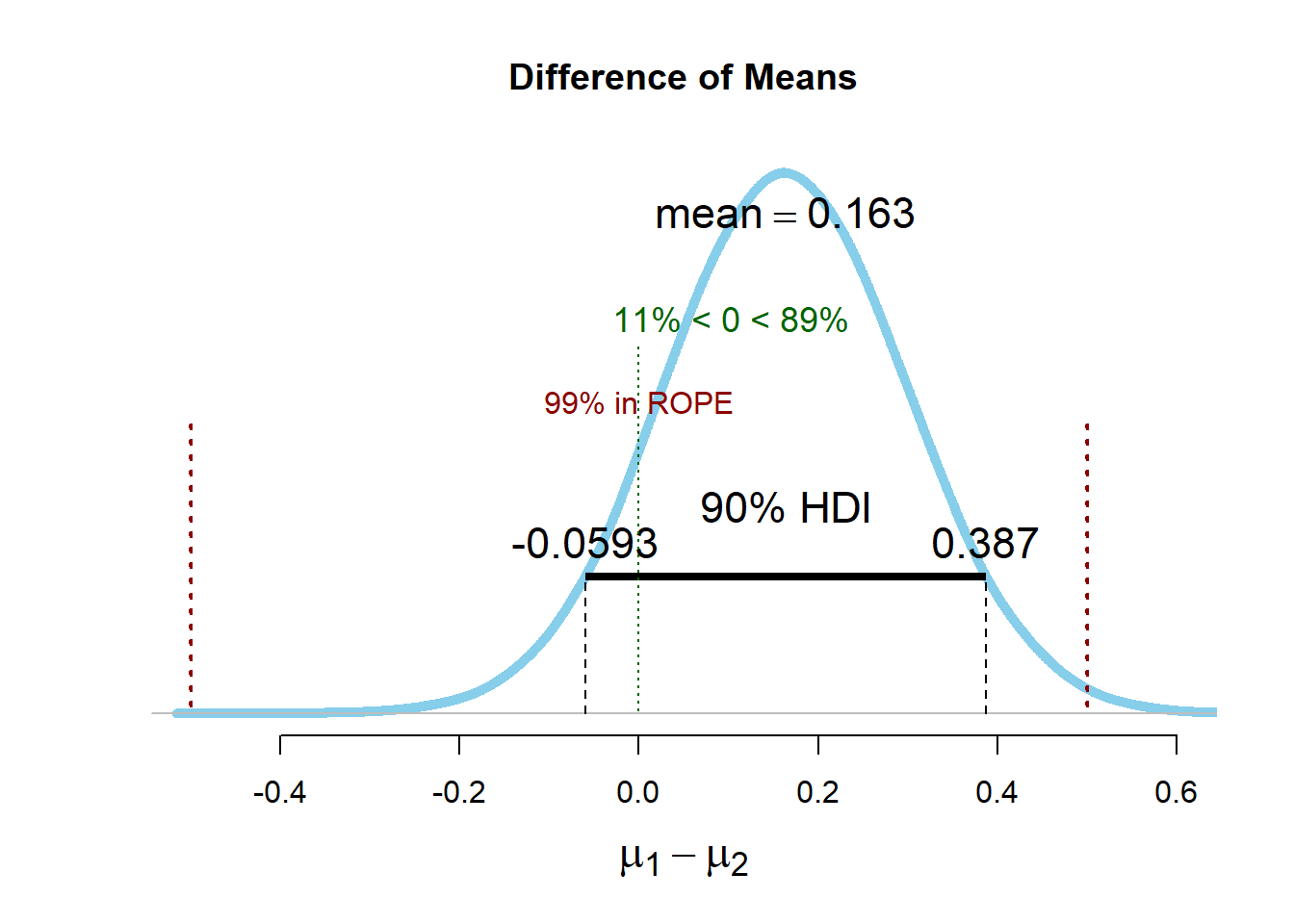
90% HDI范围在-0.06到0.39之间,基于先验值和数据估计的平均值为0.164。HDI完全落在等价范围的上限和下限之间,因此比-0.5或0.5更极端的值被认为是不可信的。95% CI范围从-0.07到 0.36 ,观察到的平均差异为0.15。我们看到,这些数字并不完全相同,因为在贝叶斯估计法中,观测值与先验值相结合,而平均值估计并不仅仅基于数据。但结果非常相似,在大多数情况下会得出相似的推论。BEST R软件包还能让研究者执行基于模拟的统计检验力分析,这种分析需要很长时间,但是使用广义先验时,其结果与等价检验的统计检验力分析的样本量基本相同。ROPE相对于TOST的最大优势在于它允许您纳入先验信息。如果你有可靠的先验信息,ROPE可以使用此信息,这在你没有大量数据时尤其有用。如果你使用的是知情先验,建议进行敏感性分析,检查后验在先验发生合理变化时的稳健性。
3.6 应该使用哪个区间宽度?
因为 TOST 程序基于两个单侧检验,所以当在 5% 的 alpha 水平下执行单侧检验时,将使用 90% 的置信区间。因为针对上限的检验和针对下限的检验都需要具有统计显著性才能声明等价(正如在误差控制 一章中所解释的那样,等价是多重检验的交-并集方法),所以不必因为进行了两次检验而修正结果。如果针对多重比较调整了 alpha 水平,或者如果 alpha 水平是合理的而不是依赖于默认的 5% 水平(或两种条件都满足),则应使用相应的置信区间,即CI = 100 - (2 * \(\alpha\))。因此,置信区间的宽度与alpha水平的选择直接相关,我们需要根据置信区间是否排除了所检验的效应来决定是否拒绝最小效应量。
当从贝叶斯角度出发使用最高密度区间时,比如ROPE程序,置信区间宽度的选择在逻辑上并不符合预期的错误率或任何其他原则。Kruschke(2014)写道:“我们应该如何定义’合理可信’?一种方法是说,任何在95% HDI内的点都是合理可信的。”McElreath (2016)推荐使用67%、89%和97%,他认为”没有什么理由,因为它们是质数便于记忆。” 这两种建议都缺乏坚实的依据。正如Gosset(笔名Student)观察到的(1904):
结果仅在它们与真相相差的程度足够小以至于在实验目的上可以忽略不计时才有价值。选定的机率应取决于以下两点: 1.实验允许的精度水平; 2.相关问题的重要性。
有两种原则性的解决方案。首先,如果使用最高密度区间宽度来进行声明,这些声明将具有一定的错误率,且研究者需要通过计算频率学派的错误率来量化错误声明的风险。这将使ROPE成为贝叶斯/频率学派的折中程序,其后验分布计算能够对参数值的可能性进行贝叶斯解释,而基于 HDI 是否落在等价范围内做出的决策则具有一个受控制的错误率。请注意,当使用信息先验时,HDI与CI不匹配,则使用HDI的错误率只能通过模拟来推导。第二种解决方案是不进行任何声明,展示完整的后验分布,从而让读者自己得出结论。
3.7 设置感兴趣的最小效应量
要使用等价检验来验证我们的预测是否正确,就是要明确规定哪些观察值太小而无法用我们的理论进行预测。我们永远无法说效应完全为零,但我们可以研究观察到的效应是否太小而不具备理论或实际上的重要性。这需要我们指定最小感兴趣区(SESOI)。同样的概念有许多名称,比如最小重要差异或临床显著差异(King, 2011)。花些时间思考一下,对于你正在设计的下一项研究,最小效应量是多少才可以被认为是理论或实际上有意义的?确定你的最小感兴趣区可能很困难,并且最小感兴趣区是多少,你可能从来没想过在研究设计的一开始需要思考这个问题。然而,确定最小感兴趣区对于实践有重要的好处。首先,如果某个领域的研究者能够确定哪些效应太小而不重要,那么就可以非常直接地为有意义的效应确定研究所需的统计检验力。其次,指定最小感兴趣区的好处是可以你的研究具有可证伪性。你的预测被别人证伪对你个人来说可能感觉不太好,但对整个科学界来说却非常有用(Popper,2002)。毕竟,如果某种预测不会出错,那么预测正确怎么令人影响深刻的呢?
要开始思考哪些效应量是重要的,先问问自己,在预测方向上的任何效应是否实际上支持备择假设?例如,Cohen’s d 为 10 的效应量是否支持你的假设?在心理学中,理论很少会预测如此巨大的效应量。如果发现 d = 10,你很可能会检查是否有计算错误或研究中存在混淆变量。另一方面,d = 0.001 的效应量是否符合理论提出的机制?这样的效应量非常小,远低于个体能注意到的水平,因为它低于感知和认知限制下的最小可觉差。因此,在大多数情况下,d = 0.001 会让研究者得出结论:“嗯,这实在是太小了,根本不符合我的理论预测,这么小的效果,几乎等同于没有效果。”然而,当我们做出方向性预测时,我们会说这种类型的效应全都是我们备择假说的一部分。尽管许多研究者会同意这种微小的影响太小而不重要,但如果我们有含零效应原假设的方向性预测,它们仍是支持我们备择假设的依据。此外,研究者很少有相应资源从统计上拒绝如此小的效应存在,因此声称这种效应仍支持理论预测会让该理论变得实际上不可证伪:研究者可以简单地回应任何显示出非显著小效应的重复性研究(例如 d = 0.05):“这并没有证伪我的预测,我想效应只是比 d = 0.05 稍微小一些”,而无需承认预测已被证伪。这是有问题的,因为如果我们没有重复和证伪的过程,科学学科就存在变得不可证伪的风险(Ferguson & Heene, 2012)。因此,当你设计实验或有理论和理论预测时,只要有可能,请仔细考虑并清楚说明你的最小感兴趣区是多少。
3.8 根据理论来指定SESOI
一个理论预测最小感兴趣区的例子可以从Burriss等人(2015)的研究中找到,他们研究了女性在排卵周期的生育期是否会出现面部发红的现象。他们的假设认为,皮肤稍红意味着更有吸引力和身体更健康,向男性发出这种信号会产生进化优势。这一假设的前提是,男性可以用肉眼发现皮肤变红。Burriss等人收集了22名女性的数据,结果表明她们面部皮肤的红润度确实在生育期增加了。然而,这种增加的幅度不足以让男性用肉眼察觉,因此这一假设被证伪了。由于可以测量出皮肤发红程度的最小可觉差,因此可以建立一个理论上可行的 SESOI。理论上的最小感兴趣区可以从最小可觉差中推导出来,它提供了能够影响个体的效应量下限,或者基于计算模型,它可以提供模型中参数的下限,该参数仍能解释实证文献中的观察结果。
3.9 锚定法设置 SESOI
基于最小可觉差这一概念,心理学家通常会对足以被单个个体注意到的效应感兴趣。锚定法是估计个体层面上何为有意义变化的一种程序(Jaeschke et al., 1989; King, 2011; Norman et al., 2004)。该方法需要在两个时间点收集测量数据(例如,治疗前后的生活质量测量)。在第二个时间点,使用一个独立测量指标(锚)来确定患者与时间点 1 相比是没有变化,还是有所改善或恶化。通常,患者会被直接要求回答锚点问题,并指出与时间点 1 相比,他们在时间点 2 的主观感受是相同、更好还是更差。Button et al. (2015) 使用锚定法估计出贝克抑郁量表的最小临床显著差异对应基线分数降低 17.5%。
Anvari和Lakens(2021) 应用锚定法来研究广泛使用的积极和消极情绪量表(PANAS)所测量的最小感兴趣区。被试在相隔数天的两个时间点完成了含 20 个项目的 PANAS(使用李克特量表,从1 =“非常轻微或根本没有”到5 =“极其严重”)。他们还被要求指出自己的情绪是变化了一点、变化了很多还是完全没有变化。当人们表示他们的情绪”有一点”变化时,以 Likert 单位计算,积极情绪的平均变化是0.26分,消极情绪的平均变化是0.28分。因此,如果采取干预措施来改善人们的情感状态,并使个人主观上认为至少有了一点改善,那么可以将SESOI设置为PANAS量表上的0.3个单位。
3.10 根据成本效益分析确定SESOI
另一种证明最小感兴趣区的原则性方法是进行成本效益分析。研究表明,认知训练可能改善老年人的心智能力,从而使老年驾驶员受益(Ball et al., 2002)。基于这些研究结果,Viamonte、Ball和Kilgore(2006)进行了成本效益分析并得出结论:根据干预成本(247.50美元),75岁以上驾驶员发生事故的概率(p 0.0710)和单次事故的成本(22,000美元),对所有75岁及以上驾驶员进行干预比不干预或仅在筛查测试后干预更有效。此外,敏感性分析表明,只要碰撞风险降低25%,对所有驾驶者进行干预仍然是有益的。因此,可以将 75 岁以上老年人发生车祸的概率降低 25% 设置为最小感兴趣区。
另一个例子,经济学家根据人们为降低死亡风险愿意支付的费用,将统计生命的价值定为150万到250万美元之间(2000年,在西方国家,参见 Mrozek & Taylor (2002))在此基础上,Abelson(2003)计算出人们为预防急性健康问题(如眼睛不适)而支付的意愿约为每天 40-50 美元。研究者可能正在研究一种心理干预措施,可以减少人们接触眼周面部皮肤的次数,从而减少细菌引起的眼部刺激。 如果实施干预每年花费 20 美元,那么应该将人群产生眼部刺激的平均天数减少至少 0.5 天,这样的干预措施才是值得的。成本效益分析也可以基于对研究极小效应所需资源与这一知识对科学界价值之间的权衡。
3.11 使用小型望远镜法确定 SESOI
理想的情况是,研究者在做出经验性声明时,总是明确指出哪些观察结果能够证伪其声明。 遗憾的是,这种做法尚未普及。当研究者对先前研究进行极其接近的重复性研究时,这尤其成问题。因为永远无法证明一个效应完全为零,而原作者也很少说明哪种效应量范围能证伪他们的假设,所以事实证明复制研究的结果很难解释(Anderson & Maxwell, 2016)。新数据何时与原始发现相矛盾?
考虑一项研究,你想在其中检验群体智慧这一概念。你请 20 个人估算一个罐子里的硬币数量,期望平均值非常接近真实值。 研究问题是平均来说,这些人能否正确地猜出硬币数量是 500 枚。观察到 20 人的平均猜测值为 550,标准差为 100。观察到的与真实值的差异具有统计学意义,t (19)=2.37,p = 0.0375,Cohen’s d 为 0.5。 群体平均值真的会相差如此之远吗? 群体智慧不存在吗? 你使用的硬币是否有什么特别之处,导致猜测硬币数量特别困难? 还是只是侥幸?你开始对此进行近似重复研究。
你希望你的研究不论是否存在效应都能提供有意义的信息。这意味着您需要设计一项复制研究,无论备择假设是否为真(群体无法准确猜测硬币的真正数量)或零假设是否为真(人们会猜出500枚硬币,原始的研究是巧合),都能让您得出有参考价值的结论。但是,由于最初的研究者并没有指定一个最小的目标效应量,那么什么时候复制研究才能让你得出新数据与原始研究相矛盾的结论呢?有些人可能会认为,观察到平均数正好是 500 非常有说服力,但由于随机变异,你(几乎)永远也找不到平均数正好是 500 的结果。不显著的结果不能解释为没有影响,因为你的研究可能样本量太小,无法检测到有意义的影响,且结果可能是第二类错误。那么,我们如何才能确定有意义的效应量呢?怎样才能设计出能够证伪先前发现的研究?
Uri Simonsohn(2015)将小效应定义为”能够给原始研究提供33%的统计检验力的研究”。换句话说,如果效应存在,该效应量使得原始研究有1/3的可能观察到统计显著性。如果原始研究有33%的统计检验力,且效应真实存在的话,那么在该研究中观察到显著效果的概率就太低了,无法可靠地区分信号和噪音(或有真实效果和没有真实效果的情况)。 Simonsohn(2015,第561页)称之为小型望远镜法,并写道:“想象一位天文学家声称用望远镜发现了一颗新行星。另一位天文学家试图用更大的望远镜复制这一发现,却一无所获。虽然这并不能证明这颗行星不存在,但它确实与最初的发现相矛盾,因为用较小的望远镜可以观测到的行星,用较大的望远镜也应该可以观测到。”
虽然这种设定最小感兴趣区(SESOI)的方法很随意(为什么不是30%或35%?),但在实际应用中已经足够了(你也可以自由选择你认为过低的统计检验力水平)。这样定义SESOI的好处是,如果你知道原始研究的样本量,就可以计算出该研究33%统计检验力时探测到的效应量。因此,你始终可以使用这种方法来设置最小感兴趣区。如果你未能找到原始研究33%统计检验力所探测到的效应量有关证据,这并不意味着不存在真正的效应,甚至也不意味着效应太小而没有任何理论或实际意义。但是,使用小型望远镜法是很好的第一步,因为它可以让人们开始讨论哪些效应是有意义的,并让想要复制研究的研究者明确何时可以认为原来的声明已被证伪。
使用小型望远镜法时,SESOI仅基于原始研究的样本量。最小感兴趣区仅针对同方向的效应。 所有小于此效应的(包括反方向的大效应)都被解释为未能重复原始结果。我们可以看到,小型望远镜法是一种单侧等价检验,其中只规定了上限,最小感兴趣区是根据原始研究的样本量确定的。该检验我们是否可以拒绝与原始研究有33%统计检验力检测到的效应一样大或更大的效应。它是一个简单的单侧检验,不是针对0,而是针对SESOI。该检验考察的是,我们是否能拒绝与原始研究33%统计检验力所探测到的一样大或更大的效应。这是一个简单的单侧检验,不是针对 0,而是针对 SESOI。
例如,在上述研究中,有 20 位竞猜者试图估计硬币的数量。结果采用双侧单样本 t 检验进行分析,α水平为0.05。为了确定本研究具有 33% 统计检验力的效应量,我们可以进行敏感性分析。 在敏感性分析中,我们根据 alpha、样本量和所需的统计检验力计算所需的效应量。 请注意,Simonsohn 在他的统计检验力分析中使用了双侧检验,我们在此也将沿用这一方法—-如果原始研究报告了预定的方向性预测,则统计检验力分析应基于单侧检验。 在这种情况下,alpha 水平为 0.05,总样本量为 20,所需统计检验力为 33%。我们计算了能够产生 33% 统计检验力的效应量,发现它是 0.358 的 Cohen’s d。 这意味着我们可以将重复研究最小感兴趣区设置为 d = 0.358。 如果我们能拒绝等于或大于 d = 0.358 的效应,我们就可以得出结论,该效应小于原始研究33%统计检验力所能探测到的效应。 下面的屏幕截图说明了 G*Power 中的正确设置,R 中的代码如下:
library("pwr")
pwr::pwr.t.test(
n = 20,
sig.level = 0.05,
power = 0.33,
type = "one.sample",
alternative = "two.sided"
)
One-sample t test power calculation
n = 20
d = 0.3577466
sig.level = 0.05
power = 0.33
alternative = two.sided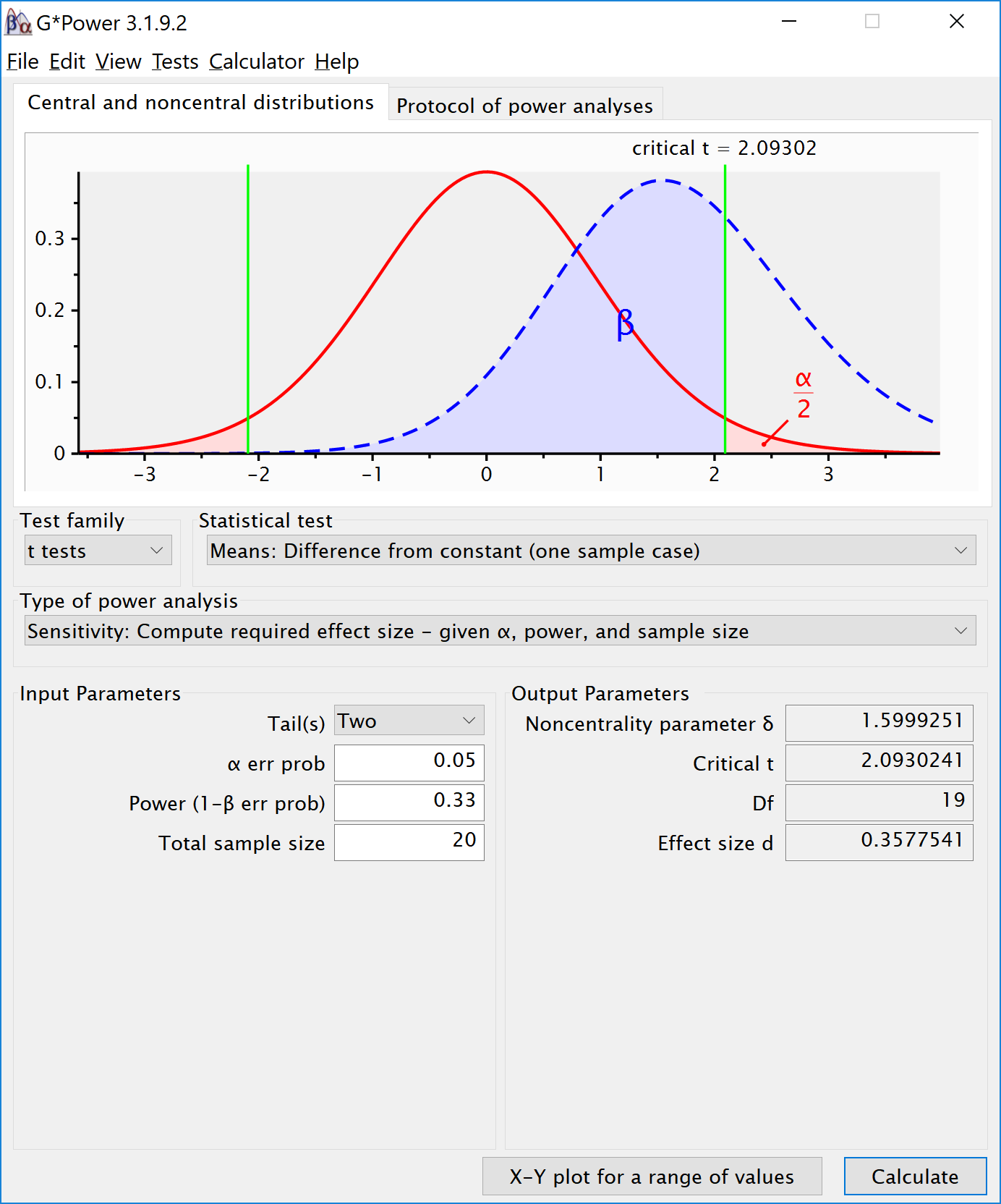
基于原始研究33%统计检验力所探测到的效应量来确定最小感兴趣区还有一个好处:假设真实的效应量为0,你基于小望远镜方法进行统计检验,看看数据在统计学上是否小于 SESOI(这也被称作劣势检验)。如果将样本量增加 2.5 倍,假定真实效应量正好为 0(例如,d = 0),那么这种单侧等价检验的统计检验力将达到约 80%。 进行重复研究的人可以遵循小型望远镜法的建议,并且可以很轻松地确定最小感兴趣区和设计有意义的重复研究所需的样本量,假定真实效应量为 0(但请参阅上文关于先验统计检验力分析的部分,在这里你想检验等价性,但并不期望真实效应大小为 0)。
下图来自 Simonsohn(2015),通过现实生活中的真实例子说明了小型望远镜法。 Zhong 和 Liljenquist(2006)的原始研究样本量很小,每个条件下只有 30 名参与者,观察到的效应大小为 d = 0.53,这与零几乎没有统计学差异。考虑到每个条件下的样本量为 30 人,该研究有 33% 的统计检验力探测到大于 d = 0.401 的效应。这种”小效应”由绿色虚线表示。 在 R 中,最小感兴趣区是通过以下方法计算的:
pwr::pwr.t.test(
n = 30,
sig.level = 0.05,
power = 1/3,
type = "two.sample",
alternative = "two.sided"
)
Two-sample t test power calculation
n = 30
d = 0.401303
sig.level = 0.05
power = 0.3333333
alternative = two.sided
NOTE: n is number in *each* group请注意,33%的统计检验力是一个四舍五入值,计算时使用了1/3(或0.3333333 …)。
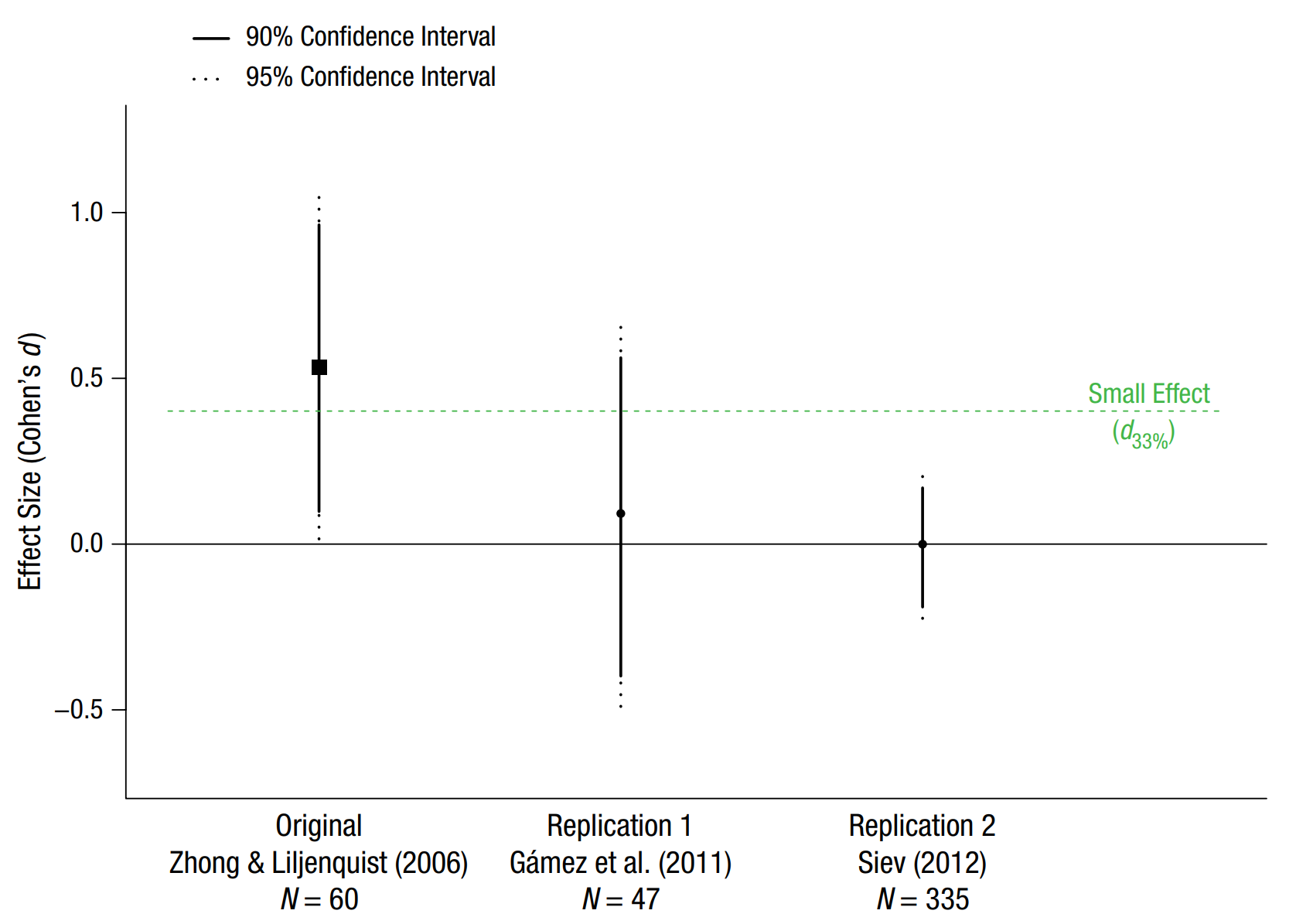
我们可以看到,Gámez及其同事进行的第一次重复研究也具有相对较小的样本量(N = 47,相对于原始研究中的N = 60),并且不是为了通过小型望远镜法产生有意义的结果而设计的。置信区间非常宽,包括零效应(d = 0)和最小感兴趣区(d = 0.401)。因此,这项研究没有得出结论。我们不能拒绝零效应,但也不能拒绝0.401或更大的效应量,因为这仍然符合原始结果。第二次重复研究的样本量要大得多,它告诉我们,我们无法拒绝零效应,但我们可以拒绝最小感兴趣区,这表明该效应小于根据小望远镜方法得出的值得关注的效应量。
虽然小望远镜法的建议易于使用,但应注意不要将任何统计程序变成启发式程序。 在我们上面关于20名被试的例子中,Cohen’s d为0.358被用作最小感兴趣区,收集的样本量为50个(是原来20个的2.5倍),但如果有人愿意努力进行重复性研究,收集更大的样本量就会相对容易。另一种情况是,如果原始研究的规模非常大,那么它就会有很高的统计检验力来探测出实际上可能并不显著的效应,且我们也不希望在重复研究中收集2.5倍于原始研究的观测值。 事实上,正如Simonsohn所写:“我们是否需要原始样本量的2.5倍取决于我们希望回答的问题。如果我们想检验效应量是否小于33%,那么,无论原始样本量如何,我们都需要大约2.5倍的原始样本量。但是,当样本非常大时,这可能就不是我们感兴趣的问题了。”请始终考虑你想要提出的问题,并设计研究,为你感兴趣的问题提供有参考价值的答案。不要盲目遵循2.5倍n的启发式方法,并且始终思考建议的程序是否适合你的情况。
3.12 把最小感兴趣区设置为统计学可探测到的最小效应
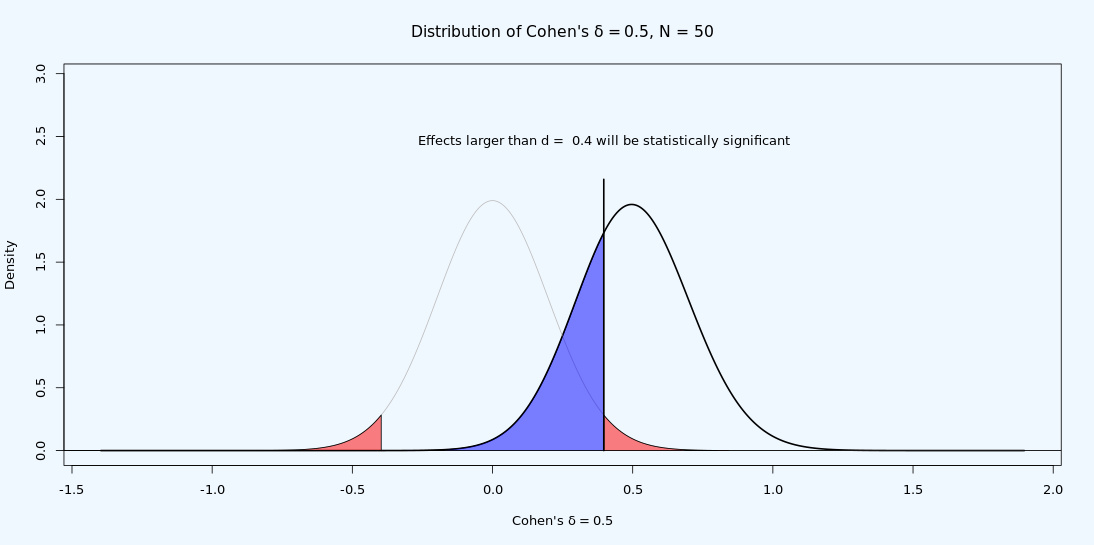
在给定样本量和 α 水平的情况下,每个检验都有一个 统计学可探测到的最小效应。例如,如果测试中每组有 86 名参与者,且 α 水平为 5%,只有 t ≥ 1.974 的 t 检验才具有统计显著性。 换句话说,t = 1.974 是临界 t 值。 给定样本量和 α 水平,可以将临界 t 值转换为临界 d 值。如图 Figure 3.8 所示,每组 n = 50,α 水平为 5%,临界 d 值为 0.4。这意味着只有大于 0.4 的效应才会产生 p < α。 临界 d 值受每组样本量和 α 水平的影响,但与真实效应量无关。
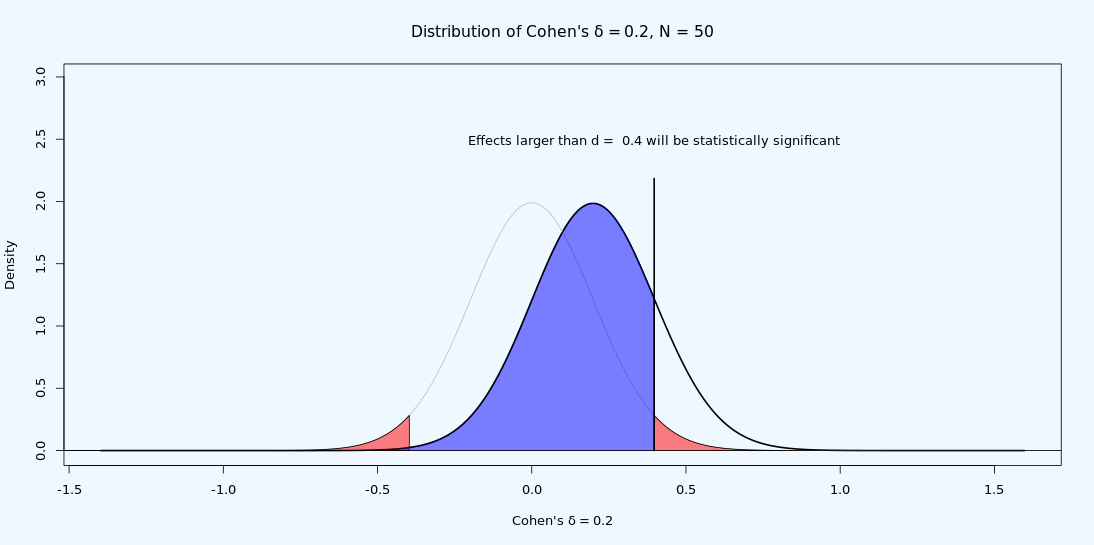
如果真实效应量小于临界效应量,则有可能观察到统计上显著的检验结果。由于随机变异,有可能在样本中观察到比群体中真实值更大的值。这就是为什么在零假设显著性检验中,统计检验力永远不为零的原因。正如图 Figure 3.9 所示,即使真实效应量小于临界值(例如,真实效应量为0.2),我们也可以从分布图中看到,当真实群体效应量为 d = 0.2,我们可以预期一些观察到的效应量大于0.4——如果我们计算这个检验的统计检验力,结果表明从长远来看,我们可以预期观察到的效应量中有 16.77% 会大于 0.4。 这并不算多,但也是有意义的。这也是为什么发表偏倚加上研究统计检验力不足是很有问题的:如果文献中观察到显著结果的效应量只来自统计检验力不足的研究,这将导致对真实效应量的大幅高估。
我们可以使用统计学上可探测到的最小效应来设置重复研究的SESOI。如果你试图重复一项研究,选择最小感兴趣区(SESOI)时的一个合理选项是使用你所重复的研究中可能具有统计显著性的最小观察效应量。换句话说,你可以决定在原始研究中无法产生小于α的p值的效应,它们在复制研究中将被认为是没有意义的。这里的假设是,原作者希望观察到显著效应,因此对观察到无法产生显著结果的效应量不感兴趣。原作者很可能没有考虑到他们的研究在统计学上有足够的统计检验力探测到哪些效应量,或者他们对更小的效应感兴趣,但承受着认为观察到的大效应只是来源于随机变异所带来的风险。即便如此,在没有指定SESOI的早期研究的基础上,一个合理的出发点可能是将SESOI设定为在原始研究中观察到的可能具有统计学意义的最小效应量。并非所有研究者都会同意这一点(例如,原始作者可能会说他们实际上也关心d
0.001的效应)。然而,当我们试图改变这一领域当前的状况时,即没有人明确指出什么能证伪他们的假说,或者他们的最小感兴趣区是多少,这种方法不失为一种起步方式。在实践中,如事后检验力部分所解释的,对于观察到的效应量而言, 由于p = 0.05 与观察效应量 50% 统计检验力之间的关系,这种对 SESOI 的合理性证明将意味着 SESOI 被设置为原始研究在独立t检验中有 50% 的统计检验力来探测的效应量。这种方法在某些方面与 Simonsohn (2015) 提出的小型望远镜法相似,只是它将导致更大的 SESOI。
为重复研究设置最小感兴趣区有点像一场网球比赛。原作者发球并将球击过球网,说”看,有情况”。将SESOI设置为在原始研究中可能具有显著性的效应量的方法是回球,它允许你在通过一项精心设计、统计检验力较高的重复研究后说”你的原始研究中似乎没有足够大的显著效应”,从而拒绝SESOI。这并不是比赛的结束——原作者可以尝试还击,就他们的理论所预测的效应做出更具体的陈述,并证明存在这种较小的效应量。但球又回到了他们的手中,如果他们想继续声称存在效应,就必须用新的数据来支持他们的说法。
除了重复研究之外,所收集的数据量也限制了人们所能做出的推论。根据研究领域通常使用的样本量,也可以计算出统计学上可探测到的最小效应。例如,假设一个研究领域中的假说几乎总是通过执行单样本 t 检验来验证,并且收集的样本量始终小于 100个观测值。对 100 个观测值进行单样本 t 检验,使用 0.05 的 α(双侧),有 80% 的统计检验力来探测到一个 d = 0.28 的效应(可以通过灵敏度检验力分析计算得出)。在一项新的研究中,我们可以可靠地拒绝比 d = 0.28 更极端的效应的存在,这一结论表明,在此类研究中,100 个样本量可能不足以探测出效应。 拒绝比 d = 0.28 更极端效应的存在并不能检验理论预测,但它通过回答一个资源问题对文献做出了贡献。它表明,今后在这一研究方向上的研究需要改变研究设计,大幅增加样本量。基于这种方法设置最小感兴趣区并不能回答任何理论问题(毕竟,SESOI 不基于任何理论预测)。但是,如果告知同行,在某一领域通常收集的样本量下,效应还不够大,因此无法对其进行可靠的研究,这是对文献的有益贡献。这并不意味着该效应本身没有意义,同时某一领域可能会决定,是时候通过协调研究路线,共同研究该研究问题,并收集足够的数据,来可靠地研究是否存在较小的效应。
3.13 自我测验
3.13.1 关于等效检验的问题
问题1:当均值差异的90%置信区间落入等效范围-0.4到0.4之间时,我们可以拒绝感兴趣的最小效应量。根据你对于置信区间的了解,当等效范围改变为变化为-0.3到0.3时,什么情况下等效检验才能显著(假定估计效应量和标准差不变) ? A) 更大的效应量。 B) 更低的α水平。 C) 更大的样本量。 D) 更低的统计检验力。
问题2:为什么在等效检验统计显著时,得出没有效应的结论是错误的?
- 等效检验只针对数据,而非效应的存在与否。
- 等效检验可能伴随着一类错误,因此,我们应该认为不存在效应,或者存在一类错误。
- 等效检验会拒绝与最小感兴趣效应同样大或者更大的数值,所以不能拒绝存在一个小的非零效应的可能性。
- 当等价检验不显著而非显著时,我们才可以得出效应不存在的结论。
问题3:研究者想知道使用电子书的学生是否与使用纸质书的学生得表现一样好。如果一样好,他们就会建议教师允许学生自由使用媒介;但如果这两者有差异,他们则会推荐使用导致更好表现的那种媒介。他们随机分配学生使用电子书或者教科书,比较他们在考试中的成绩 课程(从最差的1分到最好的10分)。他们发现两组学生的表现相似,对于纸质教科书条件均值为 7.35,标准差为1.15,样本量为50,电子书均值为7.13,标准差为1.21,样本量为50)。假设我们认为任何大于或大于半个绩点(0.5)的影响都是值得的,但任何差异小于0.5,因为太小而无关紧要,alpha水平被设置为0.05。作者会得出什么结论?将下面的代码复制到R中,用正确的数字替换所有的0。输入?tsum_TOST以获取该函数的帮助。
- 我们可以拒绝效应值为零,也可以拒绝效应值大于或大于最小效应值的存在。
- 我们不能拒绝效应值为零,我们可以拒绝效应值大于或大于最小效应值的存在。
- 我们可以拒绝效应值为零,也可以不拒绝效应值大于或大于最小效应值的存在。
- 我们不能拒绝效应值为零,也不能拒绝效应值大于或大于最小效应值的存在。
问题4:如果我们将问题3中的样本量增加到每个条件下150名参与者,并且假设观察到的平均值和标准差完全相同,我们会得出什么结论?
- 我们可以拒绝效应值为零,也可以拒绝效应值大于或大于最小效应值的存在。
- 我们不能拒绝效应值为零,我们可以拒绝效应值大于或大于最小效应值的存在。
- 我们可以拒绝效应值为零,也可以不拒绝效应值大于或大于最小效应值的存在。
- 我们不能拒绝效应值为零,也不能拒绝效应值大于或大于最小效应值的存在。
问题5:如果我们将问题3中的样本量增加到每个条件下500名参与者,并且假设观察到的平均值和标准差完全相同,我们会得出什么结论? A) 我们可以拒绝效应值为零,也可以拒绝效应值大于或大于最小效应值的存在。 B) 我们不能拒绝效应值为零,我们可以拒绝效应值大于或大于最小效应值的存在。 C) 我们可以拒绝效应值为零,也可以不拒绝效应值大于或大于最小效应值的存在。 D) 我们不能拒绝效应值为零,也不能拒绝效应值大于或大于最小效应值的存在。
有时检验的结果是不确定的,如零假设检验和等效检验在统计上不显著。在这种情况下,唯一的解决方案是收集额外的数据。有时,零假设检验和等效检验在统计上都是显著的,在这种情况下,效果在统计上不同于零,但实际上不显著(基于SESOI的证明)。
问题6:我们可能想知道问题3中检验的统计检验力是多少,假设两组之间没有真正的差异(因此真实效应大小为0)。使用R包TOSTER中新改进的’power_t_TOST’函数,我们可以使用灵敏度功效分析(即输入每组50个样本量,假设真实效应大小为0,等效边界和alpha水平)计算统计检验力。请注意,由于等效边界是在问题3的原始尺度上指定的,因此我们还需要指定总体中真实标准偏差的估计值。假设真实标准差是1.2。把答案四舍五入到小数点后两位。输入?power_t_TOST ’获取函数的帮助。问题3的统计检验力是多少?
- 0.00
- 0.05
- 0.33
- 0.40
问题7:假设在问题3每组只有15名参与者而不是50名。在这个较小的样本量下(其他条件如问题6中所示),检验的统计检验力是多少?答案四舍五入到两位小数。
- 0.00
- 0.05
- 0.33
- 0.40
问题8:你可能还记得关于零假设显著性检验的统计检验力的讨论,统计检验力从不小于5%(如果真实效应大小为0,统计检验力在形式上未定义,但我们将观察到至少5%的一类错误,并且在引入真实效应时统计检验力增加)。在双尾等效检验中,统计检验力可以低于α水平。为什么?
- 因为在等效检验中,一类错误率没有限定在5%。
- 因为在等效检验中,原假设和备择假设是相反的,因此二类错误率没有下界(就像零假设检验中的一类错误率没有下界一样)。
- 由于置信区间需要落在等效区间的下界和上界之间,并且样本量较小,因此该概率可以接近于1(因为置信区间非常宽)。
- 因为等效检验是基于置信区间,而不是基于p值,因此统计检验力不受alpha水平的限制。
问题9:一项设计良好的研究能够很好地检测感兴趣的效应,但也能拒绝最小的感兴趣效应。对问题3中描述的情况进行先验检验力分析。假设真实效应量为0,我们仍然假设真实标准差为1.2,每个组中需要收集多少样本量才能达到期望的统计检验力为90%(或0.9)?使用下面的代码,并将样本大小四舍五入(因为我们无法获得非整数的观测)。
- 100
- 126
- 200
- 252
问题10:假设在对问题9进行统计检验力分析时,我们并不期望真正的效应大小为0,但我们实际期望的平均差值为0.1分。在每个组中,当我们期望真正的效应量为0.1时,我们需要收集多少样本量来进行等效检验?调整’ power_t_TOST ‘中的变量’ delta ’来回答这个问题。
- 117
- 157
- 314
- 3118
问题11:将问题9的等效范围更改为-0.1和0.1(并将’delta’的预期效应大小设置为0)。为了能够拒绝这个小等效范围之外的效应,你将需要大样本量。如果alpha值为0.05,期望统计检验力为0.9(或90%),那么每个组需要多少被试?
- 1107
- 1157
- 2468
- 3118
你可以看到我们需要一个非常大的样本量才能有高的统计检验力来可靠地拒绝非常小的效应。这不足为奇。毕竟,我们也需要一个非常大的样本量来检测到小效应!这就是为什么我们通常把它留给未来的荟萃分析来检测或拒绝小效应的存在。
问题12:你可以对所有检验进行等效检验。TOSTER包具有进行t检验,相关性,比例差异和元分析的函数。如果你想要进行的检验没有包含在任何软件中,请记住,你可以只使用90%的置信区间,并检验你是否可以拒绝感兴趣的最小效应值。让我们对meta分析进行等效检验。Hyde, Lindberg, Linn, Ellis, and Williams (2008)报告了在美国700万学生的数学测试中,性别差异的效应大小可以忽略不计,这个性别差异的效应被定义为小于d =0.1。科恩d效应量和标准误se表如下:
| 年级 | d + se |
|---|---|
| 二年级 | 0.06 +/- 0.003 |
| 三年级 | 0.04 +/- 0.002 |
| 四年级 | -0.01 +/- 0.002 |
| 五年级 | -0.01 +/- 0.002 |
| 六年级 | -0.01 +/- 0.002 |
| 七年级 | -0.02 +/- 0.002 |
| 八年级 | -0.02 +/- 0.002 |
| 九年级 | -0.01 +/- 0.003 |
| 十年级 | 0.04 +/- 0.003 |
| 十一年级 | 0.06 +/- 0.003 |
对于二年级,当我们在d=-0.1和d=0.1的边界下,使用alpha为0.01进行等效检验时,我们可以得出什么结论?使用TOSTER函数TOSTmeta,并输入alpha、效应大小(ES)、标准误差(se)和等效边界。
- 我们可以拒绝效应值为零,也可以拒绝效应值大于或大于最小效应值的存在。
- 我们不能拒绝效应值为零,我们可以拒绝效应值大于或大于最小效应值的存在。
- 我们可以拒绝效应值为零,也可以不拒绝效应值大于或大于最小效应值的存在。
- 我们不能拒绝效应值为零,也不能拒绝效应值大于或大于最小效应值的存在。
3.13.2 关于小型望远镜法的问题
问题13:当原始研究在每个条件下收集20名参与者进行独立样本t检验,α=0.05时,基于小型望远镜方法的最小效应量大小是多少?请注意,答案将取决于你输入的统计检验力是0.33还是1/3(或0.333)。你可以使用下面的代码,它依赖于 ‘pwr’ 包。
pwr::pwr.t.test(
n = 20,
sig.level = 0.05,
power = 1/3,
type = "two.sample",
alternative = "two.sided"
)
Two-sample t test power calculation
n = 20
d = 0.4958917
sig.level = 0.05
power = 0.3333333
alternative = two.sided
NOTE: n is number in *each* group- d =0.25(将统计检验力设为0.33) 或0.26(将统计检验力设为1/3)
- d =0.33(将统计检验力设为0.33) 或0.34(将统计检验力设为1/3)
- d =0.49(将统计检验力设为0.33) 或0.50(将统计检验力设为1/3)
- d =0.71(将统计检验力设为0.33) 或0.72(将统计检验力设为1/3)
问题14:假设你正在尝试基于双尾检验中的相关分析来复现先前的结果。这项研究有150名被试。使用小型望远镜计算SESOI,并使用0.05的α水平。请注意,答案将取决于你输入的统计检验力是0.33还是1/3(或0.333)。你可以使用下面的代码。
- r =0.124(将统计检验力设为0.33) 或0.125(将统计检验力设为1/3)
- r =0.224(将统计检验力设为0.33) 或0.225(将统计检验力设为1/3)
- r =0.226(将统计检验力设为0.33) 或0.227(将统计检验力设为1/3)
- r =0.402(将统计检验力设为0.33) 或0.403(将统计检验力设为1/3)
问题15:在大数据时代,研究人员通常可以访问大型数据库,并可以对数千个样本进行相关性分析。假设上一个问题中的原始研究不是150个样本,而是15000个样本。我们仍然使用0.05的alpha水平。请注意,对于这个答案,答案将取决于你输入的统计检验力是0.33还是1/3(或0.333)。基于小型望远镜方法的SESOI是多少?
- r =0.124(将统计检验力设为0.33) 或0.125(将统计检验力设为1/3)
- r =0.224(将统计检验力设为0.33) 或0.225(将统计检验力设为1/3)
- r =0.226(将统计检验力设为0.33) 或0.227(将统计检验力设为1/3)
- r =0.402(将统计检验力设为0.33) 或0.403(将统计检验力设为1/3)
这种影响可能在实践上或理论上是显著的吗?可能不会。在这种情况下,小型望远镜并不是一个非常有用的方法来确定最小效应的大小。
问题16:使用小型望远镜方法,并将复制研究中的SESOI设置为d=0.35,将alpha水平设置为0.05。在尽可能接近原始研究的有力复现研究中收集数据后,你发现没有显著的效应,并且你可以拒绝大于或大于d = 0.35的效应。这个结果的正确解释是什么?
- 没有效应存在。
- 我们可以在统计上拒绝(使用0.05的alpha值)任何理论上有意义的效应。
- 我们可以在统计上拒绝(使用0.05的alpha值)任何实际上有意义的效应。
- 我们可以在统计上拒绝(使用0.05的alpha值)原始研究中有33%的统计检验力检测到的效应。
###关于将SESOI指定为最小统计可检测效应的问题
问题17:打开在线的Shiny应用程序,它可以用来计算两个独立总体的最小统计可检测效应:https://shiny.ieis.tue.nl/d_p_power/。 三个滑块影响图形的外观:每个条件的样本量、真实效应大小和alpha水平。下列哪个说法是正确的?
- 临界d值受每组样本量,即真实效应大小的影响,但不受α水平的影响。
- 临界d值受每组样本量,即α水平的影响,但不受真实效应大小的影响。
- 临界d值受α水平,即真实效应大小的影响,但不受样本量的影响。
- 临界d值受每组样本量,即α水平的影响,且受真实效应大小的影响。
问题18:假设研究人员对每种情况下的18名参与者进行了一项研究,并使用0.01的α水平进行了t检验。使用Shiny应用程序,在这项研究中可能具有统计意义的最小效应大小是多少?
- d = 0.47
- d = 0.56
- d = 0.91
- d = 1
问题19:你预期你的下一个研究中真实效应大小为d=0.5,并且你计划使用0.05的alpha水平。每组收集30名被试进行独立的t检验。下列哪个说法是正确的?
- 所有可能效应量的统计检验力都很低。
- 对于你感兴趣的效应大小,你有足够的统计检验力(大于80%) 。
- 观察到的效应量d = 0.5永远不会有统计学意义。
- 观察到的效应量d = 0.5具有统计学意义。
到目前为止,我们使用的例子是基于执行独立的t检验,但这个想法可以推广。这里有一个用于F测试的shiny应用程序:https://shiny.ieis.tue.nl/f_p_power/。与F检验的统计检验力相关的效应大小是偏eta平方(\(\eta_{p}^{2})\),对于单因素方差分析(在Shiny应用程序中可视化)是eta平方。
偏eta平方的分布看起来与科恩的d的分布略有不同,主要是因为F检验是单向检验(正因为如此,平方的值都是正的,而科恩的d可以是正的或负的)。浅灰线表示零值为真时的期望分布,曲线下的红色区域表示一类误差,黑线表示真效应大小η=0.059时的期望分布。蓝色区域表示预期效应值小于临界η值0.04,不具有统计学意义,因此属于二类误差。
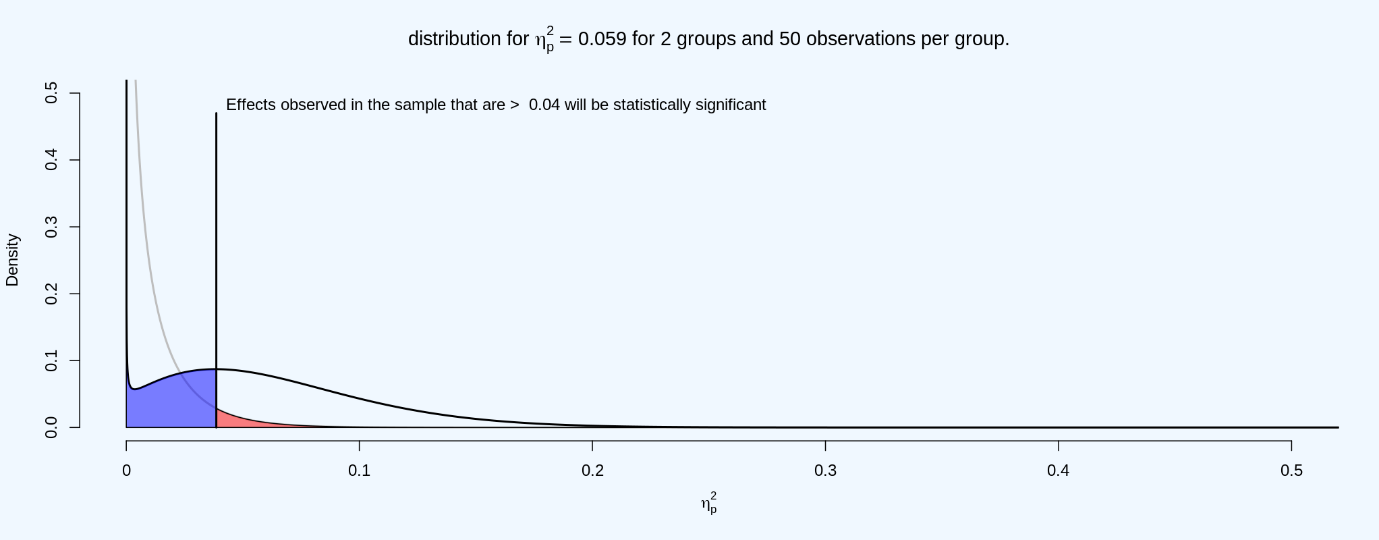
问题20:将参与者的数量(每个条件)设置为14,组的数量设置为3。使用Shiny应用程序https://shiny.ieis.tue.nl/f_p_power/看哪些效应量(以偏eta平方表示,如纵轴所示)在每组和三组n = 14时具有统计学显著性?
- 仅当效应量大于0.11
- 仅当效应量大于0.13
- 仅当效应量大于0.14
- 仅当效应量大于0.16
每个样本量和α水平都意味着在你的研究中具有统计显著性的最小统计可检测效应。查看你可以检测到哪些观察到的效应是一种有用的方法,可以确保你实际上可以检测到您感兴趣的最小效应大小。
问题21:使用最小可检测统计效应,将复现研究中的SESOI设置为d=0.35,并将alpha水平设置为0.05。在尽可能接近原始研究的有力复现研究中收集数据后,你发现没有显著的效应,并且你可以拒绝大于或大于d = 0.35的影响。这个结果的正确解释是什么?
- 没有效应存在。
- 我们可以在统计上拒绝(使用0.05的alpha值)任何理论上有意义的效应。
- 我们可以在统计上拒绝(使用0.05的alpha值)任何实际上有意义的效应。
- 我们可以在统计上拒绝(使用0.05的alpha值)原始研究中有33%的统计检验力检测到的效应。
3.13.3 开放性问题
“没有发现证据不等于证据不存在”这句话是什么意思?
等效检验的目的是什么?
零零假设和非零零假设的区别是什么?
最小效应检验是什么?
如果对同一批数据进行零假设显著性检验和等价性检验,并且都不是显著,可以得出什么结论?
当设计等效检验以获得期望的统计检验力时,为什么需要更大的样本量,等效范围越窄?
当等效检验显著时,为什么不能说不存在效应?
设计一种方法使得贝叶斯ROPE程序和等效检验相同,并设计另一种方法使二者不同。
有哪两种方法可以使得感兴趣的效应量最小?
等效检验中”小望远镜”背后的思想是什么?