
12 Bias detection
Diagoras, who is called the atheist, being at Samothrace, one of his friends showed him several pictures of people who had endured very dangerous storms; “See,” says he, “you who deny a providence, how many have been saved by their prayers to the Gods.” “Ay,” says Diagoras, “I see those who were saved, but where are those painted who were shipwrecked?” The Tusculanae Disputationes, Cicero, 45 BC.
Bias can be introduced throughout the research process. It is useful to prevent this or to detect it. Some researchers recommend a skeptical attitude towards any claim you read in the scientific literature. For example, the philosopher of science Deborah Mayo (2018) writes: “Confronted with the statistical news flash of the day, your first question is: Are the results due to selective reporting, cherry picking, or any number of other similar ruses?”. You might not make yourself very popular if this is the first question you ask a speaker at the next scientific conference you are attending, but at the same time it would be naïve to ignore the fact that researchers more or less intentionally introduce bias into their claims.
At the most extreme end of practices that introduce bias into scientific research is research misconduct: Making up data or results, or changing or omitting data or results such that the research isn’t accurately represented in the research record. For example, Andrew Wakefield authored a fraudulent paper in 1998 that claimed a link between the measles, mumps, and rubella (MMR) vaccine and autism. It was retracted in 2010, but only after it caused damage to trust in vaccines among some parts of the general population. Another example from psychology concerned a study by James Vicary on subliminal priming. He claimed to have found that by flashing ‘EAT POPCORN’ and ‘DRINK COCA-COLA’ subliminally during a movie screen in a cinema, the sales of popcorn and Coca-Cola had increased with 57.5 and 18.1 percent, respectively. However, it was later found that Vicary most likely committed scientific fraud, as there was no evidence that the study was ever performed (Rogers, 1992--1993). The website Retraction Watch maintains a database that tracks reasons why scientific papers are retracted, including data fabrication. It is unknown how often data fabrication occurs in practice, but as discussed in the chapter on research integrity, we should expect that at least a small percentage of scientists have fabricated, falsified or modified data or results at least once.
A different category of mistakes are statistical reporting errors, which range from reporting incorrect degrees of freedom, to reporting p = 0.056 as p < 0.05 (Nuijten et al., 2015). Although we should do our best to prevent errors, everyone makes them, and data and code sharing become more common, it will become easier to detect errors in the work of other researchers. As Dorothy Bishop (2018) writes: “As open science becomes increasingly the norm, we will find that everyone is fallible. The reputations of scientists will depend not on whether there are flaws in their research, but on how they respond when those flaws are noted.”
Statcheck is software that automatically extracts statistics from articles and recomputes their p-values, as long as statistics are reported following guidelines from the American Psychological Association (APA). It checks if the reported statistics are internally consistent: Given the test statistics and degrees of freedom, is the reported p-value accurate? If it is, that makes it less likely that you have made a mistake (although it does not prevent coherent mistakes!) and if it is not, you should check if all the information in your statistical test is accurate. Statcheck is not perfect, and it will make Type 1 errors where it flags something as an error when it actually is not, but it is an easy to use tool to check your articles before you submit them for publication, and early meta-scientific work suggests it can reduce statistical reporting errors (Nuijten & Wicherts, 2023).
Some inconsistencies in data are less easy to automatically detect, but can be identified manually. For example, Brown & Heathers (2017) show that many papers report means that are not possible given the sample size (known as the GRIM test). For example, Matti Heino noticed in a blog post that three of the reported means in the table in a classic study by Festinger and Carlsmith are mathematically impossible. With 20 observations per condition, and a scale from -5 to 5, all means should end in a multiple of 1/20, or 0.05. The three means ending in X.X8 or X.X2 are not consistent with the reported sample size and scale. Of course, such inconsistencies can be due to failing to report that there was missing data for some of the questions, but the GRIM test has also been used to uncover scientific misconduct.
12.1 Publication bias
Publication bias is one of the biggest challenges that science faces. Publication bias is the practice of selectively submitting and publishing scientific research, often based on whether or not the results are ‘statistically significant’ or not. The scientific literature is dominated by these statistically significant results. In 1959 Sterling (1959) counted how many hypothesis tests in 4 journals in psychology yielded significant results, and found that 286 out of 294 articles examined (i.e., 97%) rejected the null hypothesis with a statistically significant result. A replication by Bozarth and Roberts (1972) yielded an estimate of 94%.
At the same time, we know that many studies researchers perform do not yield significant results. When scientists only have access to significant results, but not to all results, they are lacking a complete overview of the evidence for a hypothesis (Smart, 1964). In extreme cases, selective reporting can lead to a situation where there are hundreds of statistically significant results in the published literature, but no true effect because there are even more non-significant studies that are not shared. This is known as the file-drawer problem, when non-significant results are hidden away in file-drawers (or nowadays, folders on your computer) and not available to the scientific community. Such bias is most likely to impact the main hypothesis test a researcher reports, as whether or not they have an interesting story to tell often depends on the result of this one test. Bias is less likely to impact papers without a main hypothesis that needs to be significant to for the narrative in the manuscript, for example when researchers just describe effect sizes across a large correlation table of tests that have been performed. Every scientist should work towards solving publication bias, because it is extremely difficult to learn what is likely to be true as long as scientists do not share all their results. Greenwald (1975) even considers selectively reporting only significant results an ethical violation.

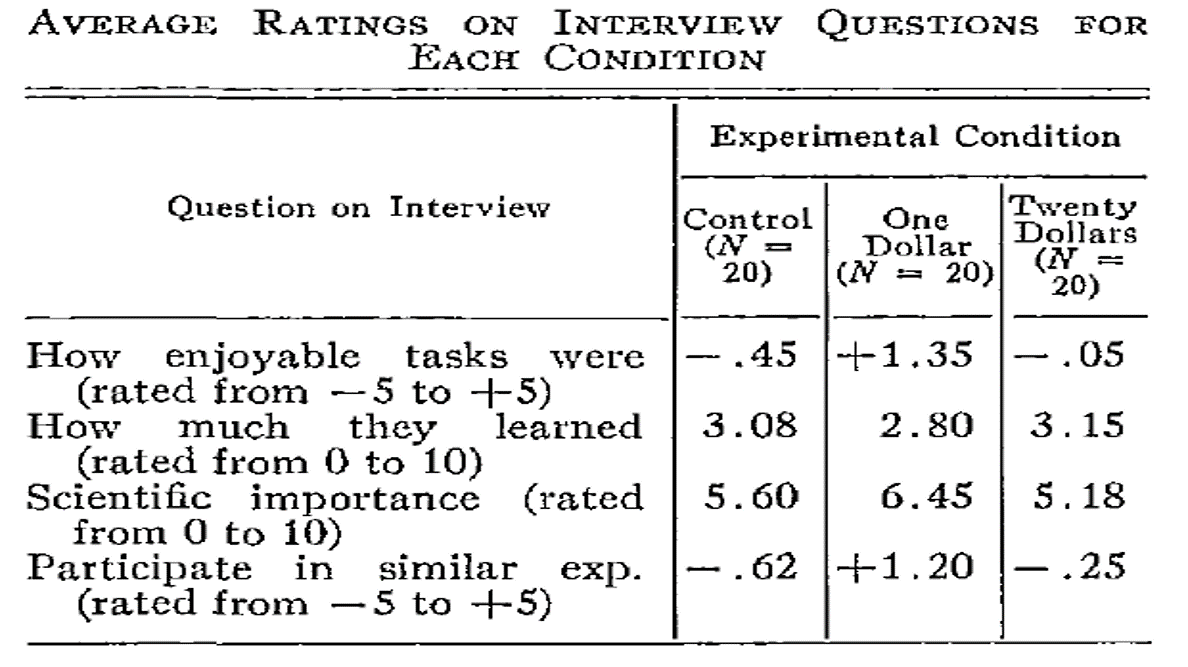
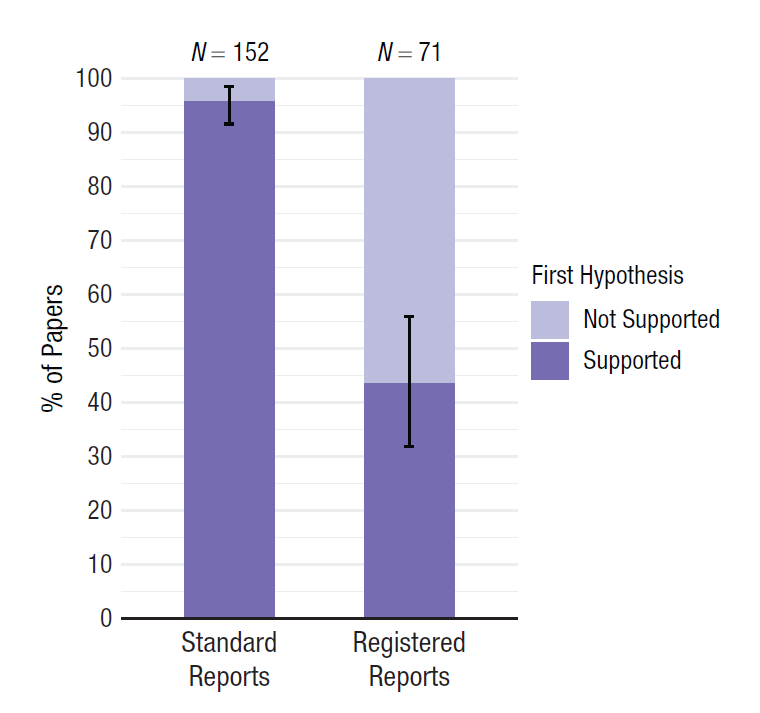
Publication bias can only be fixed by making all your research results available to fellow scientists, irrespective of the p-value of the main hypothesis test. Registered Reports are one way to combat publication bias, as this type of scientific article is reviewed based on the introduction, method, and statistical analysis plan, before the data is collected (Chambers & Tzavella, 2022; Nosek & Lakens, 2014). After peer review by experts in the field, who might suggest improvements to the design and analysis, the article can get an ‘in principle acceptance’, which means that as long as the research plan is followed, the article will be published, regardless of the results. This should facilitate the publication of null results, and as shown in Figure 12.4, an analysis of the first published Registered Reports in psychology revealed that 31 out of 71 (44%) articles observed positive results, compared to 146 out of 152 (96%) of comparable standard scientific articles published during the same time period (Scheel et al., 2021).
In the past, Registered Reports did not exist, and scientists did not share all results (Franco et al., 2014; Greenwald, 1975; Sterling, 1959), and as a consequence, we have to try to detect the extent to which publication bias impacts our ability to accurately evaluate the literature. Meta-analyses should always carefully examine the impact of publication bias on the meta-analytic effect size estimate - even though only an estimated 57% of meta-analyses published in Psychological Bulletin between 1990 to 2017 report that they assessed publication bias (Polanin et al., 2020). In more recent meta-analyses published in educational research, 82% used bias detection tests, but the methods used were typically far from the state-of-the-art (Ropovik et al., 2021). Several techniques to detect publication bias have been developed, and this continues to be a very active field of research. All techniques are based on specific assumptions, which you should consider before applying a test (Carter et al., 2019). There is no silver bullet: None of these techniques can fix publication bias. None of them can tell you with certainty what the true meta-analytic effect size is corrected for publication bias. The best these methods can do is detect publication bias caused by specific mechanisms, under specific conditions. Publication bias can be detected, but it cannot be corrected.
In the chapter on likelihoods we saw how mixed results are to be expected, and can be strong evidence for the alternative hypothesis. It is not only the case that mixed results should be expected, but exclusively observing statistically significant results, especially when the statistical power is low, is very surprising. With the commonly used lower limit for statistical power of 80%, we can expect a non-significant result in one out of five studies when there is a true effect. Some researchers have pointed out that not finding mixed results can be very unlikely (or ‘too good to be true’) in a set of studies (Francis, 2014; Schimmack, 2012). We don’t have a very good feeling for what real patterns of studies look like, because we are continuously exposed to a scientific literature that does not reflect reality. Almost all multiple study papers in the scientific literature present only statistically significant results, even though this is unlikely.
The online Shiny app we used to compute binomial likelihoods displays, if you scroll to the bottom of the page, binomial probabilities to find multiple significant findings given a specific assumption about the power of the tests. Francis (2014) used these binomial likelihoods to calculate the test of excessive significance (Ioannidis & Trikalinos, 2007) for 44 articles published in the journal Psychological Science between 2009 and 2012 that contained four studies or more. He found that for 36 of these articles, the likelihood of observing four significant results, given the average power computed based on the observed effect sizes, was less than 10%. Given his choice of an alpha level of 0.10, this binomial probability is a hypothesis test, and allows the claims (at a 10% alpha level) that whenever the binomial probability of the number of statistically significant results is lower than 10%, the data is surprising, and we can reject the hypothesis that this is an unbiased set of studies. In other words, it is unlikely that this many significant results would be observed, suggesting that publication bias or other selection effects have played a role in these articles.
One of these 44 articles had been co-authored by myself (Jostmann et al., 2009). At this time, I knew little about statistical power and publication bias, and being accused of improper scientific conduct was stressful. And yet, the accusations were correct - we had selectively reported results, and selectively reported analyses that worked. Having received virtually no training on this topic, we educated ourselves, and uploaded an unpublished study to the website psychfiledrawer.org (which no longer exists) to share our filedrawer. Some years later, we assisted when Many Labs 3 included one of the studies we had published in the set of studies they were replicating (Ebersole et al., 2016), and when a null result was observed, we wrote “We have had to conclude that there is actually no reliable evidence for the effect” (Jostmann et al., 2016). I hope this educational materials prevents others from making a fool of themselves as we did.
12.2 Bias detection in meta-analysis
New methods to detect publication bias are continuously developed, and old methods become outdated (even though you can still see them appear in meta-analyses). One outdated method is known as fail-safe N. The idea was to calculate the number of non-significant results one would need to have in file-drawers before an observed meta-analytic effect size estimate would no longer be statistically different from 0. It is no longer recommended, and Becker (2005) writes “Given the other approaches that now exist for dealing with publication bias, the failsafe N should be abandoned in favor of other, more informative analyses”. Currently, the only use fail-safe N has is as a tool to identify meta-analyses that are not state-of-the-art.
Before we can explain a second method (Trim-and-Fill), it’s useful to explain a common way to visualize meta-analyses, known as a funnel plot. In a funnel plot, the x-axis is used to plot the effect size of each study, and the y-axis is used to plot the ‘precision’ of each effect size (typically, the standard error of each effect size estimate). The larger the number of observations in a study, the more precise the effect size estimate, the smaller the standard error, and thus the higher up in the funnel plot the study will be. An infinitely precise study (with a standard error of 0) would be at the top of y-axis. The script below simulates meta-analyses for nsims studies, and stores all the results needed to examine bias detection. In the first section of the script, statistically significant results in the desired direction are simulated, and in the second part null results are generated. The script generates a percentage of significant results as indicated by pub.bias - when set to 1, all results are significant. In the code below, pub.bias is set to 0.05. Because there is no true effect in the simulation (m1 and m2 are equal, so there is no difference between the groups), the only significant results that should be expected are the 5% false positives. Finally, the meta-analysis is performed, the results are printed, and a funnel plot is created.
If you prefer not to use R, you can use the interactive simulation below to explore the effects of publication bias in meta-analyses. The simulation allows you to apply the trim-and-fill method, PET-PEESE metaregression, and Rücker’s Limit Meta-Analysis (for an explanation of this method, see Doing Meta-Analysis in R).
library(metafor)
library(truncnorm)
nsims <- 100 # number of simulated experiments
pub.bias <- 0.05 # proportion of significant results in the literature
m1 <- 0; sd1 <- 1 # too large effects make non-significant results extremely rare
m2 <- 0; sd2 <- 1
n_sig <- round(nsims * pub.bias)
n_nonsig <- nsims - n_sig
# Pre-allocate a results data frame with n rows
make_meta_df <- function(n) {
data.frame(m1 = numeric(n), m2 = numeric(n), sd1 = numeric(n), sd2 = numeric(n),
n1 = integer(n), n2 = integer(n), pvalues = numeric(n),
pcurve = character(n), stringsAsFactors = FALSE)
}
# Simulate significant results: one-sided p < 0.025 in the expected direction
sim_sig <- function(n_sig) {
if (n_sig == 0) return(make_meta_df(0))
out <- make_meta_df(n_sig)
for (i in seq_len(n_sig)) {
n <- round(rtruncnorm(1, a = 20, b = 1000, mean = 100, sd = 100))
p <- 1
while (p > 0.025) {
x <- rnorm(n, mean = m1, sd = sd1)
y <- rnorm(n, mean = m2, sd = sd2)
p <- t.test(x, y, alternative = "greater", var.equal = TRUE)$p.value
}
res <- t.test(x, y, var.equal = TRUE)
out[i, ] <- list(mean(x), mean(y), sd(x), sd(y), n, n, res$p.value,
paste0("t(", res$parameter, ")=", res$statistic))
}
out
}
# Simulate non-significant results: two-sided p >= 0.05
sim_nonsig <- function(n_nonsig) {
if (n_nonsig == 0) return(make_meta_df(0))
out <- make_meta_df(n_nonsig)
for (i in seq_len(n_nonsig)) {
n <- round(rtruncnorm(1, a = 20, b = 1000, mean = 100, sd = 100))
p <- 0
while (p < 0.05) {
x <- rnorm(n, mean = m1, sd = sd1)
y <- rnorm(n, mean = m2, sd = sd2)
p <- t.test(x, y, var.equal = TRUE)$p.value
}
res <- t.test(x, y, var.equal = TRUE)
out[i, ] <- list(mean(x), mean(y), sd(x), sd(y), n, n, res$p.value,
paste0("t(", res$parameter, ")=", res$statistic))
}
out
}
metadata <- rbind(sim_sig(n_sig), sim_nonsig(n_nonsig))
metadata <- escalc(n1i = n1, n2i = n2, m1i = m1, m2i = m2, sd1i = sd1,
sd2i = sd2, measure = "SMD", data = metadata)
metadata$sei <- sqrt(metadata$vi)
result <- rma(yi, vi, data = metadata)
result
funnel(result, level = 0.95, refline = 0)
abline(v = result$b[1], lty = "dashed")
points(x = result$b[1], y = 0, cex = 1.5, pch = 17)Let’s start by looking at what unbiased research looks like, by running the code, keeping pub.bias at 0.05, such that only 5% Type 1 errors enter the scientific literature.
Random-Effects Model (k = 100; tau^2 estimator: REML)
tau^2 (estimated amount of total heterogeneity): 0 (SE = 0.0017)
tau (square root of estimated tau^2 value): 0
I^2 (total heterogeneity / total variability): 0.00%
H^2 (total variability / sampling variability): 1.00
Test for Heterogeneity:
Q(df = 99) = 78.6984, p-val = 0.9341
Model Results:
estimate se zval pval ci.lb ci.ub
0.0261 0.0115 2.2741 0.0230 0.0036 0.0486 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1When we examine the results of the meta-analysis we see there are 100 studies in the meta-analysis (k = 100), and there is no statistically significant heterogeneity (p = 0.93, which is not too surprising, as we programmed the simulation to have a true effect size of 0, and there is no heterogeneity in effect sizes). We also get the results for the meta-analysis. The meta-analytic estimate is d = 0.026, which is very close to 0 (as it should be, because the true effect size is indeed 0). The standard error around this estimate is 0.011. With 100 studies, we have a very accurate estimate of the true effect size. The Z-value for the test against d = 0 is 2.274, and the p-value for this test is 0.02. We cannot reject the hypothesis that the true effect size is 0. The CI around the effect size estimate (0.004, 0.049) includes 0.
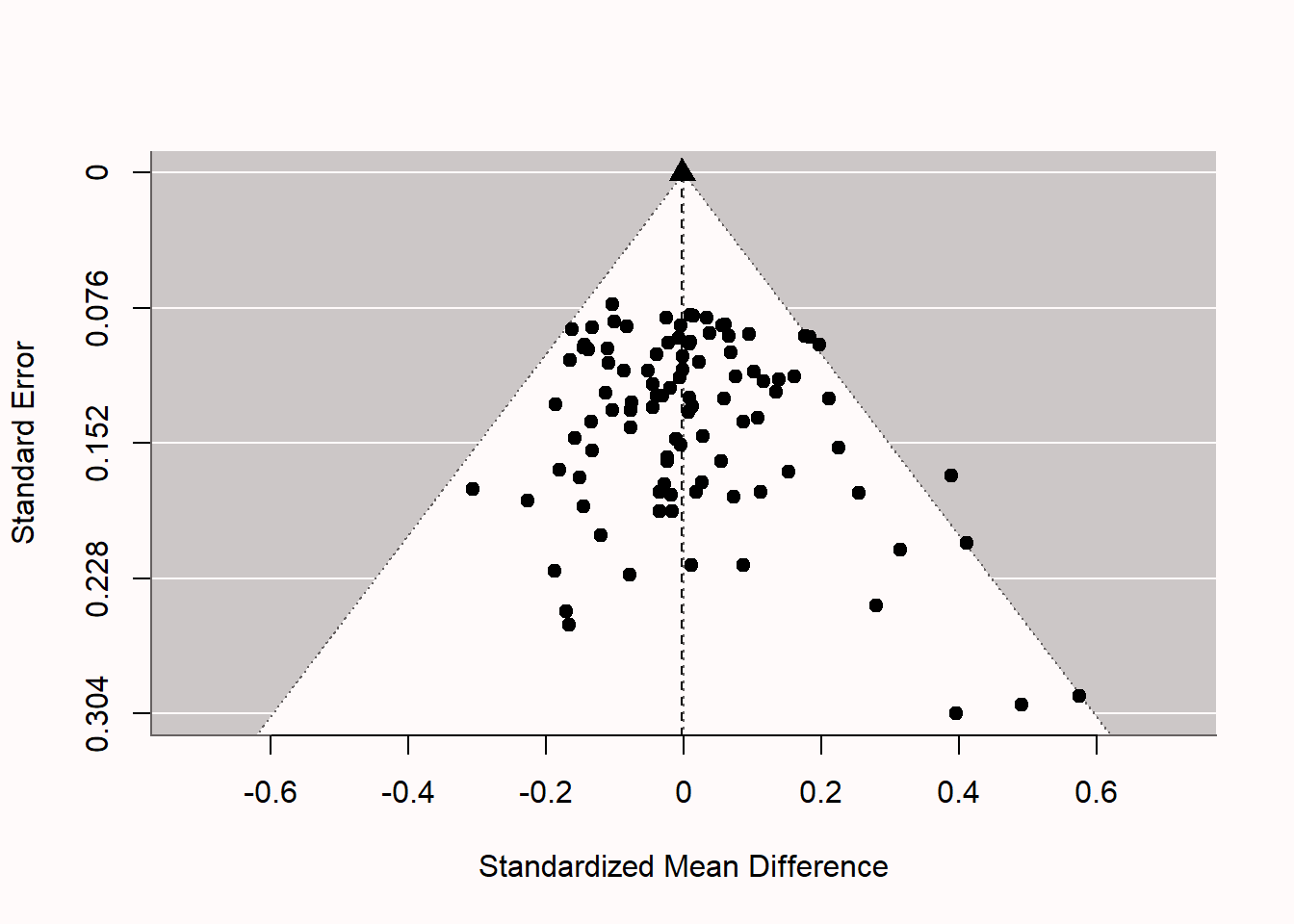
If we examine the funnel plot in Figure 12.5 we see each study represented as a dot. The larger the sample size, the higher up in the plot, and the smaller the sample size, the lower in the plot. The white pyramid represents the area within which a study is not statistically significant, because the observed effect size (x-axis) is not far enough removed from 0 such that the confidence interval around the observed effect size would exclude 0. The lower the standard error, the more narrow the confidence interval, and the smaller the effect sizes needs to be in order to be statistically significant. At the same time, the smaller the standard error, the closer the effect size will be to the true effect size, so the less likely we will see effects far away from 0. We should expect 95% of the effect size estimates to fall within the funnel, if it is centered on the true effect size. We see only a few studies (five, to be exact) fall outside the white pyramid on the right side of the plot. These are the 5% significant results that we programmed in the simulation. Note that all 5 of these studies are false positives, as there is no true effect. If there was a true effect (you can re-run the simulation and set d to 0.5 by changing m1 <- 0 in the simulation to m1 <- 0.5) the pyramid cloud of points would move to the right, and be centered on 0.5 instead of 0.
We can now compare the unbiased meta-analysis above with a biased meta-analysis. We can simulate a situation with extreme publication bias. Building on the estimate by Scheel et al. (2021), let’s assume 96% of the studies show positive results. We set pub.bias <- 0.96 in the code. We keep both means at 0, so there still is not real effect, but we will end up with mainly Type 1 errors in the predicted direction in the final set of studies. After simulating biased results, we can perform the meta-analysis to see if the statistical inference based on the meta-analysis is misleading.
Random-Effects Model (k = 100; tau^2 estimator: REML)
tau^2 (estimated amount of total heterogeneity): 0 (SE = 0.0019)
tau (square root of estimated tau^2 value): 0
I^2 (total heterogeneity / total variability): 0.00%
H^2 (total variability / sampling variability): 1.00
Test for Heterogeneity:
Q(df = 99) = 77.0649, p-val = 0.9498
Model Results:
estimate se zval pval ci.lb ci.ub
0.2667 0.0123 21.6780 <.0001 0.2426 0.2908 ***
---
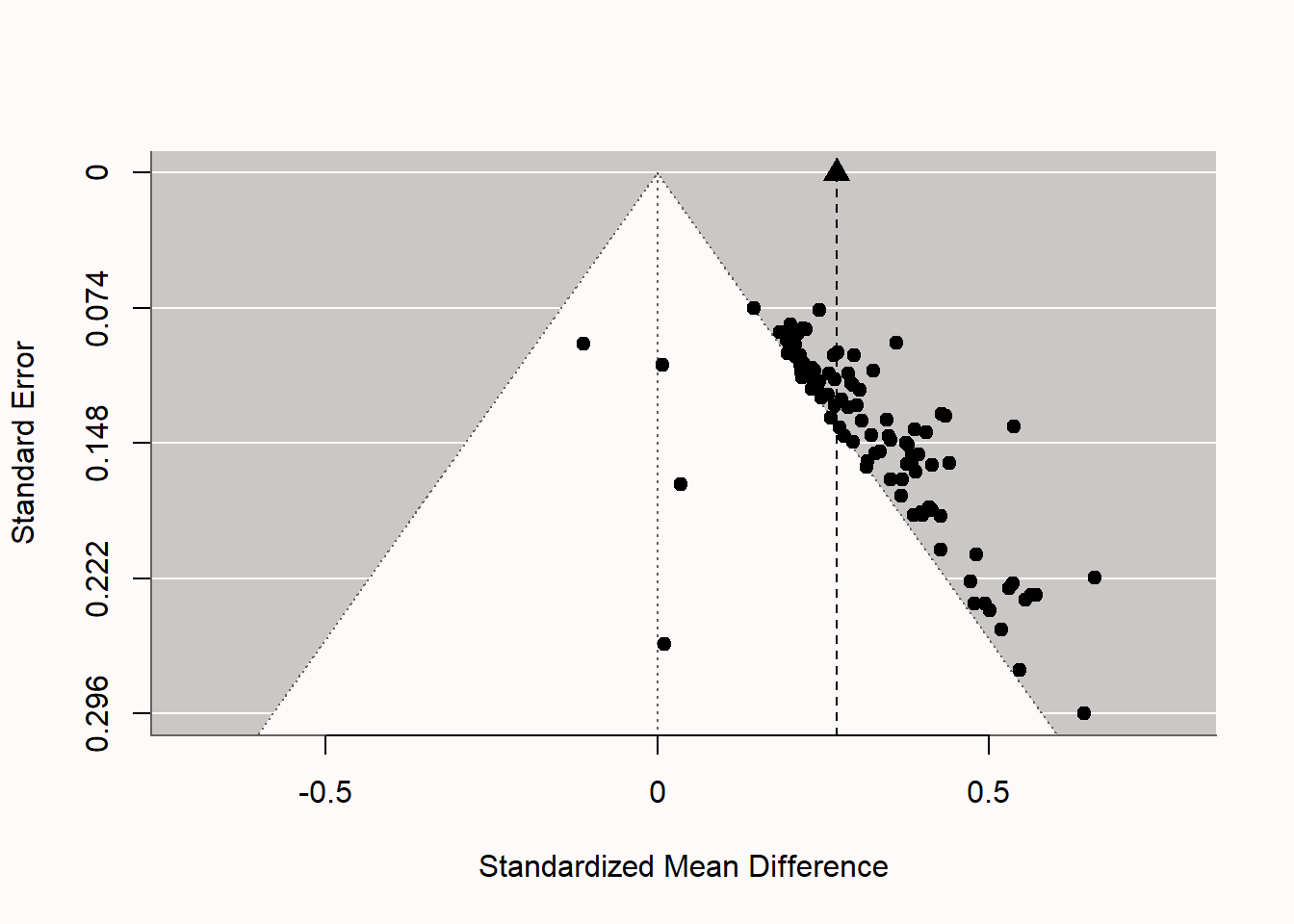
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The biased nature of the set of studies we have analyzed becomes clear if we examine the funnel plot in fig-funnel2. The pattern is quite peculiar. We see four unbiased null results, as we programmed into the simulation, but the remainder of the 96 studies are statistically significant, even though the null is true. We see most studies fall just on the edge of the white pyramid. Because p-values are uniformly distributed under the null, the Type 1 errors we observe often have p-values in the range of 0.02 to 0.05, unlike what we would expect if there was a true effect. These just significant p-values fall just outside of the white pyramid. The larger the study, the smaller the effect size that is significant. The fact that the effect sizes do not vary around a single true effect size (e.g., d = 0 or d = 0.5), but rather effect sizes become smaller with larger sample sizes (or smaller standard errors), is a strong indicator of bias. The vertical dotted line and black triangle at the top of the plot illustrate the observed (upwardly biased) meta-analytic effect size estimate.
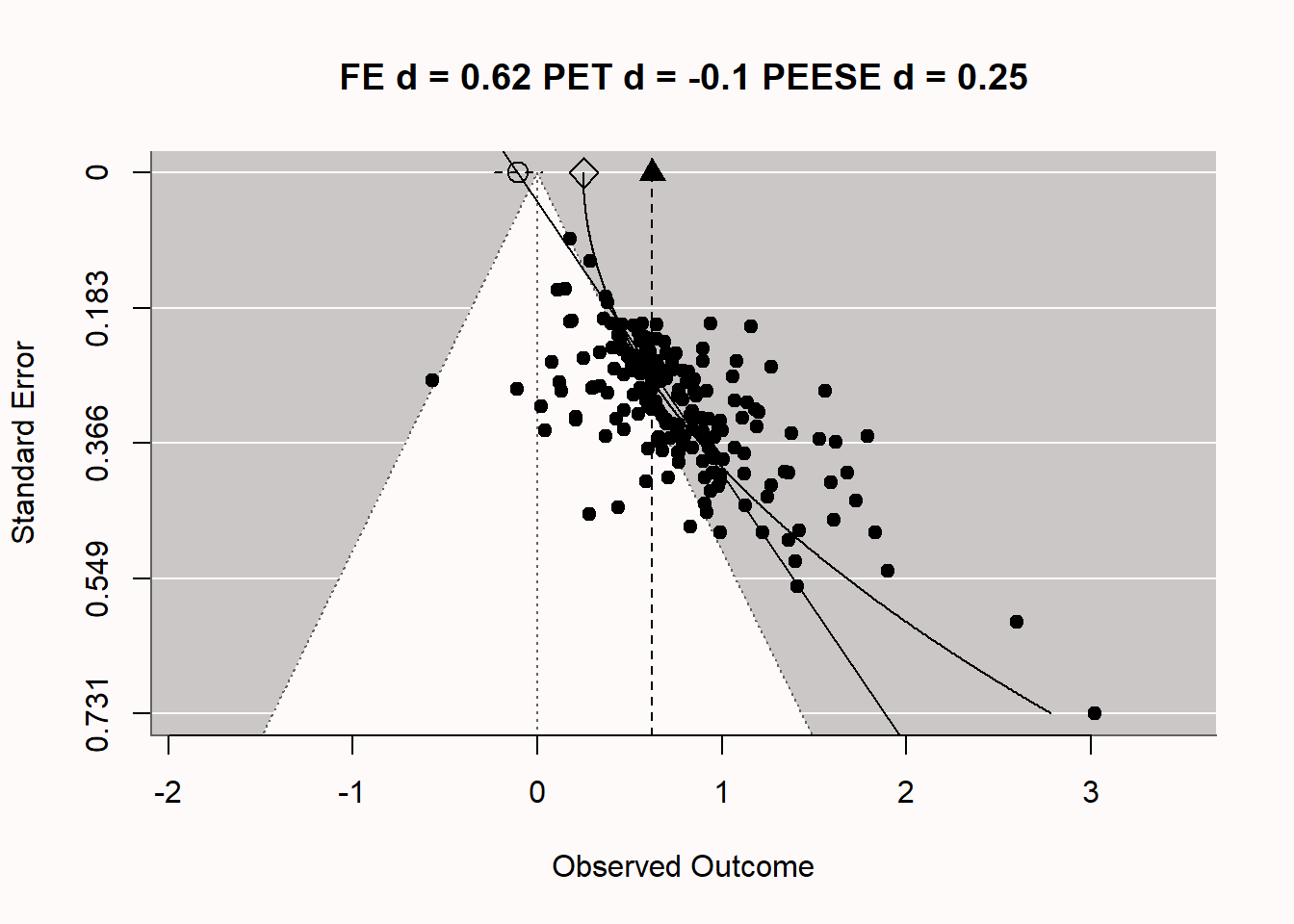
One might wonder if such extreme bias ever really emerges in scientific research. It does. In Figure 12.7 we see a funnel plot by Carter & McCullough (2014) who examined bias in 198 published studies testing the ‘ego-depletion’ effect, the idea that self-control relies on a limited resource. Using bias detecting techniques such as PET-PEESE meta-regression they concluded based on the unbiased effect size estimated by PET (d = -0.1, which did not differ statistically from 0) that the true unbiased effect size might be d = 0, even though the meta-analytic effect size estimate without correcting for bias was d = 0.62. Do you notice any similarities to the extremely biased meta-analysis we simulated above? You might not be surprised that, even though before 2015 researchers thought there was a large and reliable literature demonstrating ego-depletion effects, a Registered Replication report yielded a non-significant effect size estimate (Hagger et al., 2016), and even when the original researchers tried to replicate their own work, they failed to observe a significant effect of ego-depletion (Vohs et al., 2021). Imagine the huge amount of wasted time, effort, and money on a literature that was completely based on bias in scientific research. Obviously, such research waste has ethical implications, and researchers need to take responsibility for preventing such waste in the future.
We can also see signs of bias in the forest plot for a meta-analysis. In Figure 12.8, two forest plots are plotted side by side. The left forest plot is based on unbiased data, the right forest plot is based on biased data. The forest plots are a bit big with 100 studies, but we see that in the left forest plot, the effects randomly vary around 0 as they should. On the right, beyond the first four studies, all confidence intervals magically just exclude an effect of 0.

When there is publication bias because researchers only publish statistically significant results (p < \(\alpha\)), and you calculate the effect size in a meta-analysis, the meta-analytic effect size estimate is higher when there is publication bias (where researchers publish only effects with p < \(\alpha\)) compared to when there is no publication bias. This is because publication bias filters out the smaller (non-significant) effect sizes. which are then not included in the computation of the meta-analytic effect size. This leads to a meta-analytic effect size estimate that is larger than the true population effect size. With strong publication bias, we know the meta-analytic effect size is inflated, but we don’t know by how much. The true effect size could just be a bit smaller, but the true effect size could also be 0, such as in the case of the ego-depletion literature.
12.3 Trim and Fill
Trim and fill is a technique that aims to augment a dataset by adding hypothetical ‘missing’ studies (that may be in the ‘file-drawer’). The procedure starts by removing (‘trimming’) small studies that bias the meta-analytic effect size, then estimates the true effect size, and ends with ‘filling’ in a funnel plot with studies that are assumed to be missing due to publication bias. In the Figure 12.9, you can see the same funnel plot as above, but now with added hypothetical studies (the unfilled circles which represent ‘imputed’ studies). If you look closely, you’ll see these points each have a mirror image on the opposite side of the meta-analytic effect size estimate (this is clearest in the lower half of the funnel plot). If we examine the result of the meta-analysis that includes these imputed studies, we see that trim and fill successfully alerts us to the fact that the meta-analysis is biased (if not, it would not add imputed studies) but it fails miserably in correcting the effect size estimate. In the funnel plot, we see the original (biased) effect size estimate indicated by the triangle, and the meta-analytic effect size estimate adjusted with the trim-and-fill method (indicated by the black circle). We see the meta-analytic effect size estimate is a bit lower, but given that the true effect size in the simulation was 0, the adjustment is clearly not sufficient.
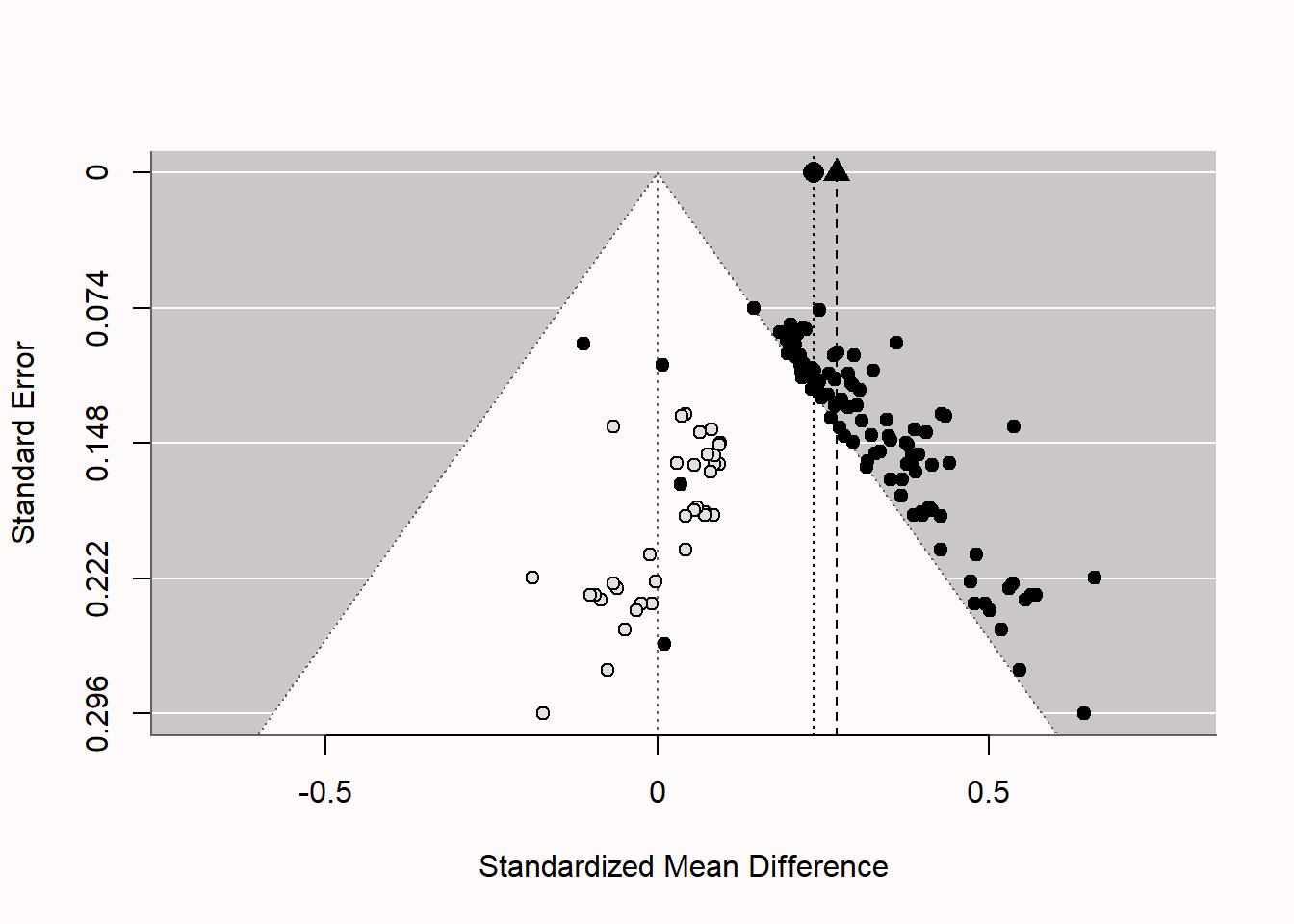
Trim-and-fill is not very good under many realistic publication bias scenarios. The method is criticized for its reliance on the strong assumption of symmetry in the funnel plot. When publication bias is based on the p-value of the study (arguably the most important source of publication bias in many fields) the trim-and-fill method does not perform well enough to yield a corrected meta-analytic effect size estimate that is close to the true effect size (Peters et al., 2007; Terrin et al., 2003). When the assumptions are met, it can be used as a sensitivity analysis. Researchers should not report the trim-and-fill corrected effect size estimate as a realistic estimate of the unbiased effect size. If other bias-detection tests (like p-curve or z-curve discussed below) have already indicated the presence of bias, the trim-and-fill procedure might not provide additional insights.
12.4 PET-PEESE
A novel class of solutions to publication bias is meta-regression. Instead of plotting a line through individual data-points, in meta-regression a line is plotted through data points that each represent a study. As with normal regression, the more data meta-regression is based on, the more precise the estimate is and, therefore, the more studies in a meta-analysis, the better meta-regression will work in practice. If the number of studies is small, all bias detection tests lose power, and this is something that one should keep in mind when using meta-regression. Furthermore, regression requires sufficient variation in the data, which in the case of meta-regression means a wide range of sample sizes (recommendations indicate meta-regression performs well if studies have a range from 15 to 200 participants in each group – which is not typical for most research areas in psychology). Meta-regression techniques try to estimate the population effect size if precision was perfect (so when the standard error = 0).
One meta-regression technique is known as PET-PEESE (Stanley et al., 2017; Stanley & Doucouliagos, 2014). It consists of a ‘precision-effect-test’ (PET) which can be used in a Neyman-Pearson hypothesis testing framework to test whether the meta-regression estimate can reject an effect size of 0 based on the 95% CI around the PET estimate at the intercept SE = 0. Note that when the confidence interval is very wide due to a small number of observations, this test might have low power, and have an a-priori low probability of rejecting the null effect. The estimated effect size for PET is calculated with: \(d = \beta_0 + \beta_1 SE_i + u_i\) where d is the estimated effect size, SE is the standard error, and the equation is estimated using weighted least squares (WLS), with 1/SE2i as the weights. The PET estimate underestimates the effect size when there is a true effect. Therefore, the PET-PEESE procedure recommends first using PET to test whether the null can be rejected, and if so, then the ‘precision-effect estimate with standard error’ (PEESE) should be used to estimate the meta-analytic effect size. In PEESE, the standard error (used in PET) is replaced by the variance (i.e., the standard error squared), which Stanley & Doucouliagos (2014) find reduces the bias of the estimated meta-regression intercept.
PET-PEESE has limitations, as all bias detection techniques have. The biggest limitations are that it does not work well when there are few studies, all the studies in a meta-analysis have small sample sizes, or when there is large heterogeneity in the meta-analysis (Stanley et al., 2017). When these situations apply (and they will in practice), PET-PEESE might not be a good approach. Furthermore, there are some situations where there might be a correlation between sample size and precision, which in practice will often be linked to heterogeneity in the effect sizes included in a meta-analysis. For example, if true effects are different across studies, and people perform power analyses with accurate information about the expected true effect size, large effect sizes in a meta-analysis will have small sample sizes, and small effects will have large sample sizes. Meta-regression is, like normal regression, a way to test for an association, but you need to think about the causal mechanism behind the association.
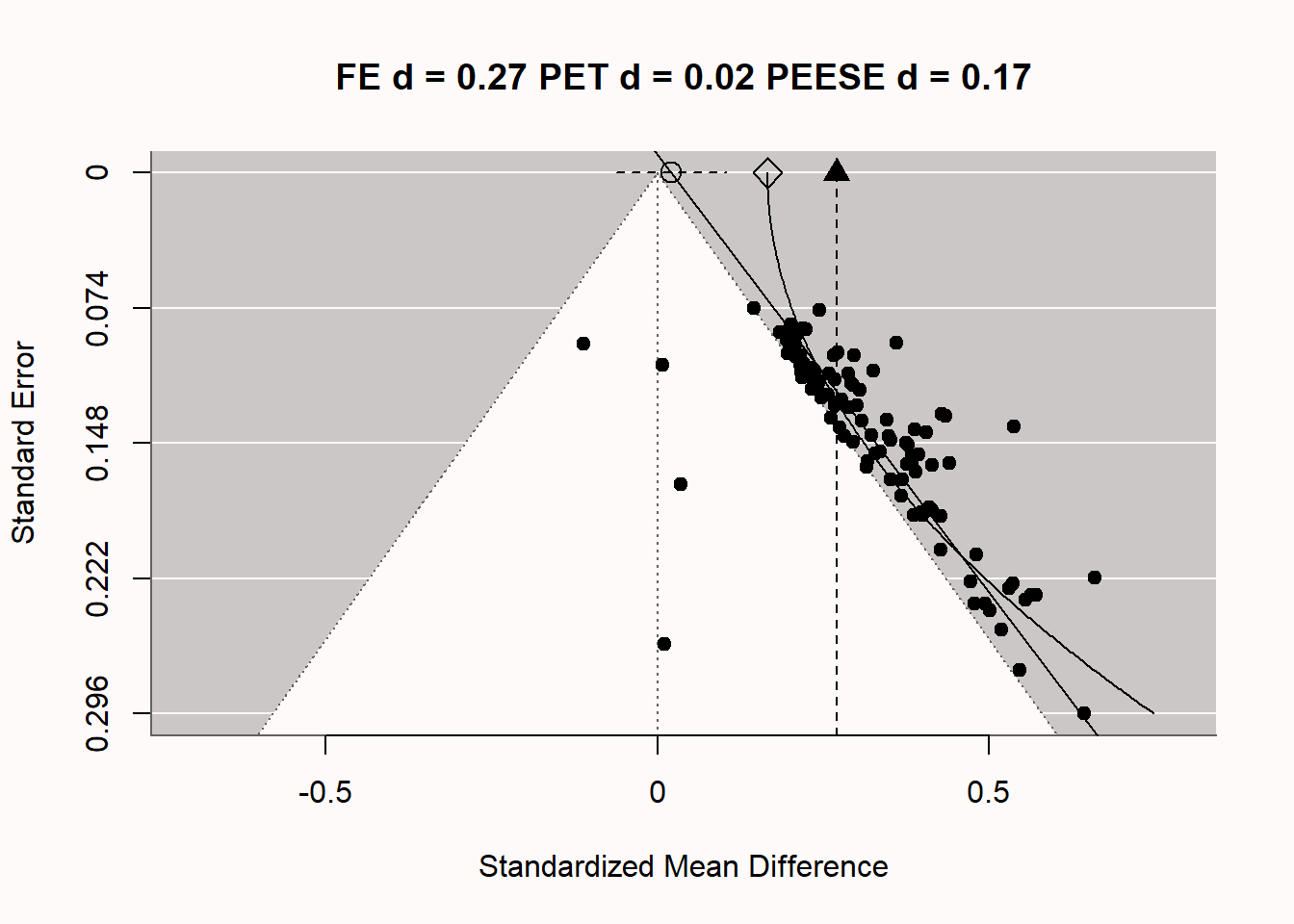
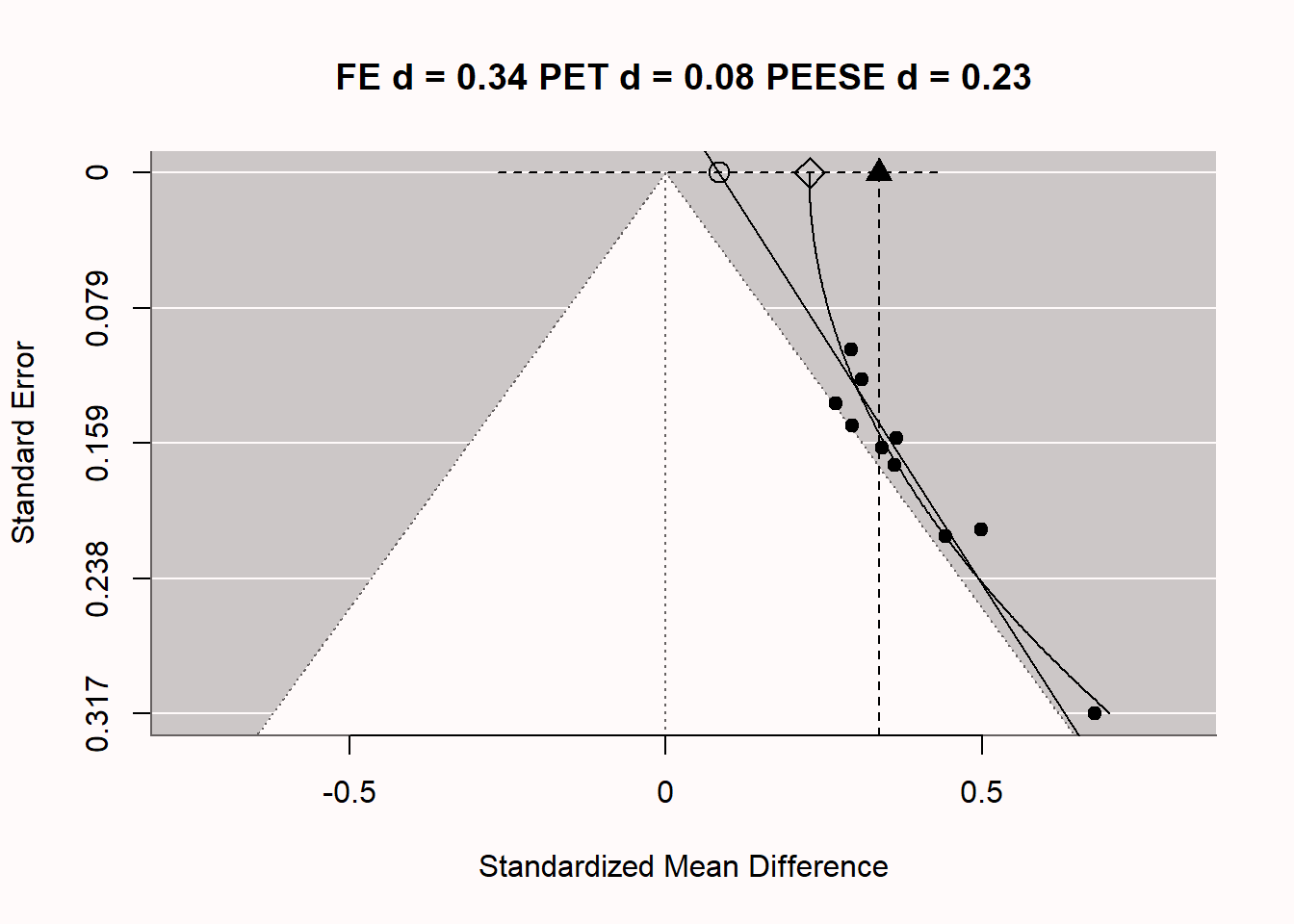
Let’s explore how PET-PEESE meta-regression attempts to give us an unbiased effect size estimate, under specific assumptions of how publication bias is caused. In we once again see the funnel plot, now complemented with 2 additional lines through the plots. The vertical line at d = 0.27 is the meta-analytic effect size estimate, which is upwardly biased because we are averaging over statistically significant studies only. There are 2 additional lines, which are the meta-regression lines for PET-PEESE based on the formulas detailed previously. The straight diagonal line gives us the PET estimate at a SE of 0 (an infinite sample, at the top of the plot), indicated by the circle. The dotted line around this PET estimate is the 95% confidence interval for the estimate. In this case, the 95% CI contains 0, which means that based on the PET estimate of d = 0.02, we cannot reject a meta-analytic effect size of 0. Note that even with 100 studies, the 95% CI is quite wide. Meta-regression is, just like normal regression, only as accurate as the data we have. This is one limitation of PET-PEESE meta-regression: With small numbers of studies in the meta-analysis, it has low accuracy. If we had been able to reject the null based on the PET estimate, we would then have used the PEESE estimate (indicated by the diamond shape) of d = 0.17 for the meta-analytic effect size, corrected for bias (while never knowing whether the model underlying the PEESE estimate corresponded to the true bias generating mechanisms in the meta-analysis, and thus if the meta-analytic estimate was accurate).
12.5 P-value meta-analysis
In addition to a meta-analysis of effect sizes, it is possible to perform a meta-analysis of p-values. The first of such approaches is known as the Fisher’s combined probability test, and more recent bias detection tests such as p-curve analysis (Simonsohn et al., 2014) and p-uniform* (Aert & Assen, 2018) build on this idea. These two techniques are an example of selection model approaches to test and adjust for meta-analysis (Iyengar & Greenhouse, 1988), where a model about the data generating process of the effect sizes is combined with a selection model of how publication bias impacts which effect sizes become part of the scientific literature. An example of a data generating process would be that results of studies are generated by statistical tests where all test assumptions are met, and the studies have some average power. A selection model might be that all studies are published, as long as they are statistically significant at an alpha level of 0.05.
P-curve analysis uses exactly this selection model. It assumes all significant results are published, and examines whether the data generating process mirrors what would be expected if the studies have a certain power, or whether the data generating process mirrors the pattern expected if the null hypothesis is true. As discussed in the section on which p-values you can expect, for continuously distributed test statistics (e.g., t-values, F-values, Z-scores) we should observe uniformly distributed p-values when the null hypothesis is true, and more small significant p-values (e.g., 0.01) than large significant p-values (e.g., 0.04) when the alternative hypothesis is true. P-curve analysis performs two tests. In the first test, p-curve analysis examines whether the p-value distribution is flatter than what would be expected if the studies you analyze had 33% power. This value is somewhat arbitrary (and can be adjusted), but the idea is to reject at the smallest level of statistical power that would lead to useful insights about the presence of effects. If the average power in the set of studies is less than 33%, there might be an effect, but the studies are not designed well enough to learn about it by performing statistical tests. If we can reject the presence of a pattern of p-values that has at least 33% power, this suggests the distribution looks more like one expected when the null hypothesis is true. That is, we would doubt there is an effect in the set of studies included in the meta-analysis, even though all individual studies were statistically significant.
The second test examines whether the p-value distribution is sufficiently right-skewed (more small significant p-values than large significant p-values), such that the pattern suggests we can reject a uniform p-value distribution. If we can reject a uniform p-value distribution, this suggests the studies might have examined a true effect and had at least some power. If the second test is significant, we would act as if the set of studies examines some true effect, even though there might be publication bias. As an example, let’s consider Figure 3 from Simonsohn and colleagues (2014). The authors compared 20 papers in the Journal of Personality and Social Psychology that used a covariate in the analysis, and 20 studies that did not use a covariate. The authors suspected that researchers might add a covariate in their analyses to try to find a p-value smaller than 0.05, when the first analysis they tried did not yield a significant effect.
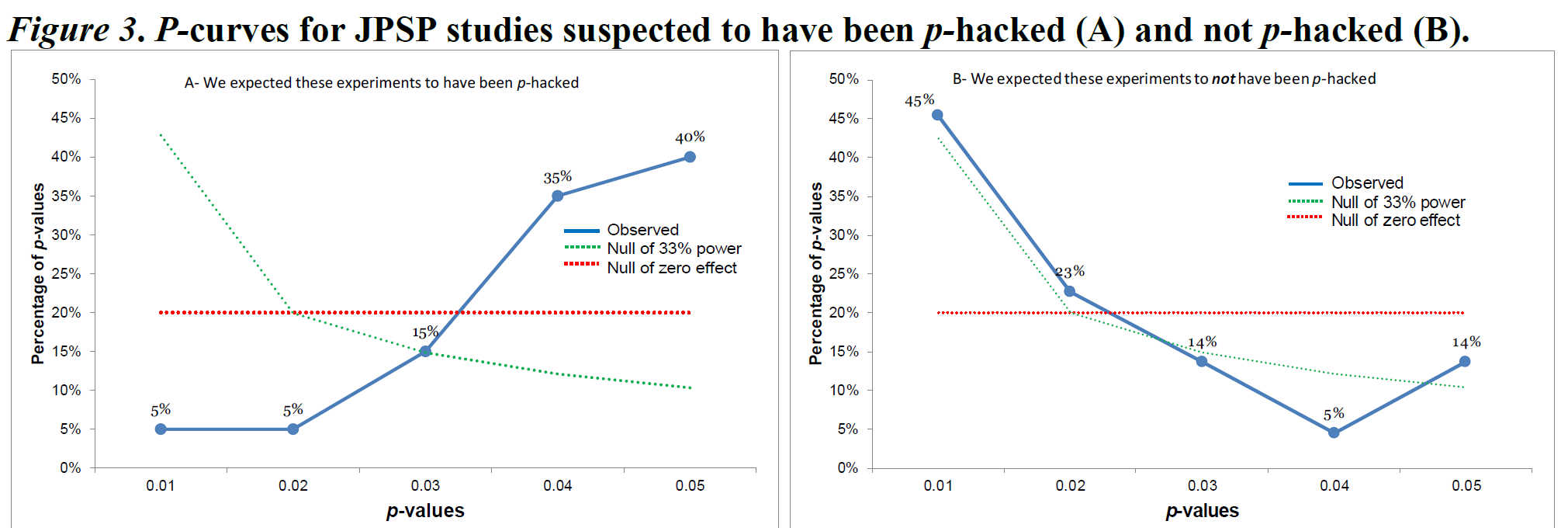
The p-curve distribution of the observed p-values is represented by five points in the blue line. P-curve analysis is performed only on statistically significant results, based on the assumption that these are always published, and thus that this part of the p-value distribution contains all studies that were performed. The 5 points illustrate the percentage of p-values between 0 and 0.01, 0.01 and 0.02, 0.02 and 0.03, 0.03 and 0.04, and 0.04 and 0.05. In the figure on the right, you see a relatively normal right-skewed p-value distribution, with more low than high p-values. The p-curve analysis shows that the blue line in the right figure is more right-skewed than the uniform red line (where the red line is the uniform p-value distribution expected if there was no effect). Simonsohn and colleagues summarize this pattern as an indication that the set of studies has ‘evidential value’, but this terminology is somewhat misleading. The formally correct interpretation is that we can reject a p-value distribution as expected when the null hypothesis was true in all studies included in the p-curve analysis. Rejecting a uniform p-value distribution does not automatically mean there is evidence for the theorized effect (e.g., the pattern could be caused by a mix of null effects and a small subset of studies that show an effect due to a methodological confound).
In the left figure we see the opposite pattern, with mainly high p-values around 0.05, and almost no p-values around 0.01. Because the blue line is significantly flatter than the green line, the p-curve analysis suggests this set of studies is the result of selection bias and was not generated by a set of sufficiently powered studies. P-curve analysis is a useful tool. But it is important to correctly interpret what a p-curve analysis can tell you. A right-skewed p-curve does not prove that there is no bias, or that the theoretical hypothesis is true. A flat p-curve does not prove that the theory is incorrect, but it does show that the studies that were meta-analyzed look more like the pattern that would be expected if the null hypothesis was true, and there was selection bias.
The script stores all the test statistics for the 100 simulated t-tests that are included in the meta-analysis. The first few rows look like:
t(474)=2.30794625430861
t(188)=2.43353676652346
t(342)=2.07773199578041
t(332)=2.64122275042659
t(286)=1.98027001553441Print all test results with cat(metadata$pcurve, sep = "\n"), and go to the online p-curve app at http://www.p-curve.com/app4/. Paste all the test results, and click the ‘Make the p-curve’ button. Note that the p-curve app will only yield a result when there are p-values smaller than 0.05 - if all test statistics yield a p > 0.05, the p-curve cannot be computed, as these tests are ignored.
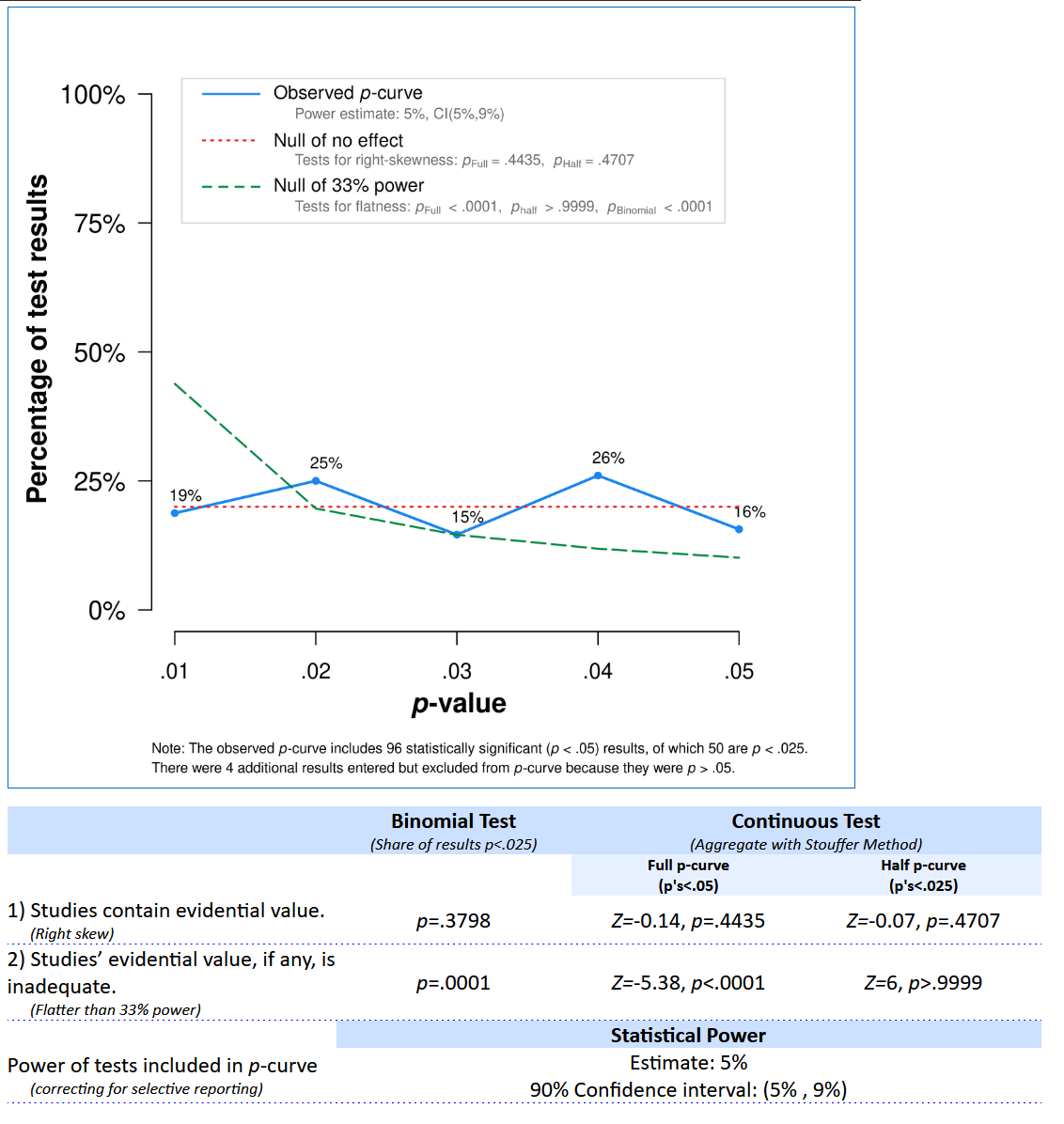
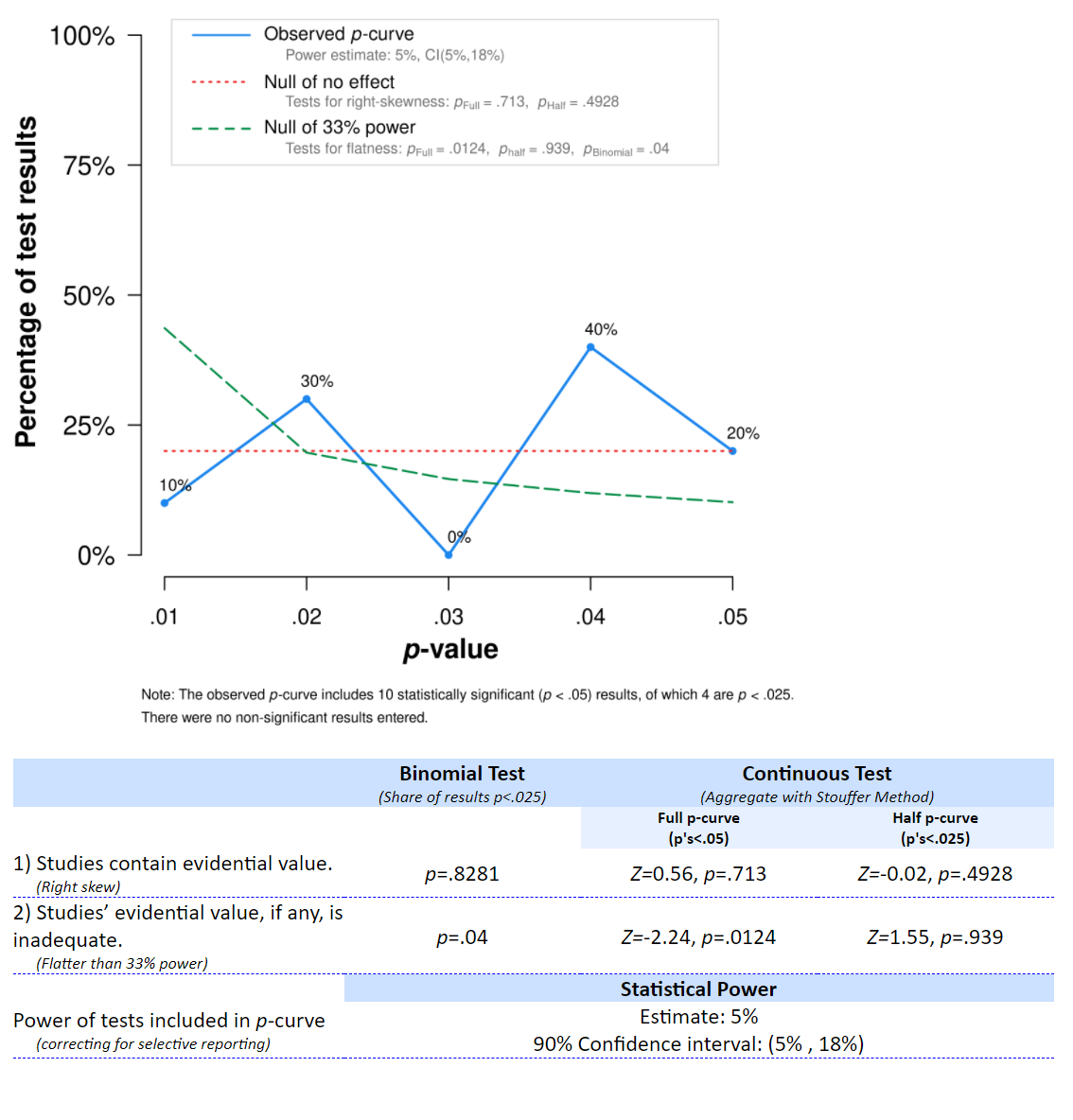
The distribution of p-values clearly looks like it comes from a uniform distribution (as it indeed does), and the statistical test indicates we can reject a p-value distribution as steep or steeper as would be generated by a set of studies with 33% power, p < 0.0001. The app also provides an estimate of the average power of the tests that generated the observed p-value distribution, 5%, which is indeed correct. Therefore, we can conclude these studies, even though many effects are statistically significant, are more in line with selective reporting of Type 1 errors, than with a p-value distribution that should be expected if there was a true effect that was studied with sufficient statistical power. The theory might still be true, but the set of studies we have analyzed here do not provide support for the theory.
A similar meta-analytic technique is p-uniform*. This technique is similar to p-curve analysis and selection bias models, but it uses the results both from significant and non-significant studies, and can be used to estimate a bias-adjusted meta-analytic effect size estimate. The technique uses a random-effects model to estimate the effect sizes for each study, and weighs them based on a selection model that assumes significant results are more likely to be published than non-significant results. Below, we see the output of the p-uniform* which estimates the bias-corrected effect size to be d = 0.0126. This effect size is not statistically different from 0, p = 0.3857, and therefore this bias detection technique correctly indicates that even though all effects were statistically significant, the set of studies does not provide a good reason to reject a meta-analytic effect size estimate of 0.
puniform::puniform(m1i = metadata$m1, m2i = metadata$m2, n1i = metadata$n1,
n2i = metadata$n2, sd1i = metadata$sd1, sd2i = metadata$sd2, side = "right")
Method: P
Effect size estimation p-uniform
est ci.lb ci.ub L.0 pval ksig
0.0186 -0.0707 0.0913 -0.444 0.3285 96
===
Publication bias test p-uniform
L.pb pval
8.0097 <.001
===
Fixed-effect meta-analysis
est.fe se.fe zval.fe pval.fe ci.lb.fe ci.ub.fe Qstat Qpval
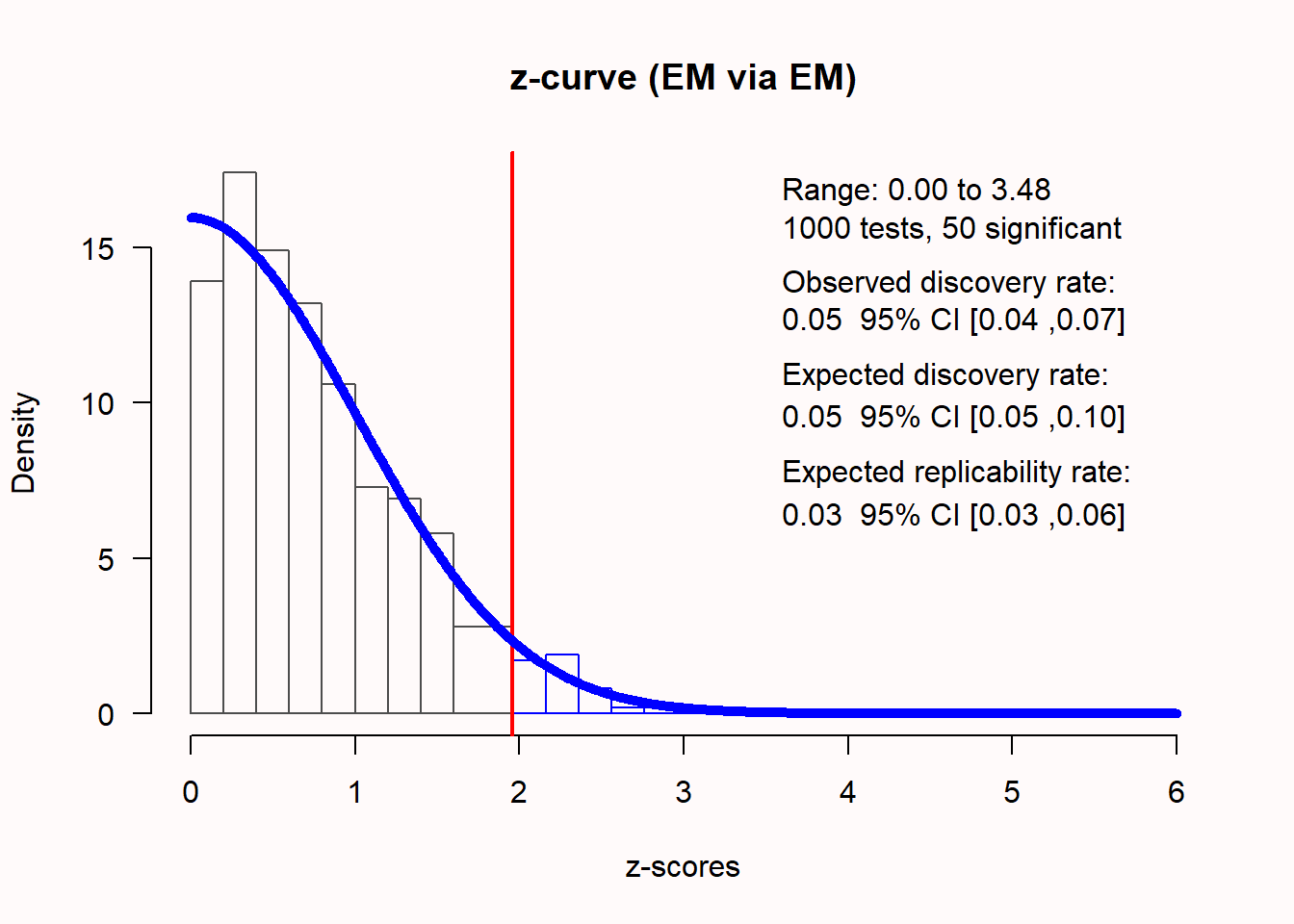
0.2666 0.0123 21.6733 <.001 0.2425 0.2907 77.0162 0.9503An alternative technique that also meta-analyzes the p-values from individual studies is a z-curve analysis, which is a meta-analysis of observed power ((Bartoš & Schimmack, 2020; Brunner & Schimmack, 2020); for an example, see (Sotola, 2022)). Like a traditional meta-analysis, z-curve analysis transforms observed test results (p-values) into z-scores. In an unbiased literature where the null hypothesis is true, we should observe approximately \(\alpha\)% significant results. If the null is true, the distribution of z-scores is centered on 0. Z-curve analysis computes absolute z-values, and therefore \(\alpha\)% of z-scores should be larger than the critical value (1.96 for a 5% alpha level). In Figure 12.13 z-scores for 1000 studies are plotted, with a true effect size of 0, where exactly 5% of the observed results are statistically significant.
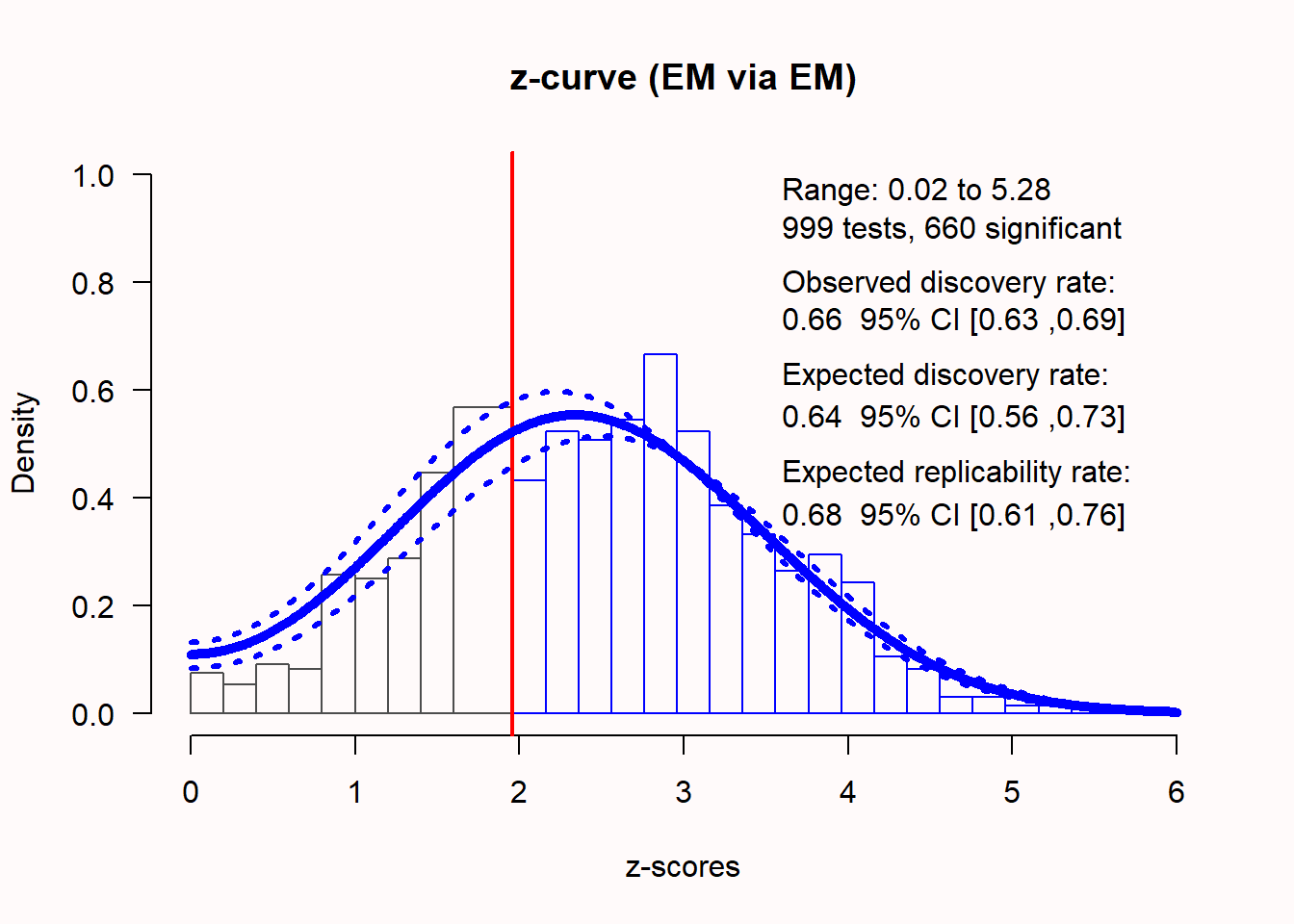
If there is a true effect, the distribution of z-scores shifts away from 0, as a function of the statistical power of the test. The higher the power, the further to the right the distribution of z-scores will be located. For example, when examining an effect with 66% power, an unbiased distribution of z-scores, computed from observed p-values, looks like the distribution in Figure 12.14.
In any meta-analysis the studies that are included will differ in their statistical power, and their true effect size (due to heterogeneity). Z-curve analysis uses mixtures of normal distributions centered at means 0 to 6 to fit a model of the underlying effect sizes that best represents the observed results in the included studies (for the technical details, see Bartoš & Schimmack (2020). The z-curve then aims to estimate the average power of the set of studies, and then calculates the observed discovery rate (ODR: the percentage of significant results, or the observed power), the expected discovery rate (EDR: the proportion of the area under the curve on the right side of the significance criterion) and the expected replication rate (ERR: the expected proportion of successfully replicated significant studies from all significant studies). The z-curve is able to correct for selection bias for positive results (under specific assumptions), and can estimate the EDR and ERR using only the significant p-values.
To examine the presence of bias, it is preferable to submit non-significant and significant p-values to a z-curve analysis, even if only the significant p-values are used to produce estimates. Publication bias can then be examined by comparing the ODR to the EDR. If the percentage of significant results in the set of studies (ODR) is much higher than the expected discovery rate (EDR), this is a sign of bias. If we analyze the same set of biased studies as we used to illustrate the bias detection techniques discussed above, z-curve analysis should be able to indicate the presence of bias. We can perform the z-curve with the following code:
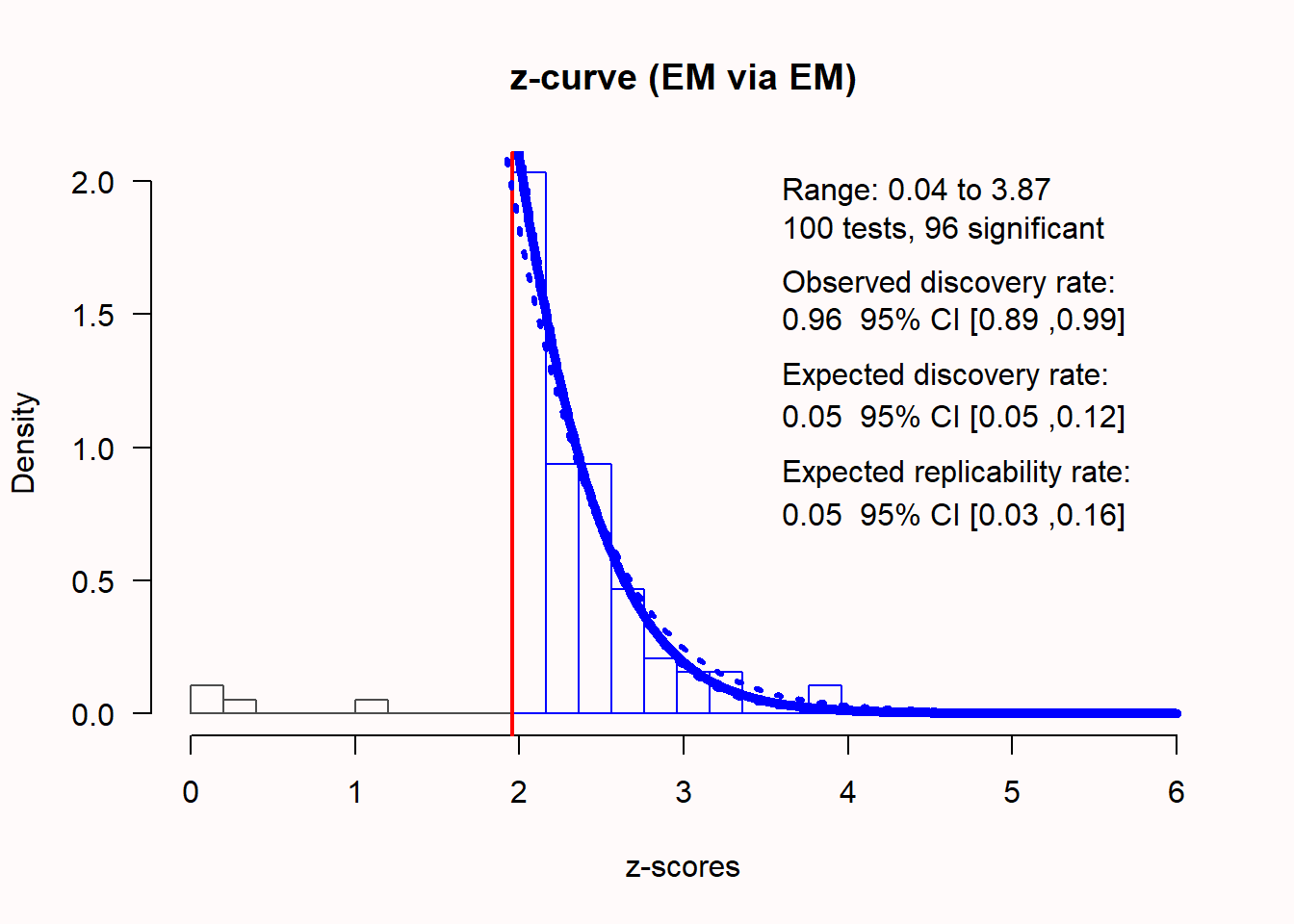
Call:
zcurve::zcurve(p = metadata$pvalues, method = "EM", bootstrap = 1000)
model: EM via EM
Estimate l.CI u.CI
ERR 0.052 0.025 0.160
EDR 0.053 0.050 0.119
Soric FDR 0.947 0.389 1.000
File Drawer R 17.987 7.399 19.000
Expected N 1823 806 1920
Missing N 1723 706 1820
Model converged in 38 + 205 iterations
Fitted using 96 p-values. 100 supplied, 96 significant (ODR = 0.96, 95% CI [0.89, 0.99]).
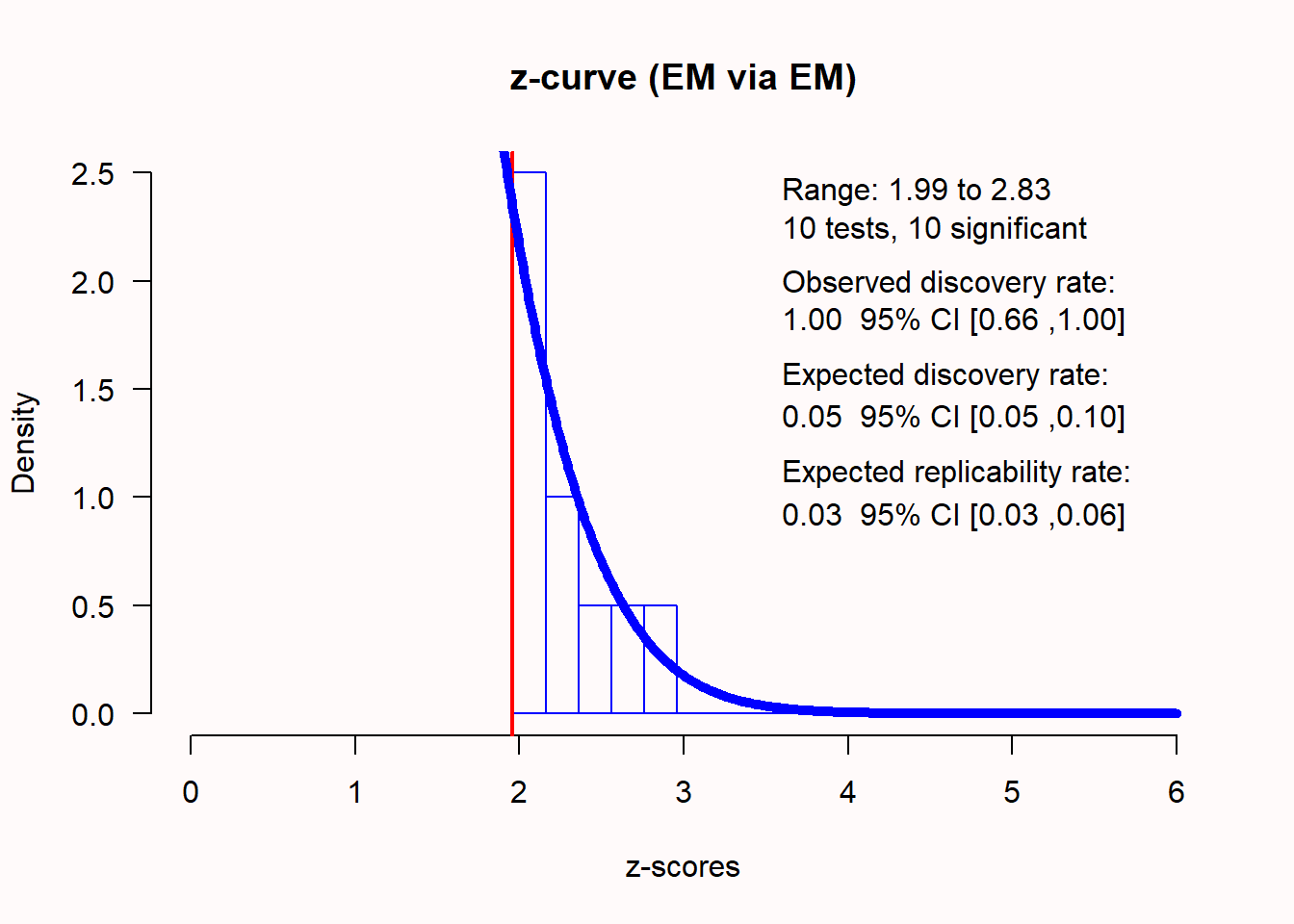
Q = -6.69, 95% CI[-23.63, 11.25]We see that the distribution of z-scores looks peculiar. Most expected z-scores between 0 and 1.96 are missing. 96 out of 100 studies were significant, which makes the observed discovery rate (ODR), or observed power (across all these studies with different sample sizes) 0.96, 95% CI[0.89; 0.99]. The expected discovery rate (EDR) is only 0.053, which differs statistically from the observed discovery rate, as indicated by the fact that the confidence interval of the EDR does not overlap with the ODR of 0.96. This means there is clear indication of selection bias based on the z-curve analysis. The expected replicability rate for these studies is only 0.052, which is in line with the expectation that we will only observe 5% Type 1 errors, as there was no true effect in this simulation. Thus, even though we only entered significant p-values, z-curve analysis correctly suggests that we should not expect these results to replicate at a higher frequency than the Type 1 error rate.
12.6 Conclusion
Publication bias is a big problem in science. It is present in almost all meta-analyses performed on the primary hypothesis test in scientific articles, because these articles are much more likely to be submitted and accepted for publication if the primary hypothesis test is statistically significant. Meta-analytic effect size estimates that are not adjusted for bias will almost always overestimate the true effect size, and bias-adjusted effect sizes might still be misleading. Having messed up the scientific literature through publication bias, there is no way for us to know whether we are computing accurate meta-analytic effect sizes estimates from the literature. Publication bias inflates the effect size estimate to an unknown extent, and there have already have been several cases where the true effect size turned out to be zero. The publication bias tests in this chapter might not provide certainty about the unbiased effect size, but they can function as a red flag to indicate when bias is present, and provide adjusted estimates that, if the underlying model of publication bias is correct, might well be closer to the truth.
There is a lot of activity in the literature on tests for publication bias. There are many different tests, and you need to carefully check the assumptions of each test before applying it. Most tests don’t work well when there is large heterogeneity, and heterogeneity is quite likely. A meta-analysis should always examine whether there is publication bias, preferably using multiple publication bias tests, and therefore it is useful to not just code effect sizes, but also code test statistics or p-values. None of the bias detection techniques discussed in this chapter will be a silver bullet, but they will be better than naively interpreting the uncorrected effect size estimate from the meta-analysis.
For another open educational resource on tests for publication bias, see Doing Meta-Analysis in R.
12.7 Test Yourself
Q1: What happens when there is publication bias because researchers only publish statistically significant results (p < \(\alpha\)), and you calculate the effect size in a meta-analysis?
Q2: The forest plot in the figure below looks quite peculiar. What do you notice?
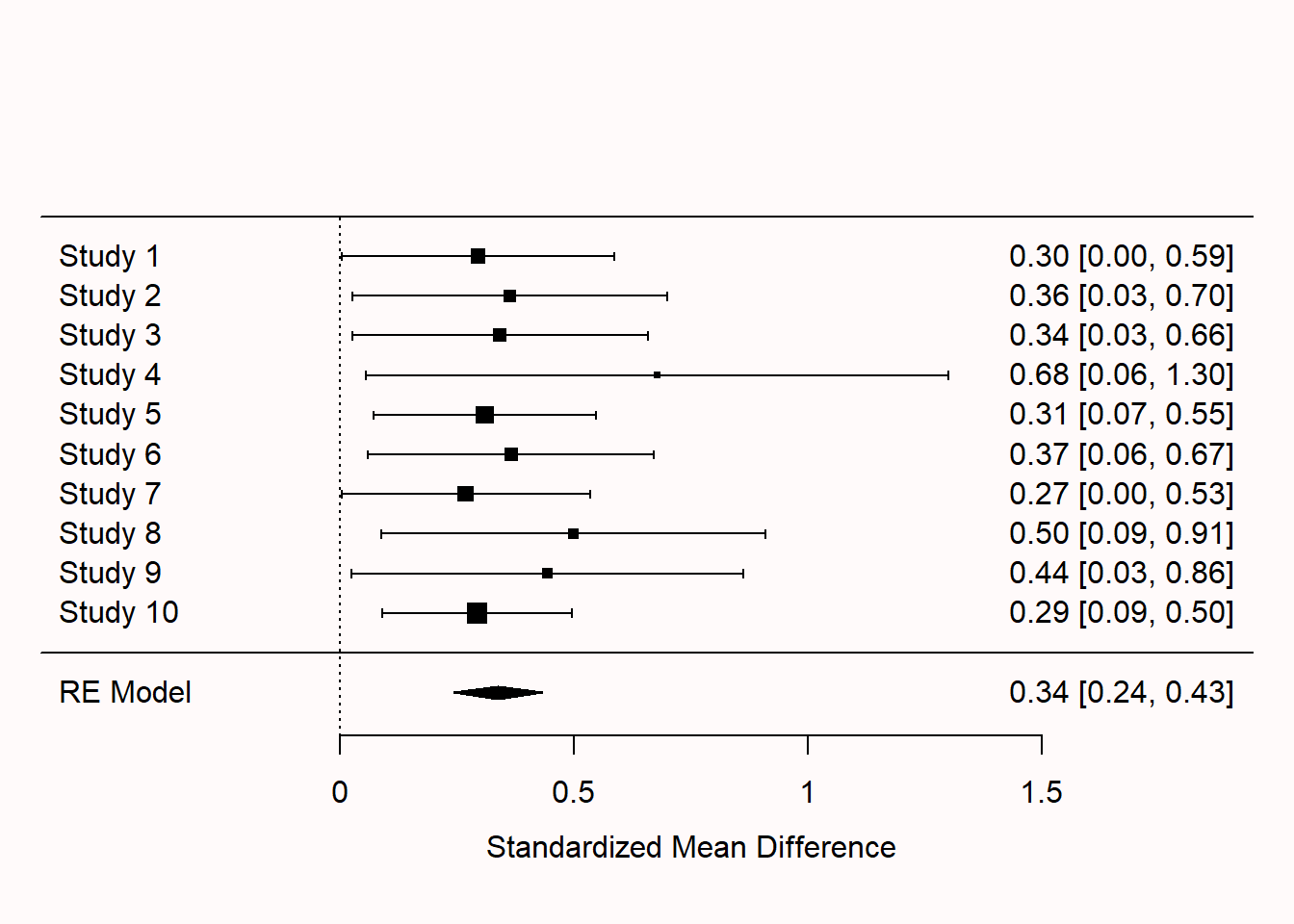
Q3: Which statement is true?
Q4: Which statement is true based on the plot below, visualizing a PET-PEESE meta-regression?
Q5: Take a look at the figure and output table of the p-curve app below, which gives the results for the studies in Q2. Which interpretation of the output is correct?
Q6: The true effect size in the studies simulated in Q2 is 0 - there is no true effect. Which statement about the z-curve analysis below is true?
Q7: We did not yet perform a trim and fill analysis, and given the analyses above (e.g., the z-curve analysis), which statement is true?
Q8: Publication bias is defined as the practice of selectively submitting and publishing scientific research. Throughout this chapter, we have focused on selectively submitting significant results. Can you think of a research line or a research question where researchers might prefer to selectively publish non-significant results?
12.7.1 Open Questions
What is the idea behind the GRIM test?
What is the definition of ‘publication bias’?
What is the file-drawer problem?
In a funnel plot, what is true for studies that fall inside the funnel (when it is centered on 0)?
What is true for the trim-and-fill approach with respect to its ability to detect and correct effect size estimates?
When using the PET-PEESE approach, what is important to consider when the meta-analysis has a small number of studies?
What conclusions can we draw from the 2 tests that are reported in a p-curve analysis?