4 序列分析
在数据收集过程中反复分析传入的数据有很多好处。当研究人员可以拒绝零假设或感兴趣的最小效应量时,即使他们需要收集更多数据,或者结果显示研究有意想不到的问题(例如,被试误解指导语或问题),研究人员也可以在中期分析(interim analysis)中停止数据收集。人们可以很容易理解,心理学研究者有道德义务重复地分析积累的数据,因为每当达到预期的置信水平,或足够清楚地表明预期的效应量不存在时,继续收集数据是对被试的时间和纳税人提供的金钱的浪费。除了这个伦理上的论点,设计利用序列分析的研究可能比只分析一次的数据更有效率,因为此时已经达到了研究者愿意收集的最大样本量。
序列分析不可与 [选择性停止](optional stopping)混淆,后者在误差控制(error control)一章中讨论过。在选择性停止中,研究人员使用未经校正的alpha水平(如,5%)来重复分析所得到的数据,这可能会大大增加一类错误率。与选择性停止不同,在序列分析中,一类错误率得到了控制。通过在每次中期分析中降低alpha水平,可以控制整体的一类错误率,就像Bonferroni校正用于防止多重比较中一类错误率的增长一样。事实上,Bonferroni校正是一个有效的(但保守的)控制序列分析的错误率的办法 (Wassmer & Brannath, 2016)。
在序列分析中,研究者设计了一项研究,以便他们能够进行中期分析,例如在收集了25%、50%和75%的数据时。每一个中期分析都会在校正后的(corrected)alpha水平上进行检验,这样在所有计划的分析中,所需的一类错误率就会保持不变。序列分析通常用于医学试验,在医学试验中,快速发现有效的治疗方法可能是一个生死攸关的问题。如果在中期分析中,研究人员确定一种新的药物是有效的,他们很可能会想终止试验,并将有效的药物提供给对照组的患者,以改善患者的健康状况,甚至拯救他们的生命。例如,辉瑞-生物技术公司(Pfizer–BioNTech)采用了一种实验设计分析COVID-19疫苗的安全性和有效性:他们计划对数据进行5次分析,并通过降低每次中期分析的alpha水平来控制整体的一类错误率。 interim analysis。
尽管序列分析技术有很长的历史,但序列分析在许多科学学科中的使用最近才慢慢变得流行起来。早在1929年,Dodge和Romig就意识到按序列分析数据比一次分析更有效率 (Dodge & Romig, 1929)。 Wald (1945),于1945 年推广了假设的顺序检验思想,并在第二次世界大战期间开展了工作。正如他在历史记录中解释的那样,直到战争结束后他才被允许发表他的发现:
由于序列概率比试验大大节省了预期的观察次数,也由于这种试验程序在实际应用中的简单性,国防研究委员会认为这些发展对战事非常有用,所以至少在一定时期内最好不要让敌人知道这些结果。因此,作者被要求在1943年9月的一份限制性报告中提交了他的报告。
序列分析是行之有效的程序,并且在过去几十年中被详细开发(Jennison & Turnbull, 2000; Proschan et al., 2006; Wassmer & Brannath, 2016)。 在这里,我们将解释如何在组序列分析中(group sequential analysis)控制错误率的基本原理,并进行先验的统计检验力分析(a-priori power analysis),比较序列设计何时会比固定设计(fixed designs)更高效或更低效。在我们讨论这些话题之前,有必要先了解一些术语的定义。 观察(look) (也称 阶段) 是指分析截止至某一特定时间点收集的所有数据;例如,你在 50、100和150次观察之后进行观察(look),并分析到该点为止所收集的所有数据。在50次和100次观察后进行中期分析,在第150次观察后进行最终分析(final analysis),并停止数据收集。在实践中,并不是所有的观察(look)都要发生。如果分析发现在一次观察(look 1)的时候就得到了统计学意义的结果,就可以终止数据收集。我们停止的原因是拒绝\(H_0\)(例如,在无效假设显著性检验中),或者拒绝\(H_1\)(例如,在等价性检验中)。我们可以在缩减(curtailment)或无用(futility)的情况下停止分析:最终分析不可能或非常不可能产生 p < alpha的结果。序列设计中总体alpha水平(overall alpha level) 与每次观察的alpha水平不同。例如,如果我们想让一个有3次观察的双侧试验的总体一类错误率为5%,每次观察的alpha水平可以是0.0221(如果我们使用 Pocock Pocock (1977) 提出的alpha矫正方法)。在本章中,我们将重点讨论组序列设计,即在多组中收集数据,但也存在其他的序列方法,正如在关于 sample size justification的章节中所解释的那样。
4.1 为序列分析选择alpha水平
在不校正alpha水平的情况下对数据进行多次分析时,一类错误率就会增加(Armitage et al., 1969)。正如Armitage和他的同事所展示的,在等间隔的观察(look)下,5次观察(look)后alpha水平会增长至0.142,100次观察(look)后增长至0.374,1000次观察(look)后增长至0.530。观测两次数据在概念上类似于决定当两个因变量中的一个显示出统计学上的显著性时,结果是否显着。然而,一个重要的区别是,在序列分析的情况下,多重检验不是独立的,而是相互依赖的。观察2的检验结合了观察1收集的旧数据和观察2的新数据。这意味着与独立测试相比,一类错误率增长的速度较慢,这使得控制错误率的解决方案更加有效和灵活。接下来我们将详细介绍。
在序列分析中控制一类错误率时,需要决定如何在所有观察数据中支出的alpha水平。例如,当研究人员计划进行一项研究,对数据进行一次中期检查和一次最终检查时,需要为第一次观察(在 N 次观察中的 n 个)和第二次观察(第N 次观察)设定边界临界Z值。 需要选择这两个临界值\(c_1\)和\(c_2\)(用于第一次和第二次分析),以便拒绝零假设的总体概率(overall probability,Pr)——在第一次分析中观察到的Z分数大于第一次观察的临界值,\(Z_n\) ≥ \(c_1\),并且(如果我们在第一次分析中没有拒绝假设,那么 \(Z_n\) < \(c_1\),我们继续数据收集)当在第二次分析观察到的Z分数大于第二次观察的临界值,\(Z_N\) ≥ \(c_2\) —— 当原假设为真时,等于所需的总体alpha水平。对于有方向检验(directional test)的公式
\[ Pr\{Z_n \geq c_1\} + Pr\{Z_n < c_1, Z_N \geq c_2\} = \alpha \]
如果有一个以上的中期分析,就必须按照同样的原理来确定额外的临界值。如果将数据的多个观察与多重比较结合起来,将对alpha水平进行两次校正,一次用于多重比较,另一次用于多个观察。因为alpha水平被校正了,所以在每次观察时进行何种统计检验方法并不重要,重要的是将p值与校正后的alpha水平进行比较。下面讨论的校正对任何数据为正态分布的设计都是有效的,而且每一组观测值都是独立于前一组。
4.2 Pocock校正
研究人员需要做出的第一个决定是,如何校正跨观察的一类错误率。四种常见的方法是Pocock校正,O’Brien-Fleming校正,TheHaybittle&Peto校正,以及Wang和Tsiatis 方法。用户也可以自由地指定他们自己喜欢的方式来支出跨观察的alpha水平。
Pocock校正是校正多次观察的alpha水平最简单的方法。从概念上讲,它与Bonferroni校正非常相似。 Pocock校正是这样被建立的:每次观察数据时的alpha水平相同,从而导致恒定的临界值(以 z 值表示)\(u_k = c\) 以拒绝在观察\(k\)时的零假设 \(H_0\)。以下代码使用包 rpact来设计一个序列分析的研究:
library(rpact)
design <- getDesignGroupSequential(
kMax = 2,
typeOfDesign = "P",
sided = 2,
alpha = 0.05,
beta = 0.1
)
print(summary(design))Sequential analysis with a maximum of 2 looks (group sequential design)
Pocock design, two-sided overall significance level 5%, power 90%,
undefined endpoint, inflation factor 1.1001, ASN H1 0.7759, ASN H01 1.0094,
ASN H0 1.0839.
Stage 1 2
Information rate 50% 100%
Efficacy boundary (z-value scale) 2.178 2.178
Stage levels (one-sided) 0.0147 0.0147
Cumulative alpha spent 0.0294 0.0500
Overall power 0.5893 0.9000
-----
Design parameters and output of group sequential design:
User defined parameters:
Type of design : Pocock
Maximum number of stages : 2
Stages : 1, 2
Information rates : 0.500, 1.000
Significance level : 0.0500
Type II error rate : 0.1000
Test : two-sided
Derived from user defined parameters: not available
Default parameters:
Two-sided power : FALSE
Tolerance : 0.00000001
Output:
Cumulative alpha spending : 0.02939, 0.05000
Critical values : 2.178, 2.178
Stage levels (one-sided) : 0.01469, 0.01469 输出结果告诉我们,使用Pocock支出函数设计一个具有两次观测(一个中期,一个最终)的研究。最后一行返回单侧的alpha水平。rpact 包主要应用于验证适应性临床试验设计和分析(Confirmatory Adaptive Clinical Trial Design and Analysis)。在临床试验中,研究人员大多检验有方向的预测,因此,默认设置是进行单侧检验。在临床试验中,通常使用0.025的显著性水平进行单侧检验,但在许多其他领域,0.05是一个更常见的默认值。我们可以通过将单侧的alpha水平乘以2来得到双侧的alpha水平:
我们可以对照维基百科上的 Pocock 校正页面 检查输出结果,我们确实可以在网页上看到,在对数据进行两次观察(look)的情况下,每次观察的alpha水平是0.0294。Pocock校正比使用Bonferroni校正(在这种情况下,alpha水平将是0.025)略微有效,因为数据中存在依赖性(在第二次观察时,第一次观察时分析的数据又是分析的一部分)。
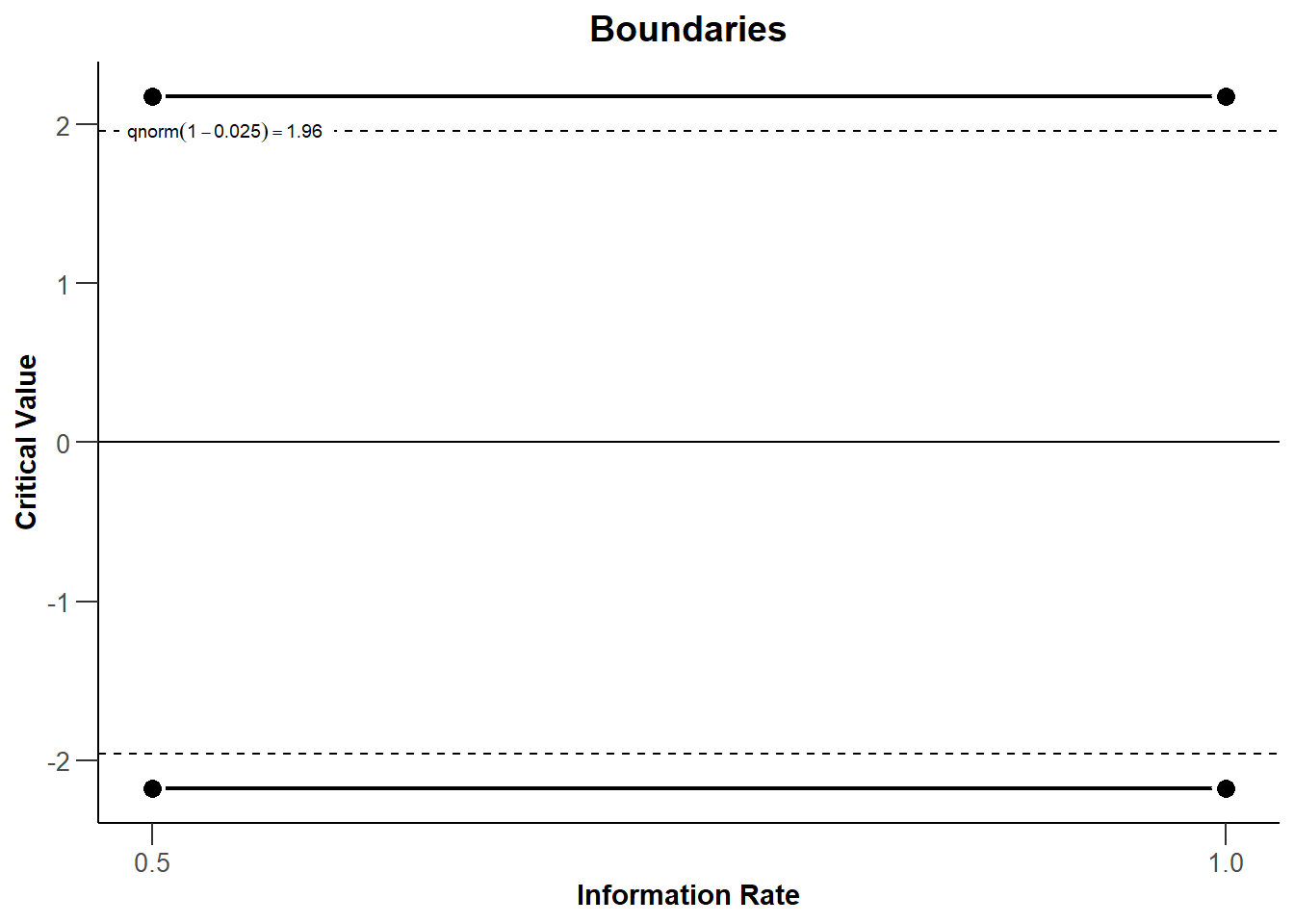
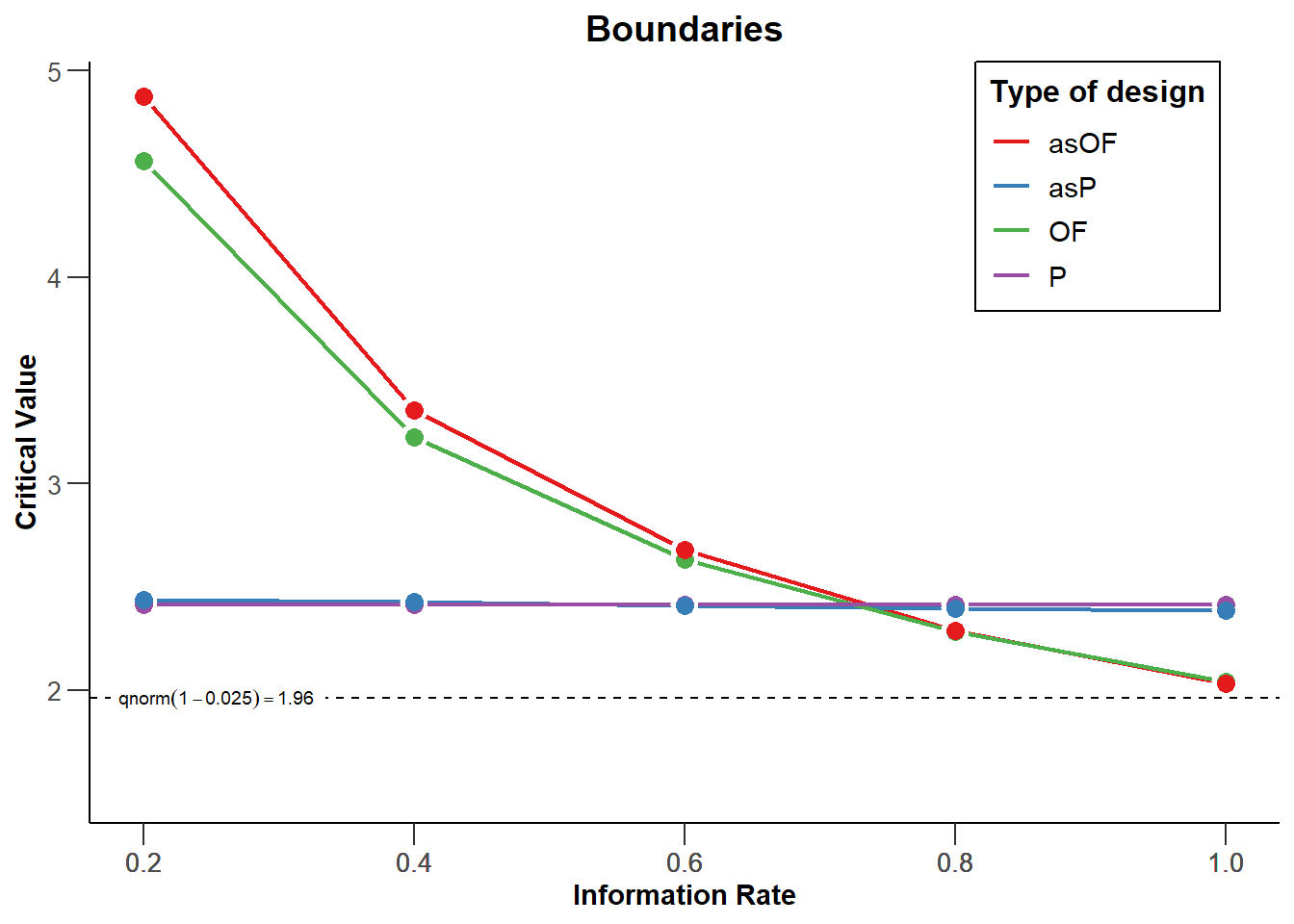
rpact 可以很容易地绘制出每个观察的边界(基于临界值)。观察次数被绘制成 "信息率"(Information Rate)的函数,信息率是指在一次观测中收集的总数据的百分比。 在图 Figure 4.1 中有两次等距的观察,所以当50%的数据被收集时,信息率为0.5);当100%的数据被收集时,信息率为1。 我们看到临界值(黑色实线)大于我们在5% 的alpha水平的固定设计中使用的1.96,即Z = 2.178(黑色虚线)。每当我们观察到一个测试统计量在第一或第二次观察(look)时比这些临界值更极端,我们就可以拒绝零假设。
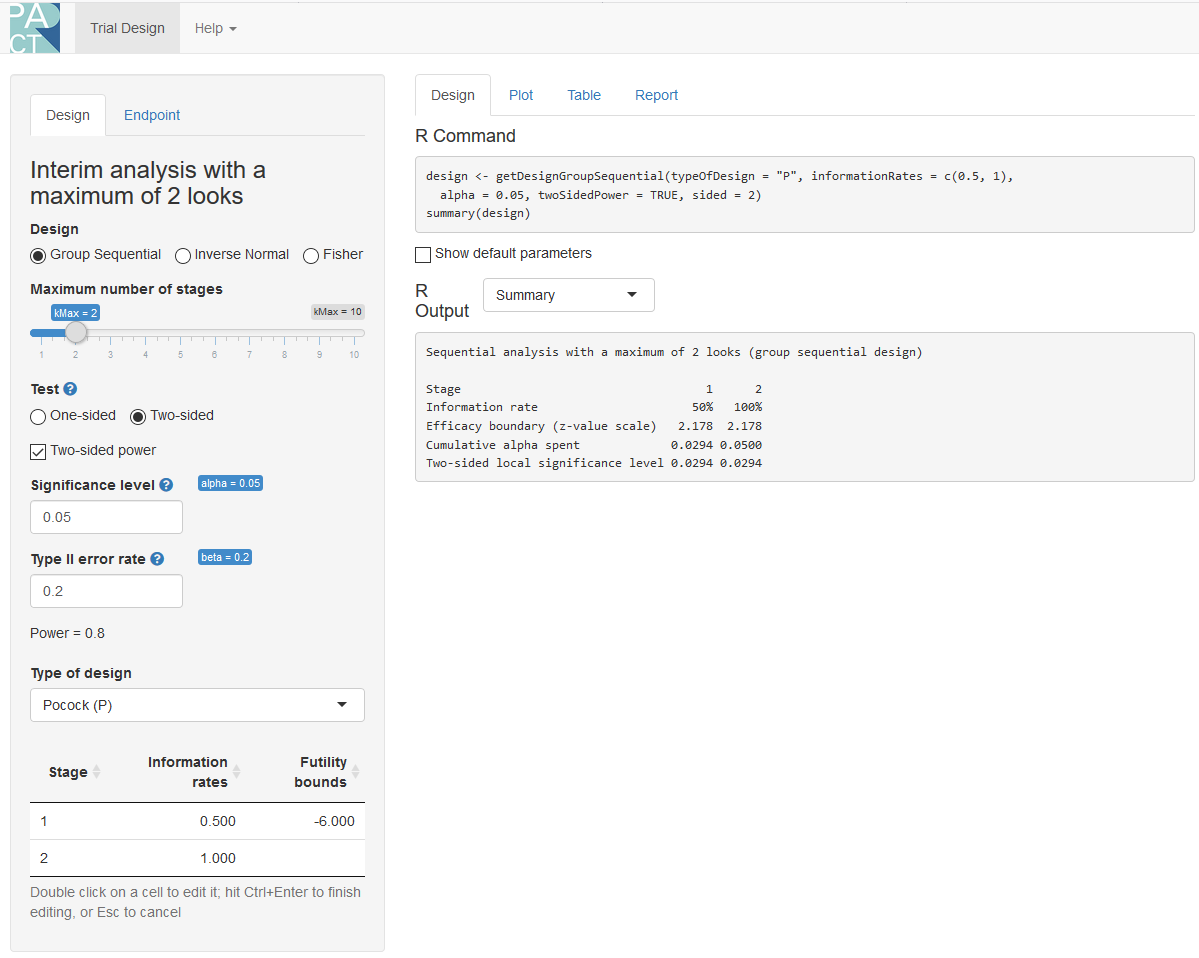
分析也可以在rpactshiny app中进行,它也允许用户通过简单的菜单选项创建所有的图,并下载完整的分析报告(例如,用于预注册文件)。
4.3 比较支出函数
我们可以在同一个图中对3次观察中每一个进行不同类型的校正(两个中期和一个最终观察)(见图 Figure 4.3)。下图展示了Pocock,O’Brien-Fleming,Haybittle-Peto和 Wang-Tsiatis对 \(\Delta\) = 0.25矫正。我们看到研究人员可以选择不同的方法来跨观察支出alpha水平。研究人员可以选择保守地使用他们的alpha(为最后一次观察保留大部分alpha),或更自由地(在早期观察中支出更多的alpha,这增加了对于许多真实效应量提前停止的可能性)。
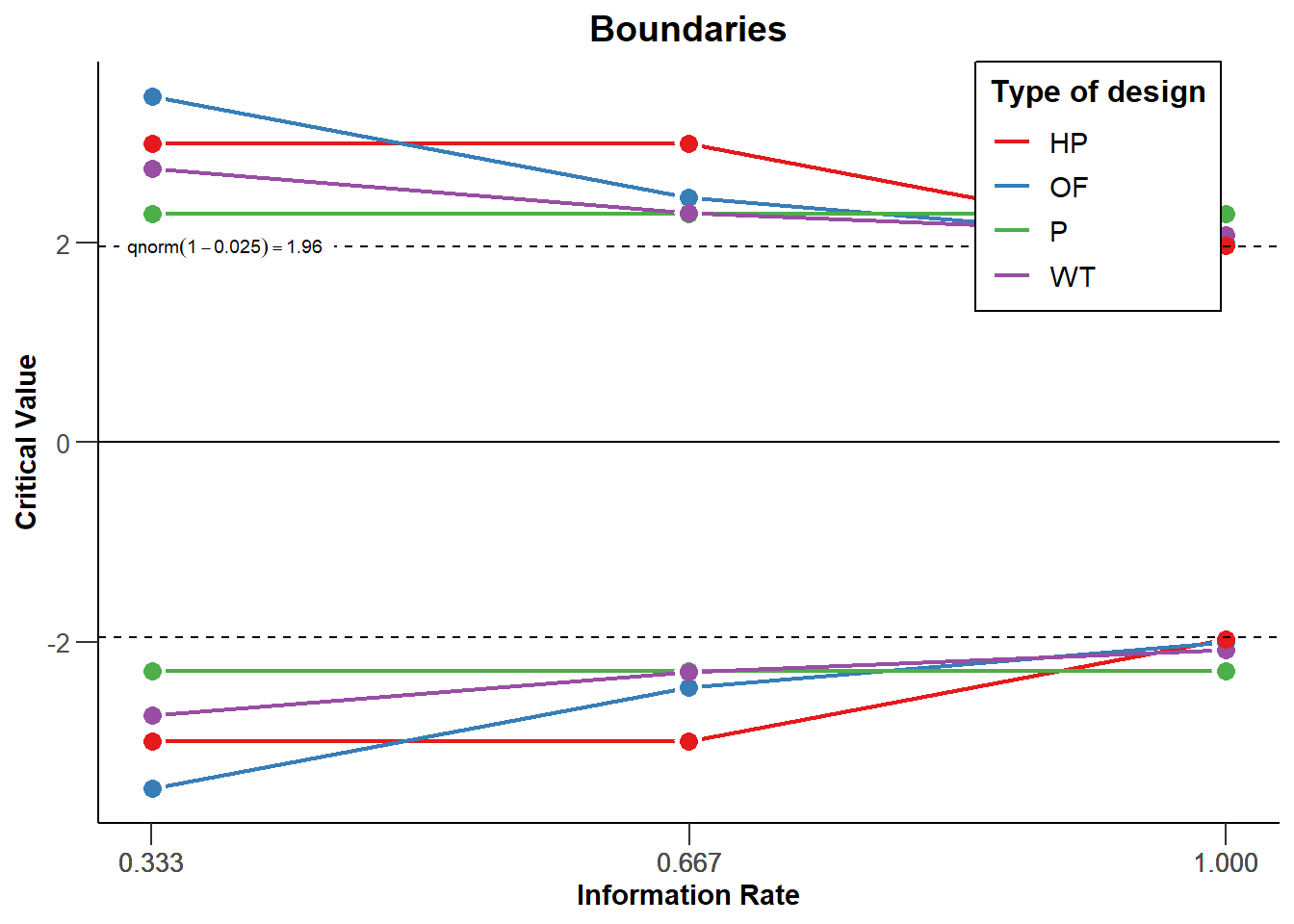
我们可以看到,O’Brien和Fleming的校正在第一次观察时要保守得多,但在最后一次观察时却接近未校正的临界值1.96(见黑色虚线,对于双侧检验,所有的临界值都是反映在负方向): 3.471, 2.454, 和 2.004。 Pocock 校正在每次观察时都有相同的临界值(2.289, 2.289,以及 2.289)。The Haybittle和Peto校正除了最后一次,在每次观察时都有相同的临界值(3, 3, and 1.975)。 而Wang和Tsiatis校正在每次观察(look) 时的临界值都会减少(2.741, 2.305, 和2.083)。
如果你主要是想监测结果的意外发展,那么在早期观察时保持保守是明智的。当效应是否存在以及效应大小有多大这两方面都存在很大的不确定性时,Pocock校正更有用,因为如果效应很大的话,它可以使提前停止实验的概率更高。因为检验的统计检验效力取决于alpha水平,在最后一次观察降低alpha水平意味着与固定设计相比统计效力降低,为了达到理想的能力,需要增加研究的样本量以保持最后观察的统计检验效力不变。样本量的增加可以通过提前停止数据收集来补偿,在这种情况下,序列设计比固定设计更有效。因为O’Brien-Fleming或Haybittle-Peto设计在最后一次观察时的alpha与只有一次观察的固定设计的统计统计检验力非常相似,所以所需的样本量也非常相似。与固定设计相比,Pocock校正需要增加更多的最大样本量以达到所需的统计检验效力。
校正后的 alpha水平可以计算到许多位数,但这很快就会达到在现实生活中毫无意义的精度水平。如果你将alpha水平设置为0.0194、0.019或0.02,那么在你一生中将进行的所有检验中观察到的一类错误率并没有明显不同(参考 'significant digits'的概念)。即使在序列测试中计算和使用alpha阈值达到许多位数,大多数研究的混乱使这些alpha水平具有虚假的精确度(false precision)。 在解释数据时要记住这一点。
4.4 Alpha支出函数
到目前为止,所讨论的指定不同观察(look)的决策边界形状(shape of decision boundaries)的方法有一个重大的局限性 (Proschan et al., 2006)。它们需要预先确定观察次数(如 4 次),而且还需要预先确定中期观察的样本量(如在 25%、50%、75% 和 100% 的观察之后)。从逻辑上讲,在计划总样本量的25%处准确地停止数据收集并不总是可行的。Lan和DeMets (1983) 对序列检验相关文献做出了重要贡献,他们引入了alpha支出函数来校正alpha水平。在这种方法中,通过一个函数(alpha支出函数(alpha spending function))预先指定了整个观察累积的一类错误率,以控制总体显著性水平 \(\alpha\) 。
这些alpha支出函数的主要好处是可以控制中期分析的错误率,同时既不需要事先指定观察的次数也不需要指定时间。这使得alpha支出方法比早期的控制组序列设计中第一类错误的方法要灵活得多。使用alpha支出函数时,重要的是执行中期分析的决定不是基于收集的数据,因为这仍然会增加一类错误率。只要满足这个假设,就有可能在研究期间每次观察时更新alpha水平。
4.5 在研究期间更新边界
尽管即使是在偏离预先计划的观察次数或时间的情况下,alpha支出函数控制了第一类错误率,这确实需要根据已经观察到的信息量重新计算统计检验中使用的边界。让我们假设一个研究者设计了一项研究,对数据进行三次等距的观察(两次中期观察,一次最终观察),使用Pocock类型的alpha支出函数,结果将以双侧t检验的方式进行分析,总体期望的一类错误率为0.05,期望的统计检验效力为0.9,Cohen’s d 为0.5。一个先验的统计检验效力分析(a-priori power analysis,我们将在下一节解释)表明,如果我们计划在每个条件下观测65.4、130.9和196.3个观测值,我们在序列设计中就能达到预期的统计检验效力。由于被试个数为整数且有2个独立的小组,我们应该将上述数字四舍五入后分为两组,我们将在第一轮观察时收集66个观察值(每组33个),在第二轮观察时收集132个(每组66个),在第三轮观察时收集198个(每组99个)。下面的代码将计算每一个观察(look 或阶段)的alpha水平,以进行双侧检验:
design <- getDesignGroupSequential(kMax = 3,
typeOfDesign = "asP",
sided = 2,
alpha = 0.05,
beta = 0.1)
design$stageLevels * 2[1] 0.02264162 0.02173822 0.02167941现在想象一下,由于后勤问题(A logistical problem occurs when your plans didn’t account for something),我们在收集了76个观测值(每个条件38个)而不是计划的66个观测值的数据后,才设法分析数据。这样的后勤问题在实践中很常见,也是alpha支出函数为组序列设计而开发的主要原因之一。与计划不同,我们对数据的第一次观察并不是在收集总样本的33.3%的时候发生的,而是在达到76/198=38.4%个计划样本的时候发生的。我们可以根据当前的观察和未来计划的观察,重新计算每次观察数据时应该使用的alpha水平。而不是在三次观察时分别使用如上面所计算的0.0226、0.0217和0.0217的alpha水平(注意在类似Pocock的alpha支出函数中,alpha水平在每次观察时几乎相同,但不完全相同,不像Pocock校正,它们在每次观察时是相同的)。我们可以通过在下面的代码中使用informationRates明确指定信息率来校正它们。现在,第一次观察发生在计划样本的76/198处;第二次观察仍计划在样本的2/3处发生;最后一次观察在计划的最大样本量处。
design <- getDesignGroupSequential(
typeOfDesign = "asP",
informationRates = c(76/198, 2/3, 1),
alpha = 0.05,
sided = 2)
design$stageLevels * 2[1] 0.02532710 0.02043978 0.02164755更新后的alpha水平是:当前观察(look)为0.0253,第二次观察(look)为0.0204,最后一次观察(look)为0.0216。因此,第一次观察(look)中使用的alpha水平不是0.0226(按照最初的计划),而是稍高的0.0253。第二次观察将使用略低的alpha值0.0204,而不是0.0217。虽然差异很小,但事实上有一种正式的方法来控制alpha水平,可以灵活地查看与最初计划不同的时间,这一点非常有用。
如果最后观察的数据发生了变化,例如因为你无法收集到预定的样本量,或者由于其他不可预见的情况,你收集到的数据比计划的多,也可以校正alpha水平。由于研究者预注册了他们的研究,或使用注册报告发表,这种情况越来越普遍。有时他们最终得到的数据比计划的略多,这就出现了一个问题:他们应该用计划的样本量进行分析,还是分析所有的数据。分析所有收集到的数据可以防止浪费被试的应答,并使用所有可用的信息,但它增加了数据分析的灵活性(因为研究人员现在可以选择分析计划中的样本数据,或者分析他们收集到的所有数据)。Alpha支出函数使得研究人员可以分析所有数据,同时更新用于控制整体alpha水平的alpha水平来解决这个难题。
如果收集的数据比计划的多,我们就不能再使用被选择的alpha支出函数(即Pocock支出函数),而必须通过更新时间和alpha支出函数来提供一个用户定义的alpha支出函数(user-defined alpha spending function),以反映最后一次观察时实际发生的数据收集情况。假设在我们前面的例子中,第二次观察按原计划发生在计划收集的数据的2/3处,但最后一次观察发生在206个被试时,而不是198个被试时,我们可以计算出最后一次观察的最新alpha水平。考虑到目前的总样本量,我们需要重新计算早期观察的alpha水平,现在发生在76/206=0.369,132/206=0.641,最后一次观察是206/206=1。
第一次和第二次观察发生在我们第一次校正后计算出的校正后的alpha水平(alpha水平为0.0253和0.0204)。我们已经在前两次观察的时候支出了我们总alpha的一部分。我们可以看一下我们上面指定的设计结果中的”累计alpha支出”(Cumulative alpha spent),看看到目前为止我们支出了多少一类错误率:
我们看到我们在第一次观察后支出了0.0253,第二次观察后支出了0.0382。由此可知,在最后一次观察时支出我们一类错误率的剩余部分,总共是0.05。
在收集了比计划中更多的数据后,我们的实际alpha支出函数不再被Pocock支出函数所获取,因此改为指定一个用户定义的支出函数。我们可以在设定asUser设计后,通过设定userAlphaSpending 信息,使用下面的代码进行这些计算:
design <- getDesignGroupSequential(
typeOfDesign = "asUser",
informationRates = c(72/206, 132/206, 1),
alpha = 0.05,
sided = 2,
userAlphaSpending = c(0.0253, 0.0382, 0.05)
)
design$stageLevels * 2[1] 0.02530000 0.01987072 0.02075796之前观察的alpha水平与我们使用的alpha水平不一致,但最终的alpha水平(0.0208)给出了我们应该用于最终分析的alpha水平,基于比我们计划收集的样本量更大的样本量。如果我们收集了计划中的样本量,与我们会使用的alpha水平的差异确实较小(0.0216对0.0208),部分原因是所收集的样本量与我们计划的样本量差异较小。在实践中,这种alpha水平的小差异其实并不明显,但有一个正确的解决方案来处理收集比计划多的数据,同时控制一类错误率是非常有用的。如果使用序列设计,每当超额完成预注册中计划收集的样本量时,可以使用这些方法去校正。
4.6 序列设计的样本量
在最终观察时,与固定设计相比,序列设计是否需要更多的被试,取决于多重比较校正导致该次观察的alpha水平降低了多少。由于可以提前停止收集数据,序列设计平均需要更少的被试。首先,让我们检查在固定设计中我们需要多少被试,我们只分析一次数据。我们的alpha水平为0.05,二类(beta)错误为0.1,换句话说,所需的统计检验效力为90%。我们将执行一项检验,假定数据服从正态分布,我们的临界Z分数将为1.96,alpha水平为5%。
design <- getDesignGroupSequential(
kMax = 1,
typeOfDesign = "P",
sided = 2,
alpha = 0.05,
beta = 0.1
)
power_res <- getSampleSizeMeans(
design = design,
groups = 2,
alternative = 0.5,
stDev = 1,
allocationRatioPlanned = 1,
normalApproximation = FALSE)
print(power_res)Design plan parameters and output for means:
Design parameters:
Critical values : 1.96
Two-sided power : FALSE
Significance level : 0.0500
Type II error rate : 0.1000
Test : two-sided
User defined parameters:
Alternatives : 0.5
Default parameters:
Mean ratio : FALSE
Theta H0 : 0
Normal approximation : FALSE
Standard deviation : 1
Treatment groups : 2
Planned allocation ratio : 1
Sample size and output:
Number of subjects fixed : 170.1
Number of subjects fixed (1) : 85
Number of subjects fixed (2) : 85
Lower critical values (treatment effect scale) : -0.303
Upper critical values (treatment effect scale) : 0.303
Local two-sided significance levels : 0.0500
Legend:
(i): values of treatment arm i我们看到每组需要 85 名被试,(或 86 名,因为样本量实际上是 85.03 ,所需的观察值是四舍五入取整的,所以我们总共需要 172 名被试。其他统计检验效力分析软件,如G*Power,也会得出同样的所需样本量。我们现在可以用两次观察和一个类似Pocock的alpha支出函数来检验我们上面的设计,即一个alpha为0.05的双侧检验。我们将观察两次,预期真实效果为d=0.5(通过设定alternative为0.5,stDev为1)。
seq_design <- getDesignGroupSequential(
kMax = 2,
typeOfDesign = "asP",
sided = 2,
alpha = 0.05,
beta = 0.1
)
# Compute the sample size we need
power_res_seq <- getSampleSizeMeans(
design = seq_design,
groups = 2,
alternative = 0.5,
stDev = 1,
allocationRatioPlanned = 1,
normalApproximation = FALSE)
print(power_res_seq)Design plan parameters and output for means:
Design parameters:
Information rates : 0.500, 1.000
Critical values : 2.157, 2.201
Futility bounds (non-binding) : -Inf
Cumulative alpha spending : 0.03101, 0.05000
Local one-sided significance levels : 0.01550, 0.01387
Two-sided power : FALSE
Significance level : 0.0500
Type II error rate : 0.1000
Test : two-sided
User defined parameters:
Alternatives : 0.5
Default parameters:
Mean ratio : FALSE
Theta H0 : 0
Normal approximation : FALSE
Standard deviation : 1
Treatment groups : 2
Planned allocation ratio : 1
Sample size and output:
Reject per stage [1] : 0.6022
Reject per stage [2] : 0.2978
Early stop : 0.6022
Maximum number of subjects : 188.9
Maximum number of subjects (1) : 94.5
Maximum number of subjects (2) : 94.5
Number of subjects [1] : 94.5
Number of subjects [2] : 188.9
Expected number of subjects under H0 : 186
Expected number of subjects under H0/H1 : 172.7
Expected number of subjects under H1 : 132.1
Lower critical values (treatment effect scale) [1] : -0.451
Lower critical values (treatment effect scale) [2] : -0.323
Upper critical values (treatment effect scale) [1] : 0.451
Upper critical values (treatment effect scale) [2] : 0.323
Local two-sided significance levels [1] : 0.03101
Local two-sided significance levels [2] : 0.02774
Legend:
(i): values of treatment arm i
[k]: values at stage k第一次观测每个小组的样本量是 47.24 47.24,第二次观测是 94.47 94.47,这意味着我们现在收集了 190 而不是 172 个被试。这是每次观察降低alpha水平(从0.05到 0.028)的结果。 为了补偿每次降低的alpha水平,我们需要增加研究的样本量以达到相同的统计检验效力。
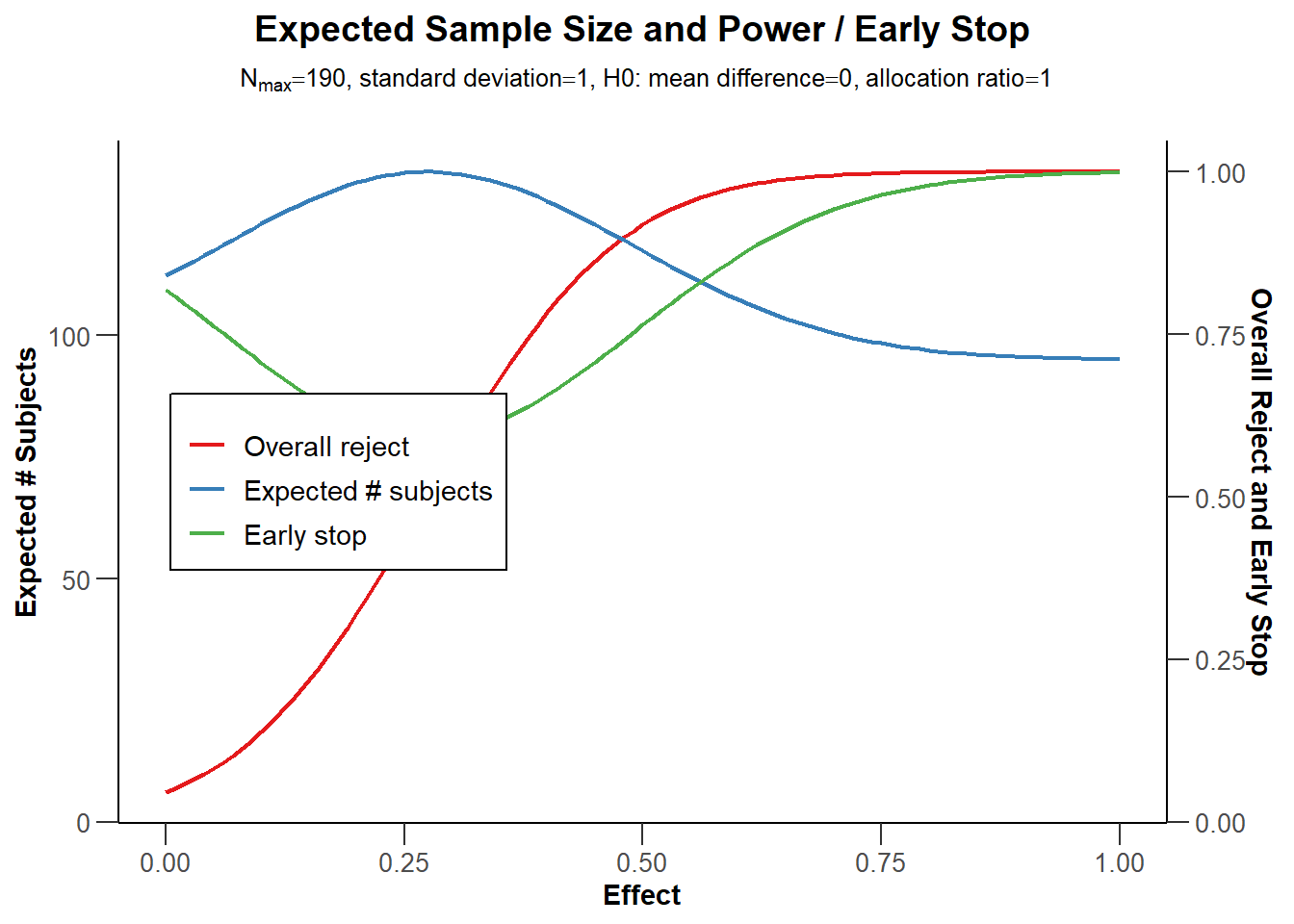
然而,最大的样本量并不是这种设计的预期样本量,因为我们有可能在序列设计中的较早的观察点上停止数据收集。从长远来看,如果d=0.5,我们使用Pocock类型的alpha支出函数,并忽略向上取整,因为我们只能收集一个完整的观测值,我们有时会收集 96 个被试,并在第一次观察后停止,其余时间继续收集 190 名被试。 正如我们在’Reject per stage’这一行中所看到的一样,第一次观察预计在研究的 0.6 停止,因为我们已经观察到一个显著的结果。 剩余的时间是 (1 - 0.6) = 0.4.
这意味着假设存在 d = 0.5的真实效应, 平均期待 的平均样本量是在每次观察时停止的概率乘以我们每次观察时收集的观测值数量,即 0.6 * 96 + 0.3 * 190 = 133.39. rpact 包在”\(H_1\) 下的预期受试者数量”下返回的数值为 132.06 - 微小的差异是由于 rpact 没有将观测值数量四舍五入)。 因此,假设真实效应量为 d = 0.5, 在任何一项研究中,我们可能需要收集比固定设计略多的数据(我们将收集 172),但平均而言,我们在序列设计中需要收集的观察数量更小。
因为统计检验效力是一条曲线,而真实的效应值是未知的,所以绘制一系列可能的效应值的统计检验效力可以有所帮助,这样我们就可以探索不同的真实效应值的预期样本量。
# Use getPowerMeans and set max N to 190 based on analysis above
sample_res <- getPowerMeans(
design = seq_design,
groups = 2,
alternative = seq(0, 1, 0.01),
stDev = 1,
allocationRatioPlanned = 1,
maxNumberOfSubjects = 190,
normalApproximation = FALSE)
plot(sample_res, type = 6)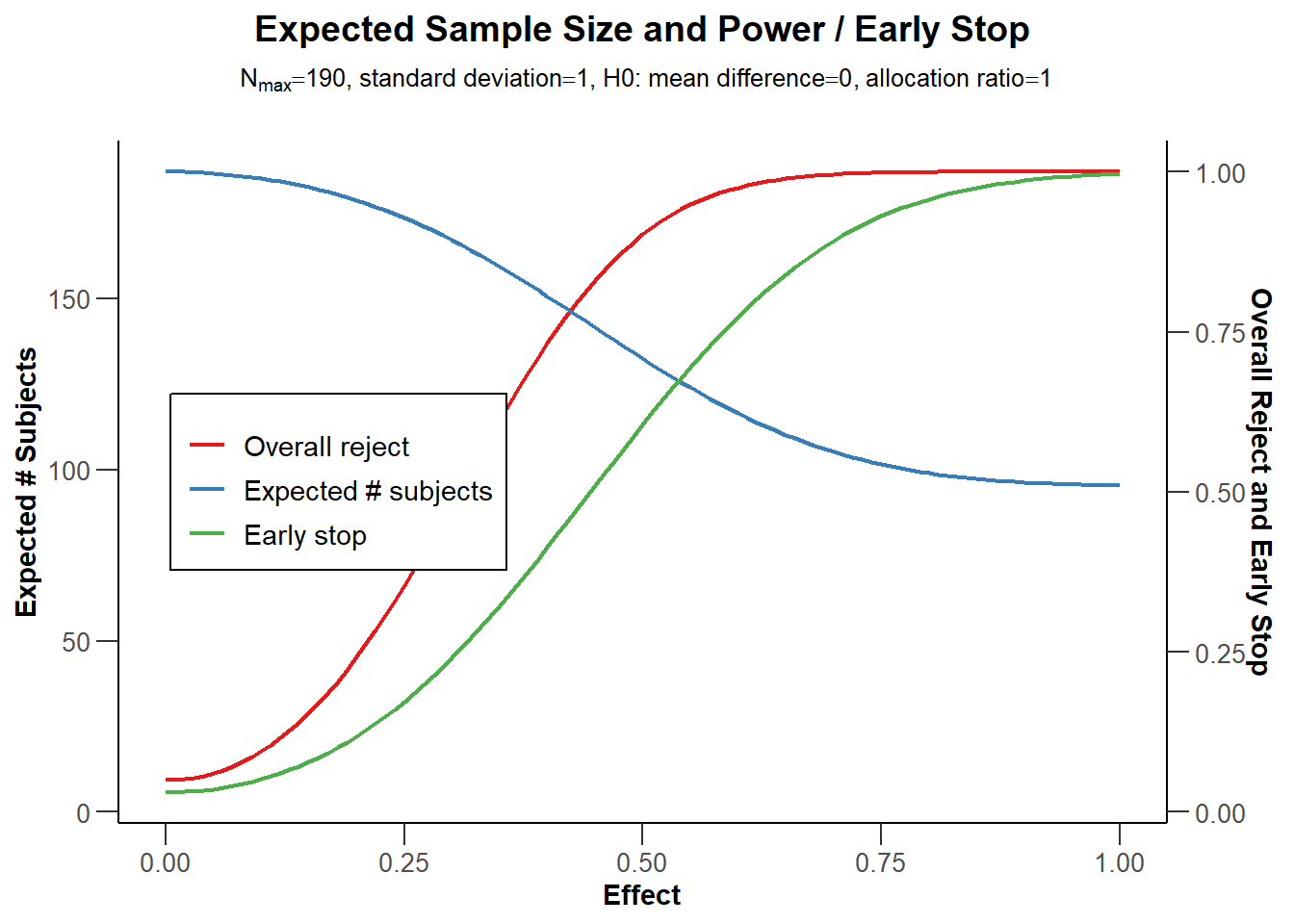
图 Figure 4.5 中的蓝线表示我们需要收集的预期观测值的数量。毫不奇怪,当真正的效应值为0时,我们几乎总是会继续收集数据到最后。只有当观察到一类错误时,我们才会停止,而第一类错误是很少见的,因此,预期的观察数非常接近于我们想要收集的最大样本量。在图的另一边,我们看到了真实效应值为d=1时的情况。有了这么大的效应值,我们在第一次观察时就会有很高的统计检验效力,而且我们几乎总是能够在第一次观察时就停下来。红线表示最后一次观察的统计检验效力,绿线表示提前停止的概率。
Pocock 校正导致最后一次观察时的alpha水平大幅降低,这需要增加样本量来补偿。正如我们之前所看到的,O’Brien-Fleming 支出函数不需要在最后一次观察时大幅降低alpha水平。正如下面的统计检验效力分析所显示的,在两次观察的情况下,这种设计在实践中根本不需要增加样本量。
seq_design <- getDesignGroupSequential(
kMax = 2,
typeOfDesign = "asOF",
sided = 2,
alpha = 0.05,
beta = 0.1
)
# Compute the sample size we need
power_res_seq <- getSampleSizeMeans(
design = seq_design,
groups = 2,
alternative = 0.5,
stDev = 1,
allocationRatioPlanned = 1,
normalApproximation = FALSE)
print(summary(power_res_seq))Sample size calculation for a continuous endpoint
Sequential analysis with a maximum of 2 looks (group sequential design), overall
significance level 5% (two-sided).
The sample size was calculated for a two-sample t-test, H0: mu(1) - mu(2) = 0,
H1: effect = 0.5, standard deviation = 1, power 90%.
Stage 1 2
Information rate 50% 100%
Efficacy boundary (z-value scale) 2.963 1.969
Overall power 0.2525 0.9000
Expected number of subjects 149.1
Number of subjects 85.3 170.6
Cumulative alpha spent 0.0031 0.0500
Two-sided local significance level 0.0031 0.0490
Lower efficacy boundary (t) -0.661 -0.304
Upper efficacy boundary (t) 0.661 0.304
Exit probability for efficacy (under H0) 0.0031
Exit probability for efficacy (under H1) 0.2525
Legend:
(t): treatment effect scale
-----
Design plan parameters and output for means:
Design parameters:
Information rates : 0.500, 1.000
Critical values : 2.963, 1.969
Futility bounds (non-binding) : -Inf
Cumulative alpha spending : 0.003051, 0.050000
Local one-sided significance levels : 0.001525, 0.024500
Two-sided power : FALSE
Significance level : 0.0500
Type II error rate : 0.1000
Test : two-sided
User defined parameters:
Alternatives : 0.5
Default parameters:
Mean ratio : FALSE
Theta H0 : 0
Normal approximation : FALSE
Standard deviation : 1
Treatment groups : 2
Planned allocation ratio : 1
Sample size and output:
Reject per stage [1] : 0.2525
Reject per stage [2] : 0.6475
Early stop : 0.2525
Maximum number of subjects : 170.6
Maximum number of subjects (1) : 85.3
Maximum number of subjects (2) : 85.3
Number of subjects [1] : 85.3
Number of subjects [2] : 170.6
Expected number of subjects under H0 : 170.4
Expected number of subjects under H0/H1 : 167.7
Expected number of subjects under H1 : 149.1
Lower critical values (treatment effect scale) [1] : -0.661
Lower critical values (treatment effect scale) [2] : -0.304
Upper critical values (treatment effect scale) [1] : 0.661
Upper critical values (treatment effect scale) [2] : 0.304
Local two-sided significance levels [1] : 0.003051
Local two-sided significance levels [2] : 0.049000
Legend:
(i): values of treatment arm i
[k]: values at stage k当我们收集到 172 名被试时这种设计就达到了预期的检验力–与我们不观察数据时的人数完全一致。 我们基本上可以自由获取观察数据,即预期的被试数量(假设d=0.5)下降到 149.1。 把观察(look)的次数增加到4次,只需要增加很小的被试数量就可以保持相同的统计检验力,但却进一步减少了预期的样本量。特别是对于保守的先验统计检验效力分析(a-priori power analysis),或对目标最小效应量进行先验统计检验效力分析时,而真正的效应值有相当大的可能性时,使用序列分析是一个非常有吸引力的选择。
4.7 无效停止
到目前为止,我们所讨论的序列设计只有在能够拒绝\(H_0\)的情况下才会在中期分析时停止。一个设计严谨的研究也会考虑到不存在效应的可能性,正如我们在 等价性检验一章中所讨论的。在序列分析文献中,为拒绝目标最小效应值的存在而停止的做法,被称为停止无效 (stopping for futility)。在最极端的情况下,在中期分析之后,也许不可能在最终分析时产生统计学上的显著结果。为了在一个假设的情况下说明这一点,设想在收集了192个观察值中的182个后,观察到的两个独立组别之间的平均差值是0.1,而研究的设计理念是认为值得的最小效应是0.5的平均差值。如果主要因变量是用7分的李克特量表测量的,那么即使对照组下剩下的5个被试都回答1,而实验组下剩下的被试都回答7,192次观察后的效应量也不会产生 p < \(\alpha\) 。如果你的研究目标是检测是否存在至少0.5的平均差值的影响,此时研究人员知道该目标将无法实现。由于最终结果无法产生显着影响,而在中期分析时停止研究称为非随机缩减 (non-stochastic curtailment)。
在不太极端但更普遍的情况下,研究仍有可能观察到显著效应,但概率可能非常小。考虑到已经观察到的到中期分析的数据,找到一个显著结果的概率被称为条件功效(conditional power)。对最初预期的效应值进行条件功效分析可能过于乐观,但使用观察到的效应值也是不可取的,因为它通常具有相当大的不确定性。一种建议是根据观察到的数据来更新校正预期的效应值。如果使用贝叶斯更新过程,这被称为预测能力 (predictive power) (Spiegelhalter et al., 1986)。可以使用自适应设计(adaptive designs),允许研究者根据中期分析结果增加最终的观察数量,而不增加一类错误率(见 Wassmer & Brannath (2016))。
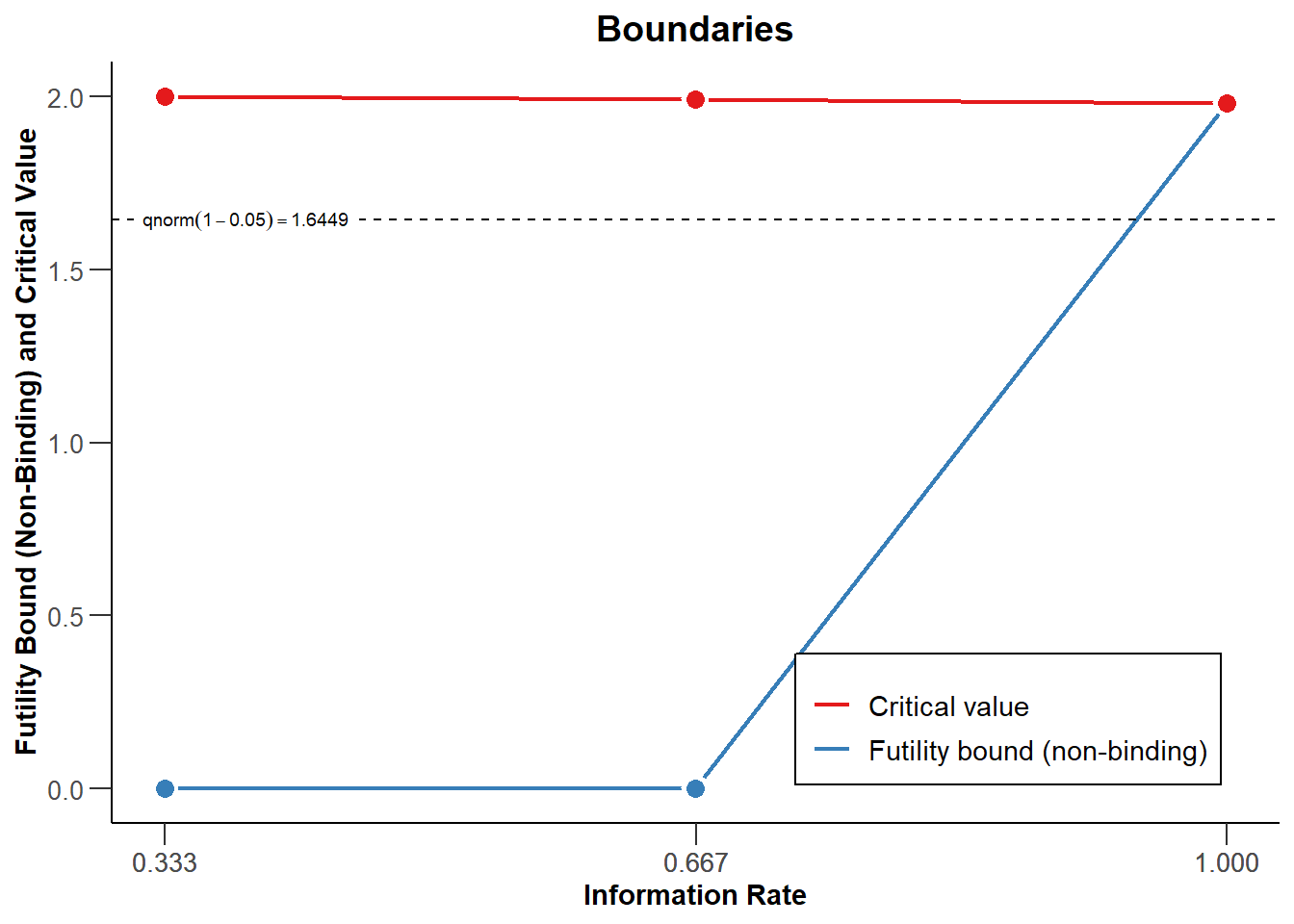
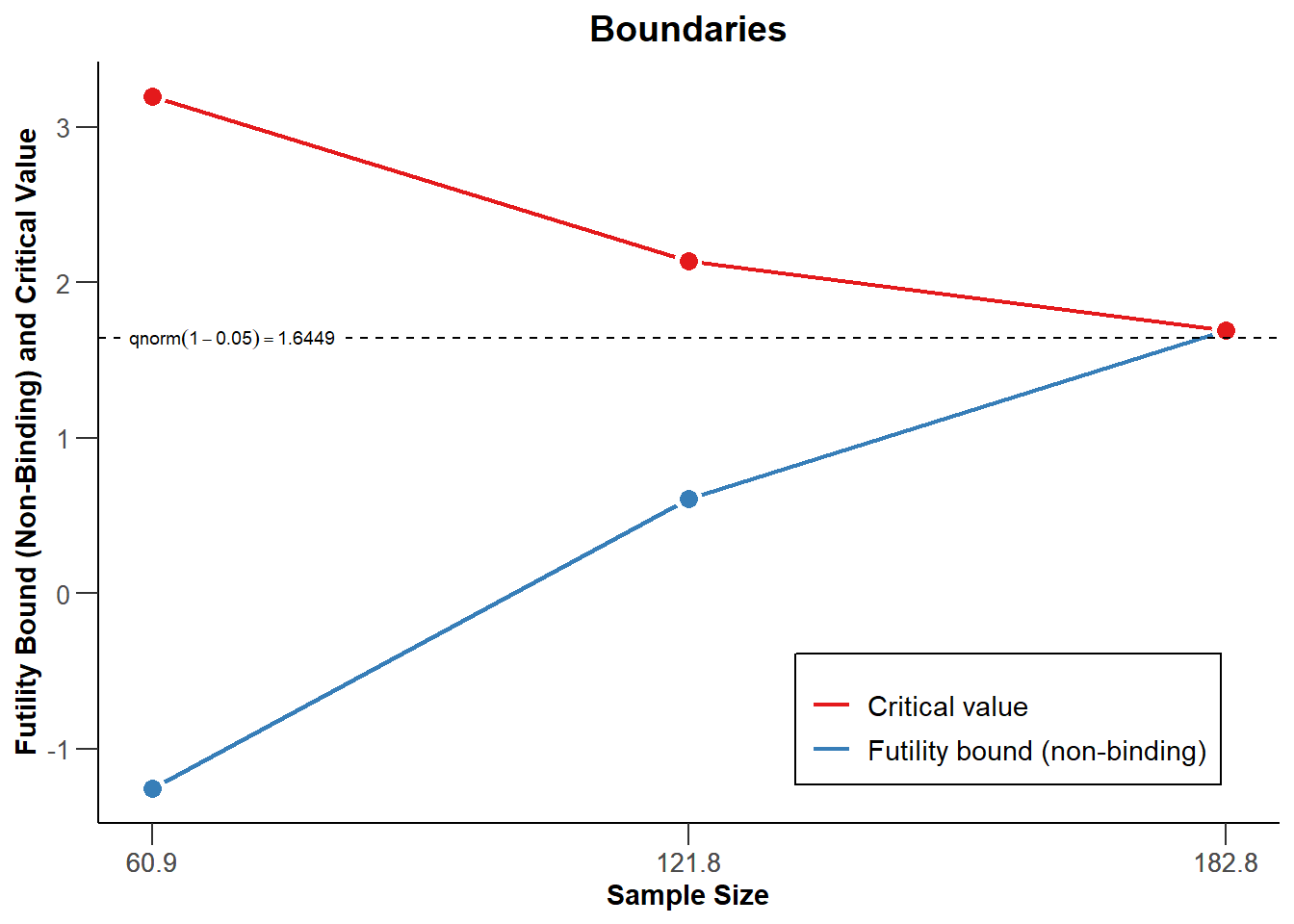
另外,如果观察到的效应值比预期的要小,人们可能会因无用而停止。作为一个简单的无效性停止规则的说明,设想一个研究者,只要观察到的效应值为零,或者观察到的效应值与预测的方向相反,就会因无效而停止。在图 Figure 4.6 中,红线表示证实效应显著的临界值。实质上,这意味着如果观察到的中期测试的Z分数为0或负数,数据收集将被终止。这可以通过在序列设计的设定中加入 futilityBounds = c(0,0) 来指定。研究者可以事先选择在满足无效标准时停止,即有约束力的无效规则,但通常建议保留继续收集数据的可能性(即无约束力的无效规则,通过设置 bindingFutility = FALSE 设定)。
在图 Figure 4.6 中我们看到一个顺序设计,当观察到的z分数大于红线指示的值时,数据收集停止以拒绝 \(H_0\),这是基于Pocock类型的alpha支出函数计算的(如图 Figure 4.3)。此外,当在中期分析中观察到z分数低于或等于0时,数据收集将停止,如蓝线所示。最后看,红色和蓝色线相交,因为我们要么在临界值处拒绝\(H_0\),要么无法拒绝\(H_0\)。
手动指定无效界线并不理想,因为我们有可能因为无法拒绝\(H_0\)而停止数据收集,出现二类错误的概率很高。更好的做法是通过直接控制数据的二类错误来设置无效界限。就像我们在中期分析中分配我们的一类错误率一样,我们可以在不同的观察(look)中分配我们的二类错误率,当我们不能以期望的二类错误率拒绝目标效应值时,可以决定停止无效性。
当一项研究被设计成使无效假设的显著性检验有90%的效力来检测d=0.5的效应时,10%的情况\(H_0\)不会被拒绝,而它应该被拒绝。在这10%的情况下,我们犯了二类错误,即虽然结论是不存在0.5的效应,而实际上,存在d=0.5(或更大)的效应。在针对最小效应量d=0.5的等效性实验中,当现实中存在d=0.5(或更大)的效应时,得出0.5或更大的效应不存在的结论被称为一类错误。我们错误地得出了效应实际上等于零的结论。因此,当\(H_0\)为d=0,\(H_1\)=d=0.5时,在NHST中属于二类错误,而在\(H_0\)为d=0.5,\(H_1\)为d=0 的等价性检验中属于一类错误 (Jennison & Turnbull, 2000)。因此,控制序列设计中的二类错误可以被看作是控制等效检验的一类错误,以对抗研究中的效应值。如果我们设计的研究有5%的一类错误率和同样低的二类错误率(如5%,或95%的检验效力),那么该研究就是对存在或不存在目标效应的一种信息性检验。
如果真实效应值为(接近)0,则因无效而停止的序列设计比不因无效而停止的设计更有效。添加基于beta支出函数的无效边界会降低检验效力,这需要通过增加样本量来补偿,但这可以通过更早地因无效而停止研究这一事实来补偿,这可以使设计更有效率。当无法指定最小的目标效应值时,研究人员可能不希望将无效停止纳入研究设计。要控制观察的二类错误率,需要选择beta 支出函数(beta-spending function),例如Pocock类型的beta支出函数、O’Brien-Fleming类型的beta支出函数或用户定义的 beta支出函数。例如,通过typeBetaSpending = “bsP”添加一个Pocock类型的beta支出函数。beta支出函数不需要与alpha支出函数相同。在rpact中,只能选择 beta支出函数进行定向(单侧)检验。毕竟,研究者可以考虑在两个方向上支持其假设的效应,而在相反方向上的效应作为拒绝备择假设的理由。
design <- getDesignGroupSequential(
kMax = 2,
typeOfDesign = "asP",
sided = 1,
alpha = 0.05,
beta = 0.1,
typeBetaSpending = "bsP",
bindingFutility = FALSE
)
plot(design)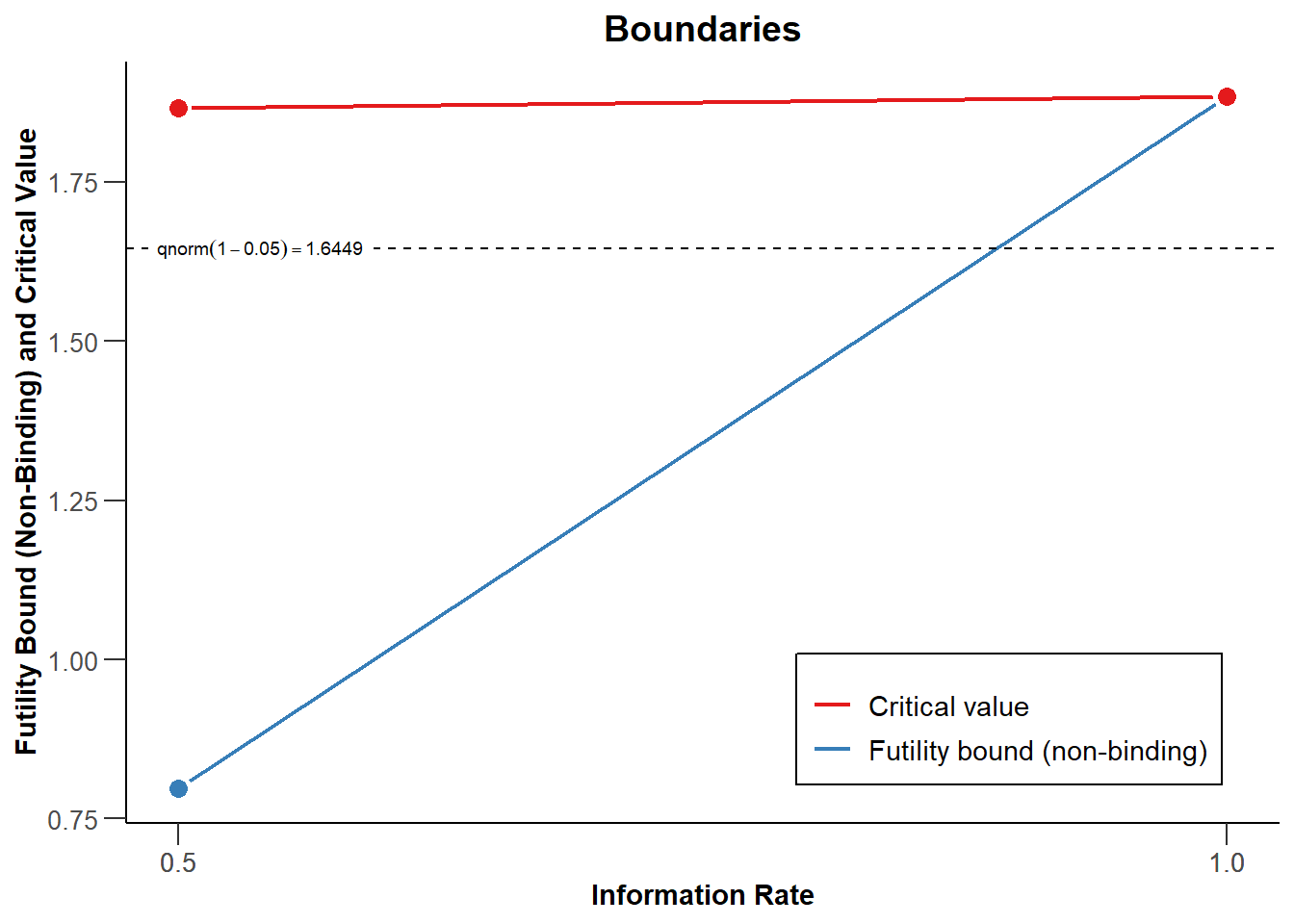
使用beta-spending函数,\(H_1\)下的预期被试数量将会增加,因此如果备择假设为真,设计一项能够因无效而停止的研究是有代价的。但是,\(H_0\)有可能为真,当它为真时,无效停止会减少预期的样本量。在图 Figure 4.8 中你可以看到,当真实效应量为0时,停止的概率(绿线)现在也很高,因为我们现在将因无效而停止,如果我们这样做,则预期样本量(蓝线)会比 Figure 4.5 低。设计具有较高信息价值的研究,在最终分析时拒绝有意义的效应的存在是很重要的,但提前因无效而停止是否是你想在研究中建立的一个选项,这需要考虑无效假设为真的概率和样本量的增加(也许很小)。
4.8 报告序列分析的结果
组顺序设计的开发是为了使用Neyman-Pearson统计推断方法有效地检验假设,其目标是决定如何行动,同时控制长期的错误率。组序列设计的目标不是量化证据的强度,或提供效果大小的准确估计 (Proschan et al., 2006). 尽管如此,在得出假设是否可以被拒绝的结论后,研究人员在报告 结果时往往还想解释效果量的估计值。
在解释序列设计中观察到的效应值时的一个挑战是,每当研究被提前停止时,当\(H_0\)被拒绝时,数据分析就有可能被停止,因为由于随机变异,在中期分析时观察到了一个大的效应值。这意味着在这些中期分析中观察到的效应量高估了真正的效应量。 正如 Schönbrodt et al. (2017) 所展示的,对采用序列设计的研究进行元分析会得出准确的效应量,因为早期停止的研究样本量较小,权重较低,这被那些达到最后观察的序列研究中较小的效应值估计值所补偿,因为其样本量较大,权重较高。然而,研究人员可能希望在进行元分析之前解释单个研究的效应值,在这种情况下,报告校正后的效应值估计值可能是有所帮助的。尽管序列分析软件只允许人们计算某些统计检验的校正后(adjusted)的效应值的估计值,但我们建议在可能的情况下同时报告校正后的效应值,并始终为未来的元分析报告未经校正的效应值的估计值。
在报告p值和置信区间时,也会出现类似的问题。当使用序列设计时,当\(H_0\)为真时,不考虑研究设计序列性的 p值分布不再均匀。假设\(H_0\)为真,p值是观察到的结果至少与观察到的结果一样极端的概率。确定至少一样极端(at least as extreme)意味着序列设计不再简单 (Cook, 2002)。为确定”至少同样极端”的含义,最常用的流程是根据就停止研究的观察来排列一系列序列分析的结果,当不同的研究同时停止时,早期停止的研究比后期停止的研究更极端,Z值更高的研究更极端 (Proschan et al., 2006)。这被称为分阶段排序(stagewise ordering),即与研究后期的拒绝相比,将早期的拒绝视为反对\(H_0\)的更有力证据 (Wassmer & Brannath, 2016)。鉴于p值和置信区间之间的直接关系,研究者也开发了序列设计的置信区间。
然而,报告校正后的p值和置信区间可能会受到批评。在序列设计之后,基于Neyman-Pearson 的框架,得出以下结论是正确的解释: \(H_0\)被拒绝,备择假设被拒绝,或者结果不确定。在序列设计之后报告校正后的p值的原因是让读者将其解释为证据的一种衡量标准。Dupont (1983) 为质疑校正后的p值能否有效衡量证据强度提供了很好的论据。此外,对Neyman-Pearson统计推断方法的严格解释也为反对将p值解释为证据度量提供了论据 (Lakens, 2022)。因此,如果研究人员有兴趣传达\(H_0\)数据中相对于备择假设的证据,建议报告可能性或贝叶斯系数,研究者可以在数据收集完成后报告和解释这些数据。报告与α水平有关的未经调整的p值,可以传达拒绝假设的依据,尽管这对于研究人员执行基于p值的元分析(例如,p曲线或z曲线分析,如bias detection一章中所解释的),序列的p值是连续可能很重要。校正后的置信区间是评估观察到的效应估计值相对于其在中期或最终观察得到的观察数据的变异性的有效工具。请注意,校正后的参数估计值只在统计软件中适用于药物试验中少数常用的设计,如组间平均差值的比较,或生存分析(survival analysis)。
下面,我们看到与我们开始时一样的序列设计,有两次观察和一个Pocock类型的alpha支出函数。在完成每组95个参与者的预计样本量的研究后(我们在一次观察时收集48个参与者,在第二次观察时收集其余47个参与者),我们现在可以使用函数getDataset输入观察数据。输入每个阶段的平均值和标准差,所以在第二次观察时,只用每组后95名的参与者的数据来计算平均值(1.51 和 1.01)和标准差(1.03 和 0.96)。
design <- getDesignGroupSequential(
kMax = 2,
typeOfDesign = "asP",
sided = 2,
alpha = 0.05,
beta = 0.1
)
dataMeans <- getDataset(
n1 = c(48, 47),
n2 = c(48, 47),
means1 = c(1.12, 1.51), # for directional test, means 1 > means 2
means2 = c(1.03, 1.01),
stDevs1 = c(0.98, 1.03),
stDevs2 = c(1.06, 0.96)
)
res <- getAnalysisResults(
design,
equalVariances = TRUE,
dataInput = dataMeans
)
print(summary(res))[PROGRESS] Stage results calculated [0.0832 secs]
[PROGRESS] Conditional power calculated [0.0864 secs]
[PROGRESS] Conditional rejection probabilities (CRP) calculated [0.0019 secs]
[PROGRESS] Repeated confidence interval of stage 1 calculated [1.66 secs]
[PROGRESS] Repeated confidence interval of stage 2 calculated [1.63 secs]
[PROGRESS] Repeated confidence interval calculated [3.29 secs]
[PROGRESS] Repeated p-values of stage 1 calculated [0.6015 secs]
[PROGRESS] Repeated p-values of stage 2 calculated [0.6014 secs]
[PROGRESS] Repeated p-values calculated [1.21 secs]
[PROGRESS] Final p-value calculated [0.0033 secs]
[PROGRESS] Final confidence interval calculated [0.178 secs] Analysis results for a continuous endpoint
Sequential analysis with 2 looks (group sequential design).
The results were calculated using a two-sample t-test (two-sided, alpha = 0.05),
equal variances option.
H0: mu(1) - mu(2) = 0 against H1: mu(1) - mu(2) != 0.
Stage 1 2
Fixed weight 0.5 1
Efficacy boundary (z-value scale) 2.157 2.201
Cumulative alpha spent 0.0310 0.0500
Stage level 0.0155 0.0139
Cumulative effect size 0.090 0.293
Cumulative (pooled) standard deviation 1.021 1.013
Overall test statistic 0.432 1.993
Overall p-value 0.3334 0.0238
Test action continue accept
Conditional rejection probability 0.0073
95% repeated confidence interval [-0.366; 0.546] [-0.033; 0.619]
Repeated p-value >0.5 0.0819
Final p-value 0.0666
Final confidence interval [-0.020; 0.573]
Median unbiased estimate 0.281
-----
Analysis results (means of 2 groups, group sequential design):
Design parameters:
Information rates : 0.500, 1.000
Critical values : 2.157, 2.201
Futility bounds (non-binding) : -Inf
Cumulative alpha spending : 0.03101, 0.05000
Local one-sided significance levels : 0.01550, 0.01387
Significance level : 0.0500
Test : two-sided
User defined parameters: not available
Default parameters:
Normal approximation : FALSE
Direction upper : TRUE
Theta H0 : 0
Equal variances : TRUE
Stage results:
Cumulative effect sizes : 0.0900, 0.2928
Cumulative (pooled) standard deviations : 1.021, 1.013
Stage-wise test statistics : 0.432, 2.435
Stage-wise p-values : 0.333390, 0.008421
Overall test statistics : 0.432, 1.993
Overall p-values : 0.33339, 0.02384
Analysis results:
Assumed standard deviation : 1.013
Actions : continue, accept
Conditional rejection probability : 0.007317, NA
Conditional power : NA, NA
Repeated confidence intervals (lower) : -0.36630, -0.03306
Repeated confidence intervals (upper) : 0.5463, 0.6187
Repeated p-values : >0.5, 0.08195
Final stage : 2
Final p-value : NA, 0.06662
Final CIs (lower) : NA, -0.02007
Final CIs (upper) : NA, 0.5734
Median unbiased estimate : NA, 0.2814 想象一下,我们进行了一项研究,计划最多对数据进行两次等距观察。在该研究中,我们进行alpha为0.05的双侧检验了,使用Pocock类型的 alpha支出函数,并在最后观察时检验两个组之间的均值差异。基于具有两个等距观察的Pocock类型的alpha支出函数,双侧t检验的alpha水平是 0.003051, 和 0.0490。因此,我们可以在两次观察后拒绝\(H_0\)。但我们也想报告一个效应值,并校正p值和置信区间。
结果表明,第一次观察后的操作是继续收集数据,并且可以在第二次观察时拒绝\(H_0\)。“总体效应值”(Overall effect size)行提供了未校正的平均差异,最后观察是0.293。“无偏估计中位数”(Median unbiased estimate)提供了校正后的更低的平均差异,“最终置信区间”(Final confidence interval)提供了校正后的置信区间,并给出结果0.281, 95% CI [-0.02, 0.573]。
单侧检验的未校正 p 值在Overall p-value”行中报告。我们双侧检验的实际 p 值将是原来的两倍大,即0.6668, 0.0477。最终查看时校正后的 p 值在”Final p-value”行中提供,为0.06662。
4.9 测试一下你自己
Q1:序列分析可以提高你执行的研究的效率。对于研究人员仅在可以拒绝\(H_0\)时才停止的顺序设计(并且没有指定因无效而停止的规则),以下哪项陈述是正确的?
- 序列分析将减少你要进行的每项研究的样本量
- 序列分析将平均减少你将进行的研究的样本量
- 只要有真实的效应,序列分析将平均减少你将进行的研究的样本量(当没有规定因无效而停止的规则时)
- 序列分析平均需要与固定设计相同的样本量,但提供更多的灵活性
Q2:序列分析和选择性停止之间的区别是什么?
- 唯一的区别是,顺序分析是透明的报告,而选择性停止通常不在论文中披露
- 在序列分析中,第一类错误率是可控的,而在选择性停止中,第一类错误率是膨胀的
- 在选择性停止中,只有当观察到一个重要的结果时才会终止数据收集,而在顺序分析中,当确定没有一个有意义的影响时,数据收集也可以停止
- 在序列分析中,不可能设计一个在每个参与者之后就分析数据的研究,而在选择性停止中可以这样做
Q3:Pocock校正的定义特征是什么?
- 它对早期观察使用非常保守的alpha水平,最后观察的alpha水平接近固定设计中未调整的alpha水平
- 它在每次观察时使用相同的 alpha 水平(或者在使用Pocock型的alpha支出函数时,在每次观察时几乎使用相同的alpha水平)
- 它在每次中期分析时使用临界值3,并在最后一次观察时使用剩余的一类错误率
- 它有一个可以选择的参数,以便在早期中期分析中更保守或更自由地使用一类错误率
Q4:O’Brien-Fleming校正的一个优势是最后一次观察时的alpha水平接近alpha水平。为什么?
- 这意味着基于先验功效分析(取决于alpha水平)的样本量接近固定设计中的样本量,同时允许额外观察数据
- 这意味着与固定设计相比,一类错误率并没有膨胀一点点
- 这意味着与固定设计相比,一类错误率只是稍微保守一点
- 这意味着基于先验功效分析(取决于alpha水平)的样本量始终与固定设计中的样本量相同,同时允许额外观察数据
Q5:研究人员使用顺序设计进行研究,观察数据5次,双侧测试所需的总alpha水平为0.05,并选择Pocock校正。在继续收集数据至第三次查看后,研究人员观察到p值为0.011。哪个论述是对的?注意:请记住rpact返回单侧alpha水平。你可以通过替换0并指定 typeOfDesign 来使用以下代码:
- 研究人员可以拒绝原假设并可以终止数据收集
- 研究人员未能拒绝原假设,需要继续收集数据
Q6:研究人员使用序列设计进行研究,观察数据5次,所需的总体alpha水平为0.05,并选择O’Brien-Fleming校正。在继续收集数据至第三次观察后,研究人员观察到 p 值为 0.011。哪个陈述是正确的(你可以使用与 Q5 相同的代码)?
- 研究人员可以拒绝原假设并可以终止数据收集
- 研究人员未能拒绝原假设,需要继续收集数据
Q7:对于Q5中的设计(使用Pocock 校正),达到80%功效所需的样本量是多少(默认值——你可以通过指定不同于 beta = 0.2 的值来更改默认值getDesignGroupSequential 函数),效应量为d = 0.5(等于平均差为0.5,标准差为1)。你可以使用下面的代码。
- 64个(每个独立组 32 个)
- 128 (每个独立组 64)
- 154 (每个独立组 77)
- 158 (每个独立组 79)
Q8:对于Q5中的设计,对于只有一次观察的固定设计,在 d = 0.5 的效应量达到80%功效所需的样本量是多少?首先更新设计(通过将 kMax 更改为 1),然后重新运行函数 getSampleSizeMeans。
- 64 个(每个独立组 32 个)
- 128 (每个独立组 64)
- 154 (每个独立组 77)
- 158 (每个独立组 79)
我们看到由于选择了Pocock校正和观察数量(5,这导致最终观察的alpha水平较低),样本量增加了很多。序列设计的最大样本量与固定设计的样本量之比称为 膨胀因子(inflation factor),它与效应量无关。虽然先验功效分析尚未针对所有类型的检验进行编程,但膨胀因子可用于计算相对于任何测试的固定设计所需的增加的观察次数。研究人员可以使用他们通常使用的工具对固定设计执行先验功效分析,并将观察总数乘以膨胀因子以确定序列设计所需的样本量。可以使用getDesignCharacteristics函数检索膨胀因子。
Q9: 首先,重新运行代码以创建序列设计,其中五次观察Q5中使用的数据。然后,运行下面的代码,找到膨胀因子。与固定设计相比,使用 Pocock校正的具有5个观察的序列设计的膨胀因子或所需的样本量增加是多少?请注意,在计算膨胀因子时,rpact不会将每组的观察次数四舍五入为整数。
- 膨胀因子是1
- 膨胀因子是1.0284
- 膨胀因子是1.2286
- 膨胀因子是1.2536
Q10: 我们看到膨胀系数相当大,而且有一定的概率,我们将不得不收集比使用固定设计更多的观测值。重新运行Q7的代码(对于有5次观察的Pocock设计)。我们看到,平均而言,如果存在一个0.5的真实效应,我们将比固定设计更有效率。在\(H_1\)下,由rpact提供的预期被试数量是多少?
- 101.9
- 104.3
- 125.3
- 152.8
我们看到序列设计平均来说会比固定设计更有效率,但关于所使用的具体序列设计之间的权衡,以及可能的好处是否值得收集额外数据的风险,必须根据具体情况来决定。
Q11: 首先,重新运行代码,创建一个顺序设计,对Q6中使用的数据进行5次观察(因此使用O’Brien-Fleming校正)。然后,运行下面的代码,找出这个设计的膨胀系数。什么膨胀系数?
- 膨胀系数是1
- 膨胀系数是1.0284
- 膨胀系数是1.2286
- 膨胀系数是1.2536
Q12: 也可以因无用而停止(或拒绝存在感兴趣的特定效应)。研究者应该在有约束力和无约束力的beta支出函数之间做出决定,但他们不需要在有约束力和无约束力的alpha支出函数之间做出决定。如果研究者在中期分析时观察到一个有统计学意义的结果,但决定不停止数据收集,而是继续收集数据(例如,为了获得更精确的效应量估计),会有什么后果?
- 第一类错误率会膨胀,第二类错误率也会膨胀
- 第一类错误率会膨胀,而第二类错误率不会膨胀
- 第一类错误率不会膨胀,第二类错误率会膨胀
- 第一类错误率不会膨胀,第二类错误率也不会膨胀
Q13: 在下图中,您可以看到序列设计的t分数边界停止拒绝\(H_0\)(红线)和拒绝\(H_1\)(蓝线)。在第二次临观察时,你执行了一项检验,观察到t值为2。您会做出哪个决定?
- 你可以拒绝\(H_0\)并停止数据收集
- 你可以拒绝\(H_1\)并停止数据收集
- 你拒绝\(H_0\)和\(H_1\)并停止数据收集
- 你未能同时拒绝\(H_0\)和\(H_1\)并继续收集数据
4.9.1 10.9.1 开放性问题
序列分析和选择性停止有什么区别?
与固定设计相比,使用序列设计的可能好处是什么?
因无效而停止数据收集是什么意思?
Pocock和 O’Brien-Fleming方法在观察上指出alpha的理念有何不同?
使用O’Brien-Fleming校正时最终观察的alpha水平接近未校正的alpha水平有什么优势?
Pocock和O’Brien-Fleming校正与Lan和DeMets开发的相应Pocock和O’Brien-Fleming alpha支出函数有什么区别?
即使序列设计的最大样本量略大于固定设计的样本量,为什么序列设计仍然可以更有效?
什么时候合并无效停止规则会提高顺序设计的效率?
平均而言,在序列设计中提前停止对效应量估计有何影响?报告时不校正效应量估计的理由是什么?